今天,我们推出了 /usage 的全新更新,帮助你更好地了解自己在 Claude Code 中的使用情况。这次更新源于我们和大量用户的深入交流。
这些对话中反复出现一个问题:大家管理会话(Session)的方式千差万别——尤其是 Claude Code 升级到百万上下文窗口(Context Window)之后。
你是只开一个会话,还是在终端里挂着两个?每次提问都开新会话吗?什么时候该用压缩(Compact),什么时候该回退(Rewind),什么时候该派子智能体(Subagent)?什么情况下压缩会翻车?
这里面的门道远超想象,它们真正左右着你使用 Claude Code 的体验。归根结底,几乎所有技巧都围绕一件事:管理好你的上下文窗口。
上下文、压缩与上下文衰减快速入门
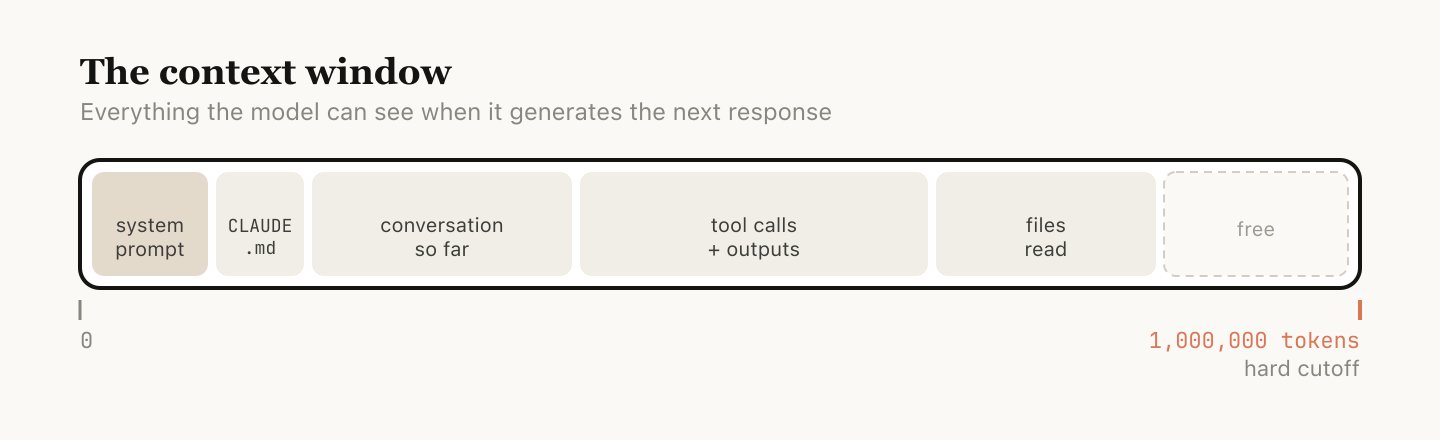
上下文窗口是模型在生成下一条回复时能”看见”的全部内容——系统提示词(System Prompt)、到目前为止的对话、每一次工具调用(Tool Call)及其输出,以及所有被读取过的文件。Claude Code 的上下文窗口大小为一百万 token。
不过,使用上下文是有代价的,我们称之为上下文衰减(Context Rot)。随着上下文不断膨胀,模型的表现会逐渐下降——注意力(Attention)被分散到了更多 token 上,而那些更早的、已经无关紧要的内容开始干扰当前任务。
上下文窗口有硬性上限。当你快要触顶时,就需要把正在做的工作总结成一段更精简的描述,然后在新的上下文窗口里继续——这个过程叫做压缩(Compaction)。你也可以手动触发它。

每一轮对话都是一个分岔路口
假设你刚让 Claude 做完一件事。此刻上下文里已经积累了不少信息(工具调用、工具输出、你的指令),而接下来你能做的事情多得出奇:
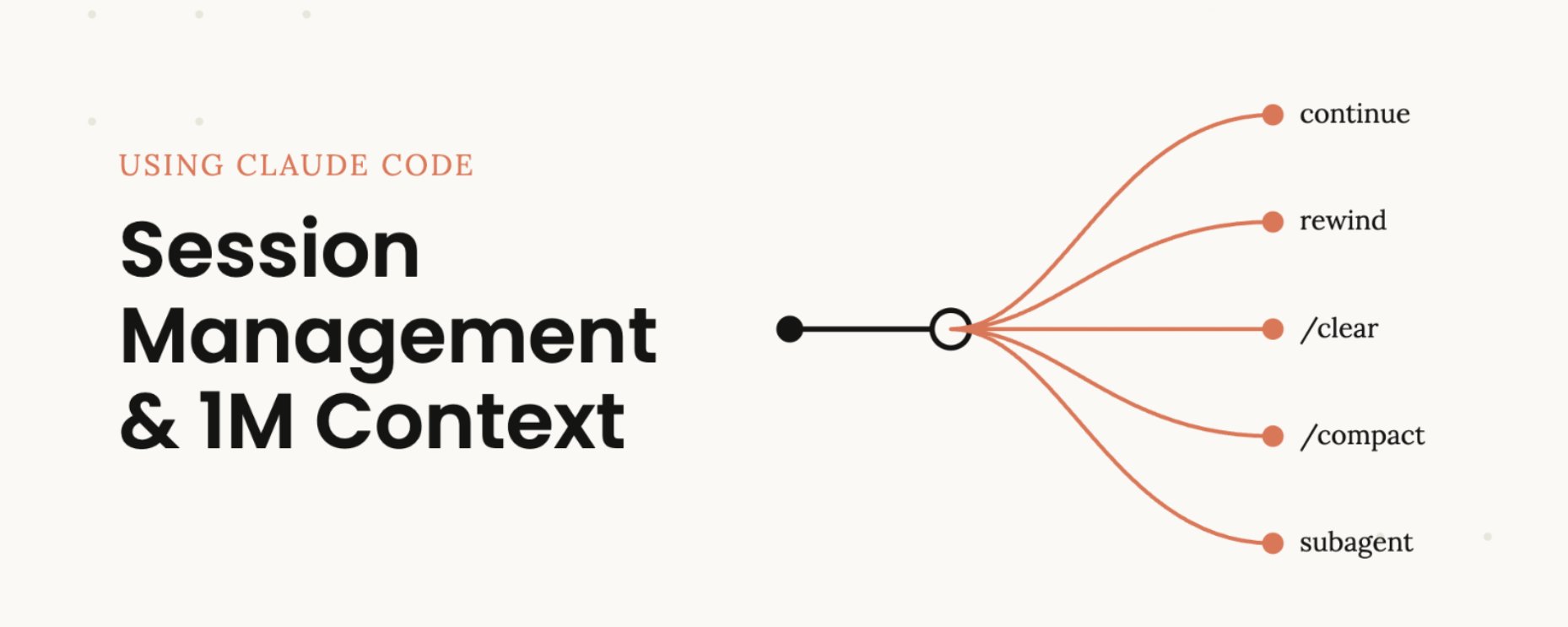
- 继续 —— 在同一个会话里发送下一条消息
- /rewind (esc esc) —— 跳回到之前某条消息,从那里重新开始
- /clear —— 开启全新会话,通常带上你刚才提炼出来的要点
- 压缩 —— 让 Claude 总结目前的对话,然后在摘要基础上继续
- 子智能体 —— 把下一块任务委派给一个拥有全新上下文的智能体,只把最终结果拉回来
最自然的选择当然是直接继续,但另外四个选项存在的意义,就是帮你管理上下文。

什么时候该开新会话
长会话一直开下去,还是及时开新的?我们的经验法则是:开始新任务时,也该开一个新会话。
百万上下文窗口意味着你可以更可靠地完成更长的任务了,比如让 Claude 从零搭建一个全栈应用。
有时你会做一些相关任务,其中部分上下文还用得上,但不是全部。比如为刚实现的功能编写文档——虽然可以开新会话,但那样 Claude 就得重新读一遍你刚写好的那些文件,更慢也更贵。
回退,而不是纠正
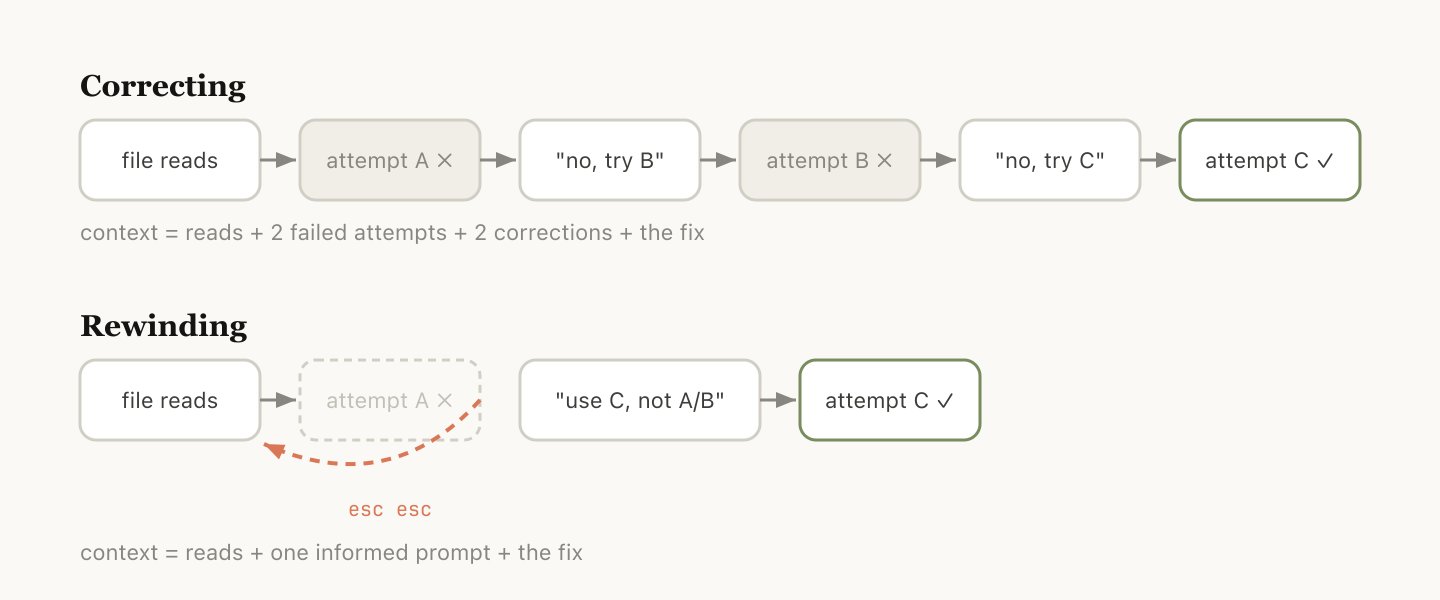
如果只能选一个习惯来判断上下文管理水平,那就是回退。
在 Claude Code 中,双击 Esc(或运行 /rewind)可以跳回到任意一条之前的消息,从那里重新提示。那条消息之后的所有内容都会从上下文中移除。
回退往往比纠正更好。举个例子:Claude 读了五个文件,尝试了一种方案,结果不行。你的本能反应可能是打出”那个方案不行,换 X 试试”——但更好的做法是回退到读完文件之后的那个节点,带着你学到的信息重新提示:“别用方案 A,foo 模块没有暴露那个接口——直接走方案 B。”
你还可以用”从此处总结”让 Claude 总结它的发现并生成一条交接消息(Handoff Message)——就像未来的 Claude 写给过去那个版本的自己的一封信,告诉它”我试过了,此路不通”。
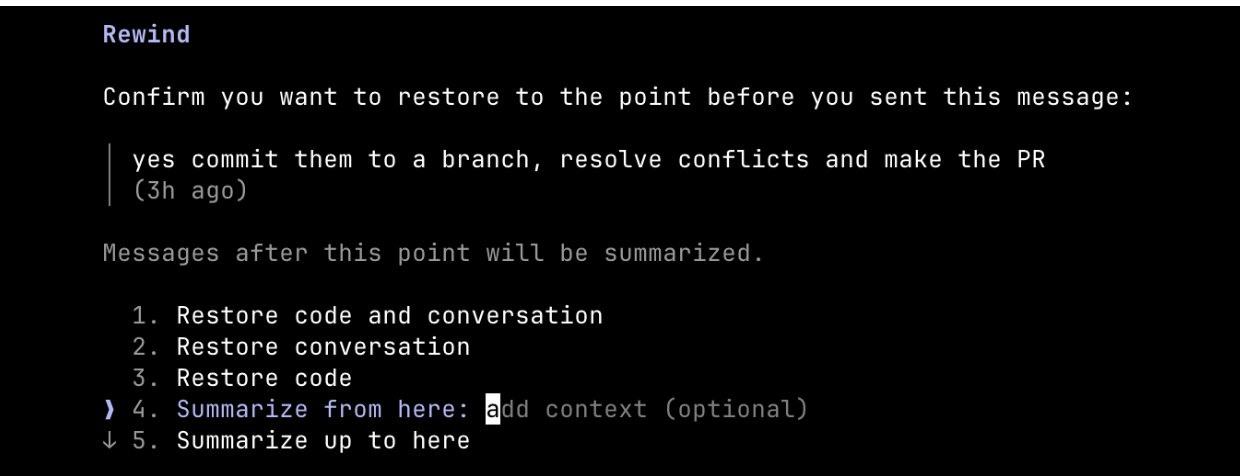
压缩 vs. 全新会话
会话变长之后,你有两种减负方式:/compact 或 /clear(重新开始)。感觉差不多,但行为截然不同。
压缩让模型对当前对话做一次总结,然后用摘要替换掉原来的对话历史。这个过程是有损的——你在信任 Claude 帮你判断什么是重要的。好处是不用自己动手写,而且 Claude 在保留关键发现和重要文件方面可能比你更周全。你也可以给它加引导(/compact 聚焦 auth 重构部分,丢掉测试调试的内容)。
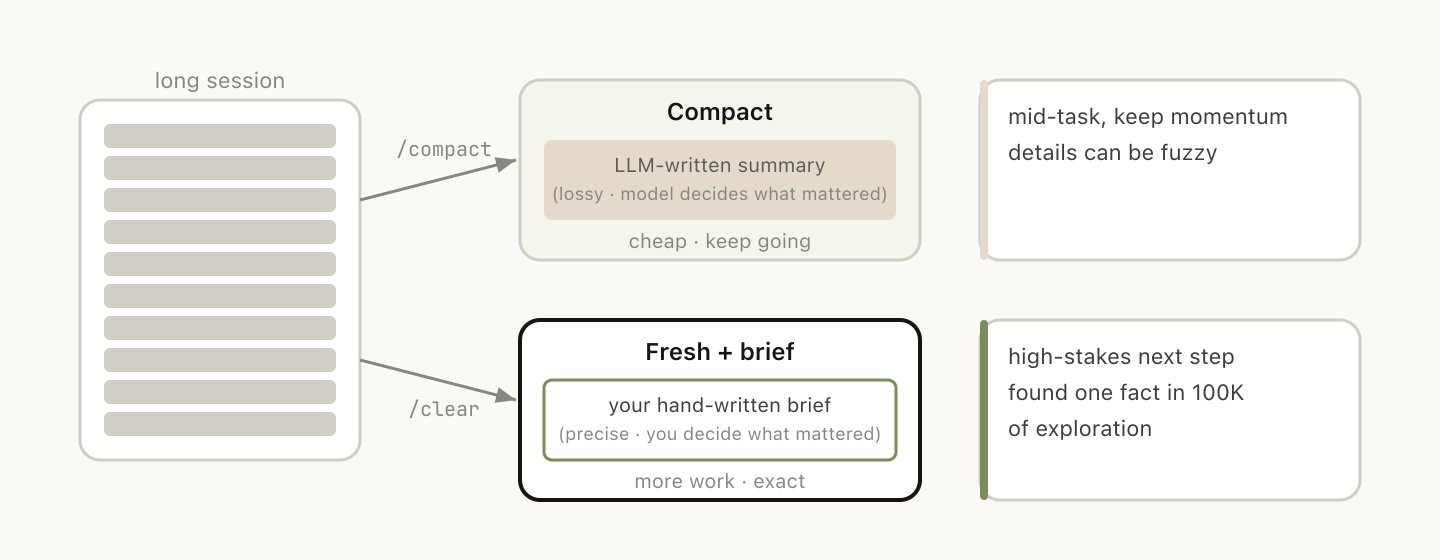
用 /clear 的话,你自己写下重要信息(“我们在重构 auth 中间件,约束条件是 X,关键文件是 A 和 B,方案 Y 已经排除了”),然后干干净净地重新开始。要多花点功夫,但生成的上下文完全由你自己把控。
什么情况下压缩会翻车
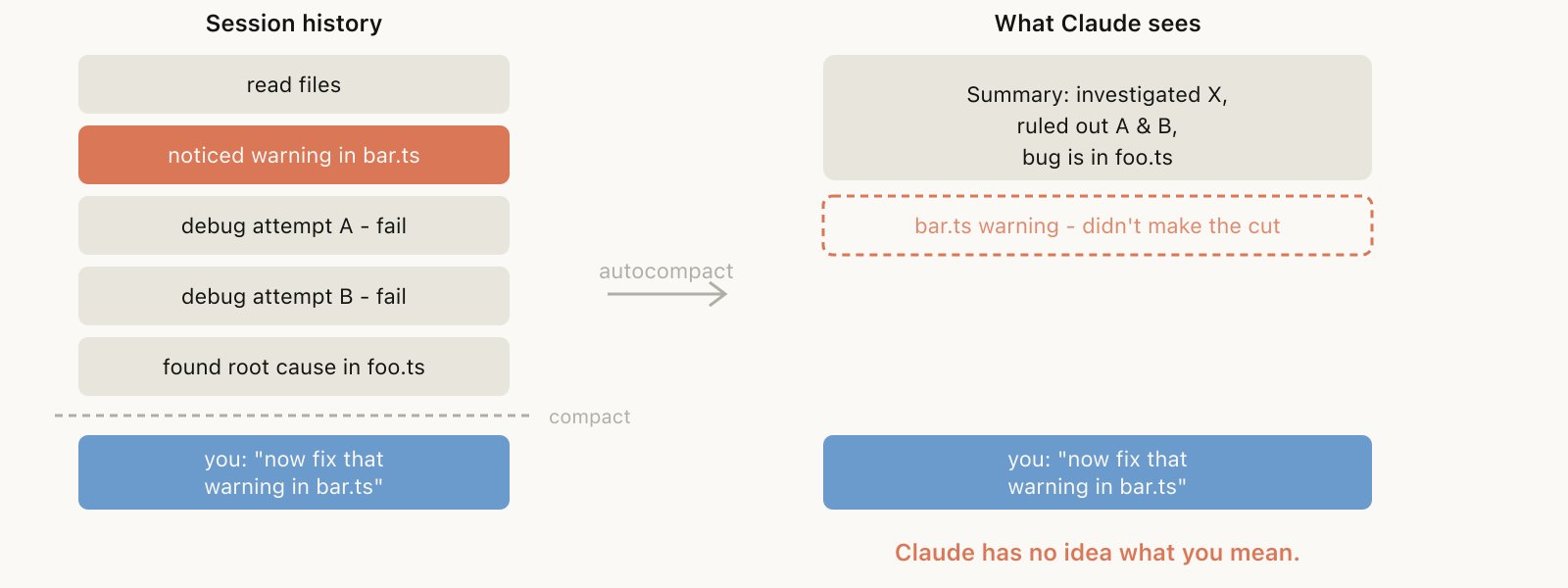
如果你经常跑长会话,可能遇到过压缩效果特别差的时候。我们的发现是:当模型无法预判你接下来要做什么时,坏压缩最容易出现。
举个例子:自动压缩(Autocompact)在一段漫长的调试会话之后触发了,总结了整个排查过程。紧接着你发消息说”现在修一下我们在 bar.ts 里看到的那个警告。”
但因为会话一直聚焦在调试上,那个警告可能已经在总结中被丢掉了。
这个问题尤其棘手——上下文衰减意味着模型在执行压缩的那一刻,恰恰处于它”最不聪明”的时刻。有了百万上下文,你有更充裕的时间主动 /compact,并附上你接下来想做什么的描述。
子智能体与全新上下文窗口
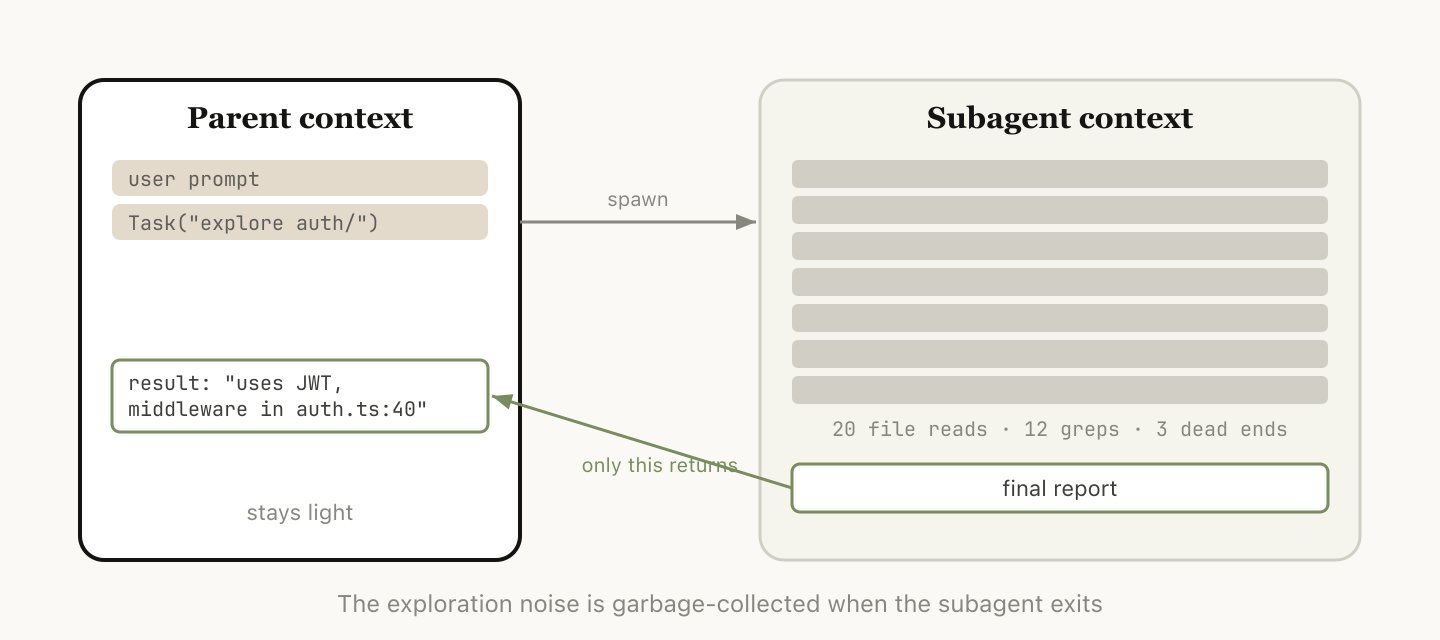
子智能体是上下文管理的一种手段,特别适合这种场景:你事先知道某块工作会产生大量中间输出,而这些输出之后不会再用到。
当 Claude 通过 Agent 工具(Agent Tool)启动一个子智能体时,它会拿到一个全新的上下文窗口,可以做任意多的工作,然后把结果提炼出来——只有最终报告会传回主会话。
我们内部的判断标准是:我还需要这些工具输出本身,还是只要结论?
虽然 Claude Code 会自动调用子智能体,但有时候你可能想明确地告诉它这样做。比如:
- “启动一个子智能体,根据这份 spec 文件验证这次改动的结果”
- “派一个子智能体去读另一个代码库,总结它是怎么实现 auth 流程的,然后你用同样的方式在这里实现”
- “派一个子智能体根据我的 git 改动来写这个功能的文档”
总结
每当 Claude 完成一轮操作、你准备发下一条消息的时候,你就站在了一个决策点上。
随着时间推移,我们期望 Claude 自己就能帮你处理这些选择。但目前,这是你引导 Claude 输出质量的重要方式之一。
