工程圈流传着一句话:“Cache Rules Everything Around Me”(缓存统治我身边的一切,化用自 Wu-Tang Clan 的经典歌曲 C.R.E.A.M.,把 Cash 换成了 Cache)。这条铁律在智能体(Agent)领域同样成立。
像 Claude Code 这样长时间运行的智能体产品能够走到今天,离不开提示缓存(Prompt Caching)——它能复用先前往返请求(roundtrip)的计算结果,从而大幅降低延迟和成本。
提示缓存是什么?它如何工作?技术上又该怎么实现?可以阅读 @RLanceMartin 关于提示缓存和我们新推出的自动缓存功能的文章了解更多。
在 Claude Code,我们围绕提示缓存构建了整个系统架构。高缓存命中率能降低成本,也让我们得以为订阅用户提供更宽松的速率限制(rate limits),所以我们对命中率设了监控告警,一旦过低就升级为 SEV(Severity Incident,严重性事故)。
以下是我们在大规模优化提示缓存过程中总结的经验教训——其中不少会颠覆你的直觉。
为缓存精心布局你的提示

提示缓存的工作原理是前缀匹配(prefix matching)——API 会缓存从请求开头到每个 cache_control 断点之间的所有内容。也就是说,内容的排列顺序至关重要,目标是让尽可能多的请求共享同一个前缀。
最佳做法是:静态内容在前,动态内容在后。对 Claude Code 来说,顺序如下:
- 静态系统提示和工具定义(全局缓存)
CLAUDE.md(在项目范围内缓存)- 会话上下文(在单次会话内缓存)
- 对话消息
这样就能最大化跨会话的缓存命中。
排列出人意料地脆弱!
我们踩过的坑包括:在静态系统提示里放了一个详细的时间戳、工具定义的顺序被非确定性地打乱、更新了工具的参数(比如
AgentTool能调用哪些智能体)等等。
用消息来传递更新
有时候提示中的信息会过时,比如时间或者用户修改了某个文件。直觉上你可能想直接改提示,但这会造成缓存未命中(cache miss),最终让用户付出高昂的代价。
用消息代替修改提示
在下一轮对话中通过消息来传递更新。在 Claude Code 中,我们会在下一条用户消息或工具返回结果里添加一个
<system-reminder>标签来携带更新信息(比如”现在是星期三了”),这样就能保住缓存。
不要在会话中途切换模型
提示缓存是按模型隔离的,这让缓存的成本计算变得相当反直觉。
反直觉的成本计算
假设你已经在一个 Opus 的对话中积累了 10 万 token,这时想问一个比较简单的问题——切换到 Haiku 反而比继续用 Opus 回答更贵,因为你需要为 Haiku 从零重建整个提示缓存。
如果确实需要切换模型,最好的方式是通过子智能体(subagent):由 Opus 准备一条”交接”消息,把需要完成的任务传递给另一个模型。Claude Code 中的 Explore 智能体就是这么做的,它们使用 Haiku 模型。
绝对不要在会话中途增减工具
在对话中途修改工具集,是人们最常打破提示缓存的方式之一。这看起来很合理——你应该只给模型当前需要的工具。但工具定义是缓存前缀的一部分,增加或移除任何一个工具都会导致整个对话的缓存失效。
计划模式——围绕缓存来设计功能
计划模式(Plan Mode)是围绕缓存约束设计功能的经典案例。直觉上的做法是:用户进入计划模式时,把工具集换成只读工具。但这样会打破缓存。
我们的做法是:始终在请求中保留所有工具,把 EnterPlanMode 和 ExitPlanMode 本身设计成工具。用户开启计划模式时,智能体会收到一条系统消息,说明当前处于计划模式以及相应指令——探索代码库、不要编辑文件、完成计划后调用 ExitPlanMode。工具定义从头到尾没有任何变化。
额外好处
因为
EnterPlanMode是模型可以自行调用的工具,当它遇到困难问题时,可以自主进入计划模式,不会造成任何缓存中断。
工具搜索——延迟加载而非移除
同样的原则也适用于工具搜索(Tool Search)功能。Claude Code 可能加载了几十个 MCP 工具,每次请求都包含所有工具的完整定义会很昂贵,但在对话中途移除又会打破缓存。
我们的解决方案是:延迟加载(defer_loading)。不移除工具,而是发送轻量级存根(stub)——只包含工具名称和 defer_loading: true 标记——模型可以通过 ToolSearch 工具在需要时”发现”它们。完整的工具定义只在模型选择使用时才加载。这样缓存前缀就始终保持稳定:同样的存根以同样的顺序存在。
好在你可以通过 API 直接使用 工具搜索 功能来简化这一过程。
分叉上下文——上下文压缩
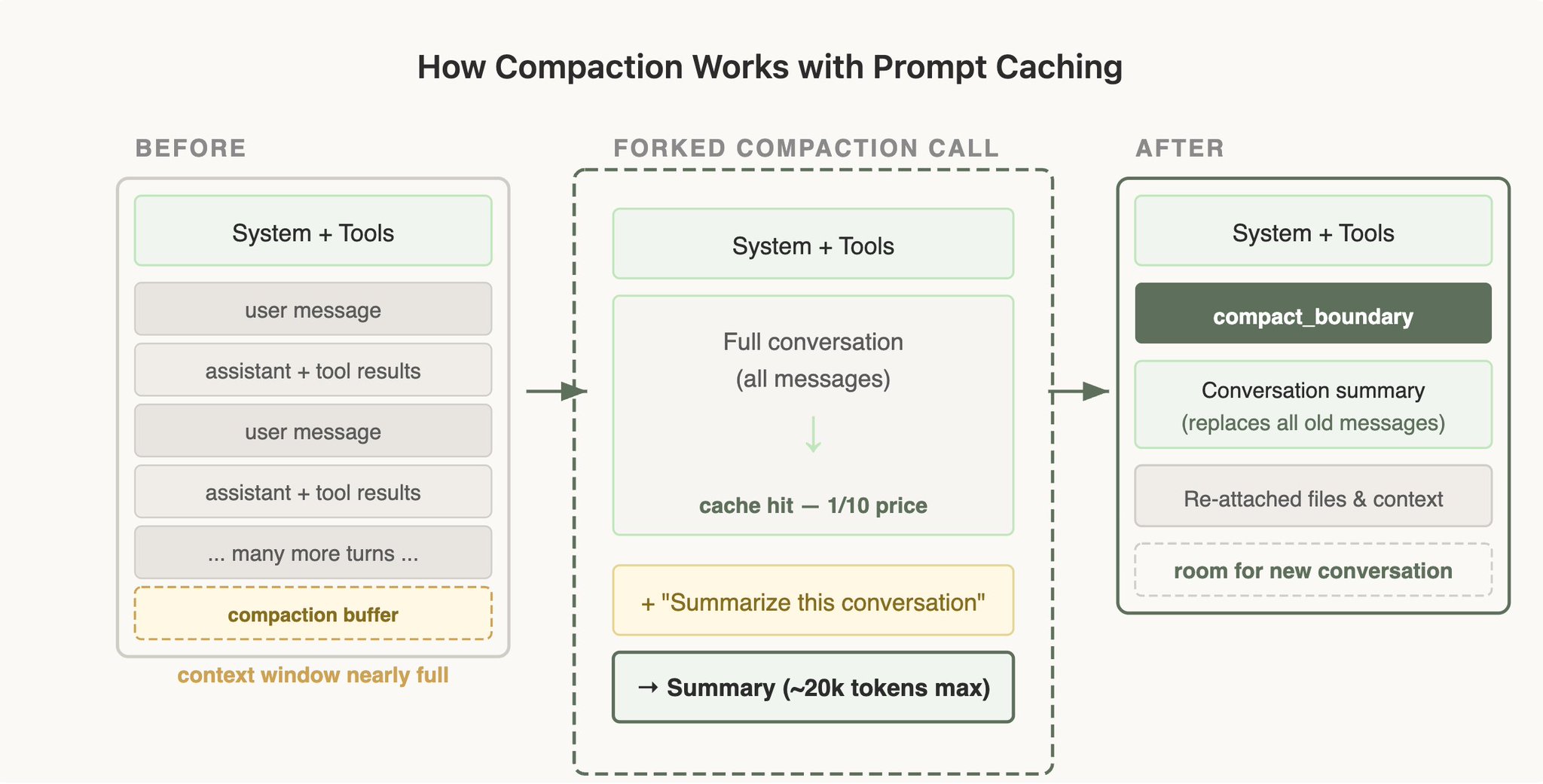
上下文压缩(Compaction)是上下文窗口(context window)耗尽时触发的操作:总结到目前为止的对话,然后用摘要开启一个新会话。
令人意外的是,上下文压缩与提示缓存之间存在很多反直觉的边界情况。
具体来说,执行压缩时需要把整段对话发送给模型来生成摘要。如果这是一个单独的 API 调用,使用了不同的系统提示且不带工具——也就是最直接的实现方式——主对话的缓存前缀就完全匹配不上,所有输入 token 都得按全价处理,用户成本急剧上升。
解决方案——缓存安全的分叉
执行压缩时,我们使用与父会话完全一致的系统提示、用户上下文、系统上下文和工具定义,将父会话的对话消息前置,再把压缩指令作为新的用户消息追加在末尾。
从 API 的角度看,这个请求与父会话的最后一次请求几乎一模一样——相同的前缀、相同的工具、相同的历史——缓存前缀自然得以复用。唯一新增的 token 只有压缩指令本身。
不过这也意味着需要预留一个”压缩缓冲区”(compaction buffer),确保上下文窗口中留有足够空间来容纳压缩消息和生成摘要所需的输出 token。
上下文压缩确实棘手,好在你不必亲自踩这些坑——基于在 Claude Code 中积累的经验,我们已经将 上下文压缩 直接内置到了 API 中,你可以在自己的应用里直接使用。
经验总结
五条核心经验
- 提示缓存基于前缀匹配。 前缀中任何位置的任何改动,都会导致其后所有内容的缓存失效。围绕这个约束来设计整个系统,把顺序排对,大部分缓存就自然而然地生效了。
- 用消息替代系统提示的修改。 你可能想通过编辑系统提示来切换计划模式、更新日期之类的,但更好的做法是在对话过程中把这些信息插入到消息里。
- 不要在对话中途切换工具或模型。 用工具来表达状态转换(比如计划模式),而不是更换工具集;用延迟加载替代移除工具。
- 像监控正常运行时间一样监控缓存命中率。 我们对缓存中断设了告警,并将其视为事故处理。缓存未命中率哪怕只波动几个百分点,都会对成本和延迟产生巨大影响。
- 分叉操作需要共享父会话的前缀。 如果你需要执行旁路计算(压缩、摘要、技能执行),请使用完全一致的缓存安全参数,这样就能命中父会话的缓存前缀。
Claude Code 从第一天起就围绕提示缓存来构建,如果你正在开发智能体产品,你也应该这么做。