核心思想
Anthropic 官方的计算机 / 浏览器操作工程指南。最高回报的单项优化也最简单:把截图降采样到 API 上限之内(4.6 系列 1568px / 1.15MP,Opus 4.7 2576px / 3.75MP),否则点击精度会大幅下降;记得把返回坐标缩放回真实屏幕、把文本指令放在图像之前。思考力度按模型取舍——4.6 系列默认 medium、Opus 4.7 默认 high,UI 任务以感知为主,过度思考无益。长程会话靠三层上下文管理(缓存断点 + 滚动缓冲 + 压缩)控住成本。安全上提示注入无法回避,最有效的缓解是对高风险动作做人工介入。
Claude 的最新模型在计算机操作和浏览器操作能力上迈出了重要一步。借助这些特性,大语言模型如今能够驱动日益复杂的、支撑真实工作的智能体系统,比如构建软件应用、跨多种异构技术自动化工作流。
在这篇博客中,我们分享将 Claude 用于计算机操作和浏览器操作的最佳实践,涵盖从简单的配置调整到更进阶的集成模式。我们希望这篇文章能在你着手把 Claude 的计算机操作和浏览器操作能力集成进产品时有所帮助。我们同时发布了一个新的演示实现,它封装了其中部分最佳实践,并提供了在 Claude 计算机操作能力之上做开发时会用到的额外工具。
请注意,除非另有说明,这些建议适用于 Claude 4.6 系列(Opus 4.6、Sonnet 4.6、Haiku 4.5)和 Claude Opus 4.7。凡是 4.6 系列与 Opus 4.7 指导意见有差异之处,我们都会内联标注。我们的结论基于内部实验,未来可能随着新模型和新技术的出现而更新。
入门:分辨率与缩放
点击精度是任何计算机操作集成的地基。如果点击落不到该去的位置,下游的一切都无法运转:表单填不上、按钮按不下、工作流彻底失败。影响最大的单项优化恰恰也是最简单的之一:在把截图发送给 API 之前先做降采样。
确保正确的缩放
当你把一张截图发送给 Claude 的计算机操作 API 时,模型会看到这张图,并按你指定的 display_width_px / display_height_px 坐标空间返回点击坐标。但这里有一个重要的约束:API 对图像尺寸有内部处理上限。超过上限的图像会在模型看到之前被降采样,这意味着模型是基于一张降质的图像在做点击判断,而你的 Harness 期望的坐标却对齐着原始分辨率。
对于 Claude 4.6 模型系列,API 的上限是:
- 最长边上限:1568 像素
- 总像素上限:1.15 兆像素
- 超过任一上限的图像都会被内部降采样
我们的 Opus 4.7 模型支持更高的分辨率。上限是:
- 最长边上限:2576 像素
- 总像素上限:3.75 兆像素
- 超过任一上限的图像都会被内部降采样
当坐标空间与模型实际感知到的图像不匹配时,模型预测出的点击会落在与它真正看到的图像不同的显示缩放上。这是高分辨率下点击不准的首要原因。修复方法很直接:在把截图发送给 API 之前,始终将其降采样到这些上限之内。我们一直观察到,图像一旦超出上限,精度就会明显下降,而这一项改动的价值,几乎超过其他任何优化。
推荐分辨率
先从 1280x720 开始。 对大多数使用场景而言,这是一个安全、实用的默认值。它用掉约 80% 的像素预算,稳稳处在最长边和总像素两个上限之内,并且是模型在训练期间见过的标准分辨率。它对现代 Web UI 和老旧桌面应用都能很好地适配。
如果你使用 Opus 4.7,我们建议从 1080p 起步,因为相比 720p 它带来了实打实的质量提升,并在 token 消耗与性能之间取得了良好平衡。
对于希望让模型获取尽可能多视觉信息的开发者,我们还推荐一种「最大化适配 API」的做法:根据源图像的原生宽高比,为每一张图像计算最优分辨率:
import math
# 1568 for 4.6 family, 2576 for Opus 4.7
MAX_LONG_EDGE = 1568
# 1.15MP for 4.6 family, 3.75MP for Opus 4.7
MAX_PIXELS = 1_150_000
def compute_max_api_fit(native_w, native_h):
"""Compute the largest resolution that fits API limits
while preserving aspect ratio."""
aspect = native_w / native_h
# Compute max dimensions from pixel budget
h_from_pixels = math.sqrt(MAX_PIXELS / aspect)
w_from_pixels = h_from_pixels * aspect
# Apply long edge constraint
if native_w >= native_h:
w = min(w_from_pixels, MAX_LONG_EDGE)
h = w / aspect
else:
h = min(h_from_pixels, MAX_LONG_EDGE)
w = h * aspect
# Never upscale beyond native
w = min(w, native_w)
h = min(h, native_h)
return int(w), int(h)这种做法稍微复杂一些,但能避免宽高比失真,并为每张图像用满可用的像素预算。相比固定的 1280x720,它的精度提升幅度不大,但实现起来很直接,并能避免把 16:9 的源图像强塞进 4:3 显示分辨率时产生的失真。
应避免的分辨率:
- 原生分辨率(不缩放):除非你的源图像恰好低于分辨率上限,否则发送原生分辨率的截图是点击精度差的最常见原因。
- 过低的分辨率(低于 960x540):图像分辨率太低时,丢失的细节过多,模型无法准确识别小型 UI 元素。
- 如果在 MacOS 上:浏览器操作的一个常见问题是,MacOS 上的截图常以 2 倍的设备像素比捕获,这意味着你最终可能得到分辨率为屏幕坐标 2 倍的图像。
- 如果你在 4.6 系列上,避免使用 1920x1080 及以上:这些分辨率超过了像素上限,会被静默降采样。Opus 4.7 的上限更高(3.75 兆像素),因此 1080p 和 1440p 都在预算之内;但仍应避免不经降采样直接使用原生 4K。
坐标缩放
当你在发送前调整了截图尺寸,模型会按你指定的显示分辨率返回点击坐标。在执行点击之前,你必须把这些坐标缩放回你实际的屏幕分辨率:
# Your screen is screen_w x screen_h
# You sent a screenshot resized to display_w x display_h
scale_x = screen_w / display_w
scale_y = screen_h / display_h
screen_x = int(api_returned_x * scale_x)
screen_y = int(api_returned_y * scale_y)这一步很直接,但至关重要,因为如果你忘了缩放,或者 display_width_px / display_height_px 与你发送的图像实际尺寸不一致,每一次点击都会有一个恒定的偏移。
消息数组中的内容顺序
构造你的消息内容数组时,要把文本指令放在图像之前,如下面的代码片段所示。这能让模型在处理截图时知道它要找的是什么,从而提升点击精度。
# RECOMMENDED — text instruction first, then screenshot:
content = [
{"type": "text", "text": "Click on the Submit button"},
{"type": "image", "source": {"type": "base64", "media_type": "image/png", "data": screenshot_b64}},
]
# NOT RECOMMENDED — image first, then text:
content = [
{"type": "image", "source": {"type": "base64", "media_type": "image/png", "data": screenshot_b64}},
{"type": "text", "text": "Click on the Submit button"},
]诊断点击问题
如果点击屡屡偏离目标,原因往往可以归结为下面几种之一:
| 症状 | 可能原因 | 试试这样做 |
|---|---|---|
| 点击在某个方向上有恒定偏移 | - display_width_px / display_height_px 与发送的图像实际尺寸不一致 - 截图超过 API 上限,正被静默降采样 - 内容顺序是图像在前而非文本在前 | - 确保显示尺寸与你调整后的截图完全一致,而非你的原生分辨率 - 预先降采样到 1280x720,或使用 compute_max_api_fit - 把文本指令在内容数组中移到图像之前 |
| 点击落在大致正确的区域但偏离目标 | - 目标非常小(复选框、图标、开关) - 源图像分辨率极高(4K+),降采样过程中细节丢失 - 强行使用非原生宽高比导致的宽高比失真 | - 对密集 UI 启用 enable_zoom: True - 以更低 DPI 捕获,或在降采样前裁剪到相关屏幕区域 - 调整尺寸时保留源图像的宽高比 |
| 模型完全点错了元素 | - 指令含糊(存在多个类似「提交」的按钮时却只说「点击提交」) - 目标附近有视觉上相似的元素 - UI 太复杂,单条指令难以应对 | - 使用更具体、带位置上下文的提示词(「点击表单右下角那个蓝色的提交按钮」) - 把复杂交互拆解为更小的步骤 - 提供关于页面布局的额外上下文 |
| 精度全面偏差 | - 截图正以超过 API 上限的尺寸发送 - 源图像来自分辨率极高的显示器(4K+),压缩比极端 - 分辨率过低,丢失了关键细节 | - 把所有截图预先降采样到上限之内 - 对于 4.6 系列上的 4K+ 源图像,Sonnet 比 Opus 4.6 更能耐受重度降采样。在 Opus 4.7 上这一差距基本消失,应使用 4.7 的像素预算(高达 3.75 兆像素),从一开始就减少所需的降采样。 - 先以 1280x720 作为基线尝试;如果损失太大,改用 compute_max_api_fit |
点击任务的模型选择
根据我们的内部测试,Claude Sonnet 4.6 在点击上往往机械精度更高(空间准确性更好,差之毫厘的失误更少),而 Claude Opus 4.6 带来更强的推理能力。当源图像需要重度降采样时,Sonnet 4.6 也更稳健。
Opus 4.7 缩小了这一差距:经过测试,我们发现它的点击精度大致与 Sonnet 4.6 持平,而其更高的分辨率预算从一开始就减少了所需的降采样量——当你既想要 Opus 级别的推理能力、又想要出色的点击精度时,它是一个有力的选择。
对于大多数任务,我们建议从 Sonnet 4.6 起步,它在点击精度、推理能力和成本之间提供了最佳平衡。当你需要更强的推理能力时——尤其是在使用高分辨率源图像时——选择 Opus 4.7。当延迟是首要考量时,Haiku 4.5 仍是一个出色的选项。进阶工作流可能仍会受益于「编排者 + 子智能体」模式:由推理模型负责规划与决策,而 Sonnet 或 Haiku 执行机械性的点击步骤。
处理小目标
点击精度会随着目标变小而下降。大型和中型的 UI 元素(按钮、输入框、标准菜单项)在安全区内的所有分辨率下都很可靠。难点在于小型和微型目标,比如复选框、系统托盘图标、下拉箭头、小型开关,以及树状视图的展开/折叠按钮。
如果你的应用频繁涉及点击小目标,可以考虑以下策略:
对密集 UI 使用缩放。 Claude 4.6 和 4.7 模型支持一项缩放能力,让模型在点击前能以更高分辨率检视特定的屏幕区域。在你的工具配置中启用它:
{
"type": "computer_20251124",
"name": "computer",
"display_width_px": 1280,
"display_height_px": 720,
"enable_zoom": True
}把目标做大。 如果被自动化的 UI 由你掌控,那么增大点击目标的尺寸(哪怕只是稍微增大)对可靠性的影响也会异常显著。具体可以是降低系统 DPI、放大浏览器,或调整 UI 缩放设置。
对微型目标改用键盘替代方案。 对于非常小的元素,比如系统托盘图标或微型复选框,键盘快捷键或基于 Tab 的导航可能比点击更可靠。如果你的工作流允许,提示模型在特定步骤使用键盘交互可以提升成功率。
考虑源图像分辨率。 来自 4K+ 显示器的截图被压缩到 720p 时会丢失大量细节(举例来说,一个在 3840x2160 原生分辨率下 16 像素的复选框,在 1280x720 显示分辨率下大约只剩 5 像素,目标小了很多,因而更难命中)。如果你在处理分辨率极高的显示器,可以考虑使用 Opus 4.7,它的分辨率上限高于以往的模型。如果使用 4.6 模型,可以考虑以更低的 DPI 捕获、用显示缩放放大 UI 元素,或让截图聚焦于屏幕的相关部分而非整个显示器。由于这些模型用更少的像素表示了更多的信息,我们观察到性能会随着源图像尺寸的增大而下降,也就是说需要更多的压缩。
我们测试过但无效的方法
我们在内部评测中实验了几种流行的优化技术,没有发现它们带来一致的提升,不过结果可能因具体情况而异:
- 把图像切成更小的瓦片:把一张截图分割成象限或区域并分别发送,并未提升点击精度。
- 叠加带坐标的网格图案:在截图上添加一层视觉坐标网格来帮助模型定位目标,并未产生可靠的收益。
- 缩放算法的选择:PIL LANCZOS、sips 以及其他常见的缩放算法产生了相同的结果。用你的技术栈里方便的那个就好。
排查失败
如果在尝试了上述修复后模型行为仍不可预测,那就记录完整的对话记录,并把预测出的点击叠加到源截图上,以理解模型实际看到了什么、又做了什么决策。
有些失败根本与点击精度无关。举例来说,某些下拉菜单可能会调起浏览器视口捕获不到的系统级 UI——模型看上去是任务失败了,但其实它只是看不到自己需要交互的那个菜单。在这类情况下,模型应当依赖点击之外的方法,比如执行 JavaScript、键盘导航,或直接操作文档对象模型(DOM)。
快速参考
如何为计算机操作缩放并准备一张图像
import math
from PIL import Image
import base64
import io
# 1568 for 4.6 family, 2576 for Opus 4.7
MAX_LONG_EDGE = 1568
# 1.15MP for 4.6 family, 3.75MP for Opus 4.7
MAX_PIXELS = 1_150_000
def prepare_screenshot(screenshot: Image.Image, native_w: int, native_h: int) -> tuple[str, int, int]:
"""Resize a screenshot to fit API limits and return base64 + display dimensions."""
# Option A: Fixed 720p (simple, reliable)
display_w, display_h = 1280, 720
# Option B: Max API fit (maximizes fidelity)
# display_w, display_h = compute_max_api_fit(native_w, native_h)
resized = screenshot.resize((display_w, display_h), Image.LANCZOS)
buffer = io.BytesIO()
resized.save(buffer, format="PNG")
b64 = base64.standard_b64encode(buffer.getvalue()).decode()
return b64, display_w, display_h
def scale_coordinates(api_x: int, api_y: int, display_w: int, display_h: int,
screen_w: int, screen_h: int) -> tuple[int, int]:
"""Scale API-returned coordinates back to native screen space."""
screen_x = int(api_x * (screen_w / display_w))
screen_y = int(api_y * (screen_h / display_h))
return screen_x, screen_y
def compute_max_api_fit(native_w: int, native_h: int) -> tuple[int, int]:
"""Compute the largest resolution that fits API limits while preserving aspect ratio."""
aspect = native_w / native_h
h_from_pixels = math.sqrt(MAX_PIXELS / aspect)
w_from_pixels = h_from_pixels * aspect
if native_w >= native_h:
w = min(w_from_pixels, MAX_LONG_EDGE)
h = w / aspect
else:
h = min(h_from_pixels, MAX_LONG_EDGE)
w = h * aspect
w = min(w, native_w)
h = min(h, native_h)
return int(w), int(h)用法:
import anthropic
from PIL import Image
client = anthropic.Anthropic()
# Capture screenshot (your method here)
screenshot = Image.open("screenshot.png")
native_w, native_h = screenshot.size
# Prepare for API
b64, display_w, display_h = prepare_screenshot(screenshot, native_w, native_h)
# Send to Claude — text before image
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["computer-use-2025-11-24"],
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Click on the Submit button"},
{"type": "image", "source": {"type": "base64", "media_type": "image/png", "data": b64}},
]
}],
tools=[{
"type": "computer_20251124",
"name": "computer",
"display_width_px": display_w,
"display_height_px": display_h,
}],
)
# Scale coordinates back for execution
api_x, api_y = extract_click_coords(response) # your parsing logic
screen_x, screen_y = scale_coordinates(api_x, api_y, display_w, display_h, native_w, native_h)为计算机操作调节思考力度
Claude 的最新模型支持自适应思考,这是一项让 Claude 自行决定在行动前对中间步骤思考多少的设置。自适应思考无需手动设定一个思考 token 预算,而是让 Claude 根据每个请求的复杂度,动态判断何时使用、以及在多大程度上使用扩展思考。对计算机操作而言,这意味着 Claude 可以思考它在屏幕上看到了什么、规划多步交互,并在确定点击或按键之前自我纠正。
有了自适应思考,Claude 的思考深度通过 thinking 参数搭配一个力度等级来控制:low、medium、high、xhigh(Opus 4.7 支持)和 max。思考更多意味着每个动作的推理更多,但也意味着更多的输出 token、更高的延迟和更高的成本。
很自然的问题是:对不同的模型而言,对计算机操作来说多少思考量才是最优的?
Claude Opus 4.7
我们在一套端到端的 UI 自动化任务上测试了每个思考力度等级,这些任务横跨桌面应用、浏览器以及多应用工作流。
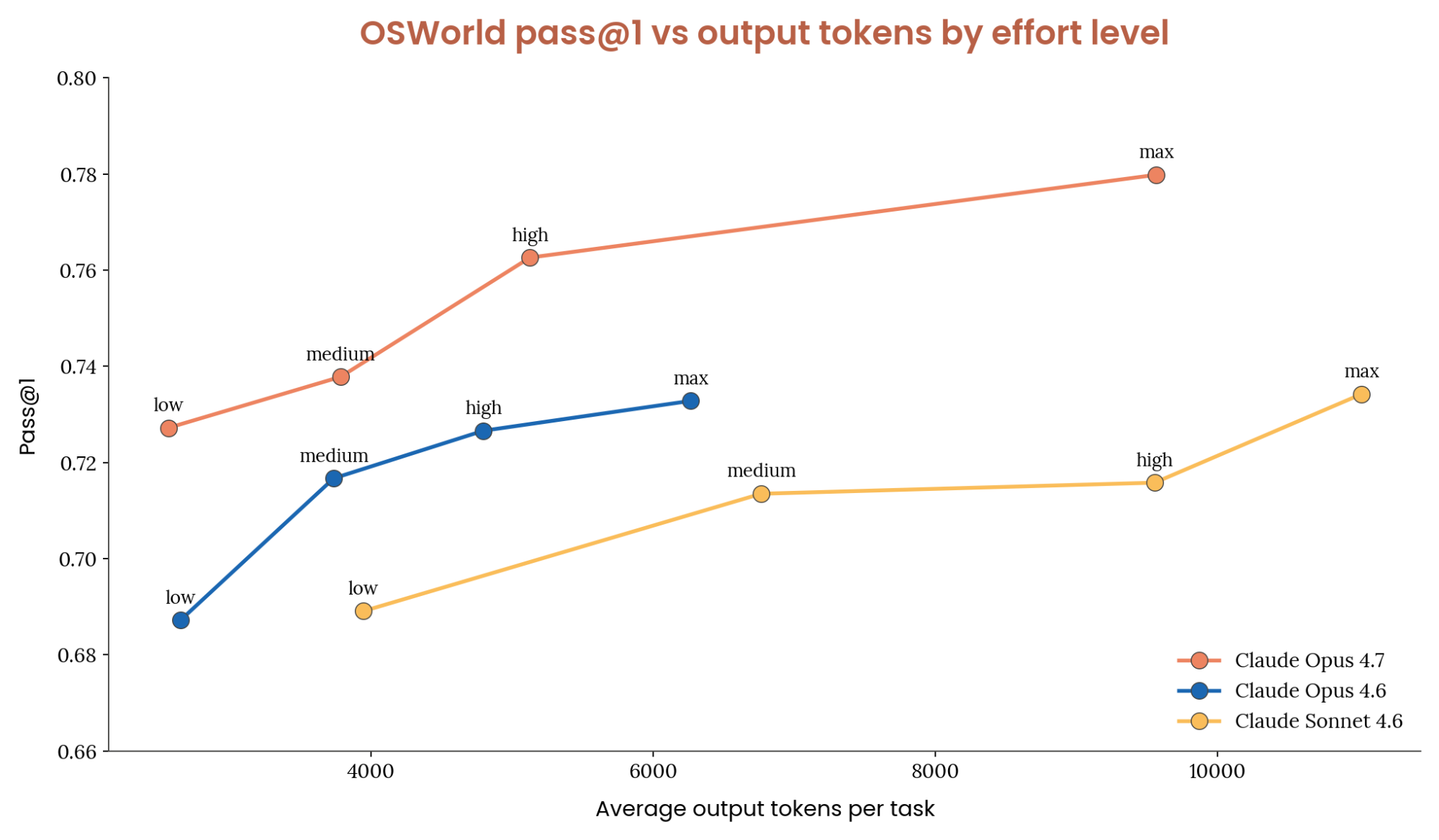
Opus 4.7 的表现优于 4.6 系列。 在 OSWorld Verified 基准上,我们发现,在同等 token 用量和力度设置下,Opus 的表现优于所有 4.6 系列模型。Opus 4.7 在 low 力度下的得分与 Sonnet 4.6 在 max 下相近,而每个任务的 token 用量约为后者的 1/10。对于困难任务,Opus 4.7 是显而易见的选择。
把力度设为 high 能取得接近最高的任务成功率,而输出 token 用量大约只有 max 的一半。与 Opus 4.6 相比,low、medium 和 high 用掉的 token 量大致相同,同时在 OSWorld 上提升了得分。在我们的内部测试中,max 力度用掉了更多 token,并给出了最佳得分。下表概述了我们关于何时使用各个思考力度等级的建议。
各力度等级的建议
| 场景 | 思考力度 | 原因 |
|---|---|---|
| 大多数使用场景的默认值 | high | Opus 4.7 最擅长困难任务。使用 high 能给模型足够的推理量,让它规划复杂的多步交互,又不会显著增加 token 用量。 |
| 高吞吐 / 成本敏感 | low | 更低的 token 用量,同时质量介于 Opus 4.6 的 high 与 max 力度设置之间。 |
| 简单、定义明确的工作流 / 追求最快 | 建议尝试 Sonnet 4.6 | 当低延迟是最高优先级时使用。对于 UI 一致、工作流已知的简短、可预测任务,它已足够。 |
| 复杂的一次性任务 | max | 当任务极具挑战性、且你需要一次就做对时使用。 |
Claude 4.6 模型
我们在一套端到端的 UI 自动化任务上测试了每个思考力度等级,这些任务横跨桌面应用、浏览器以及多应用工作流。
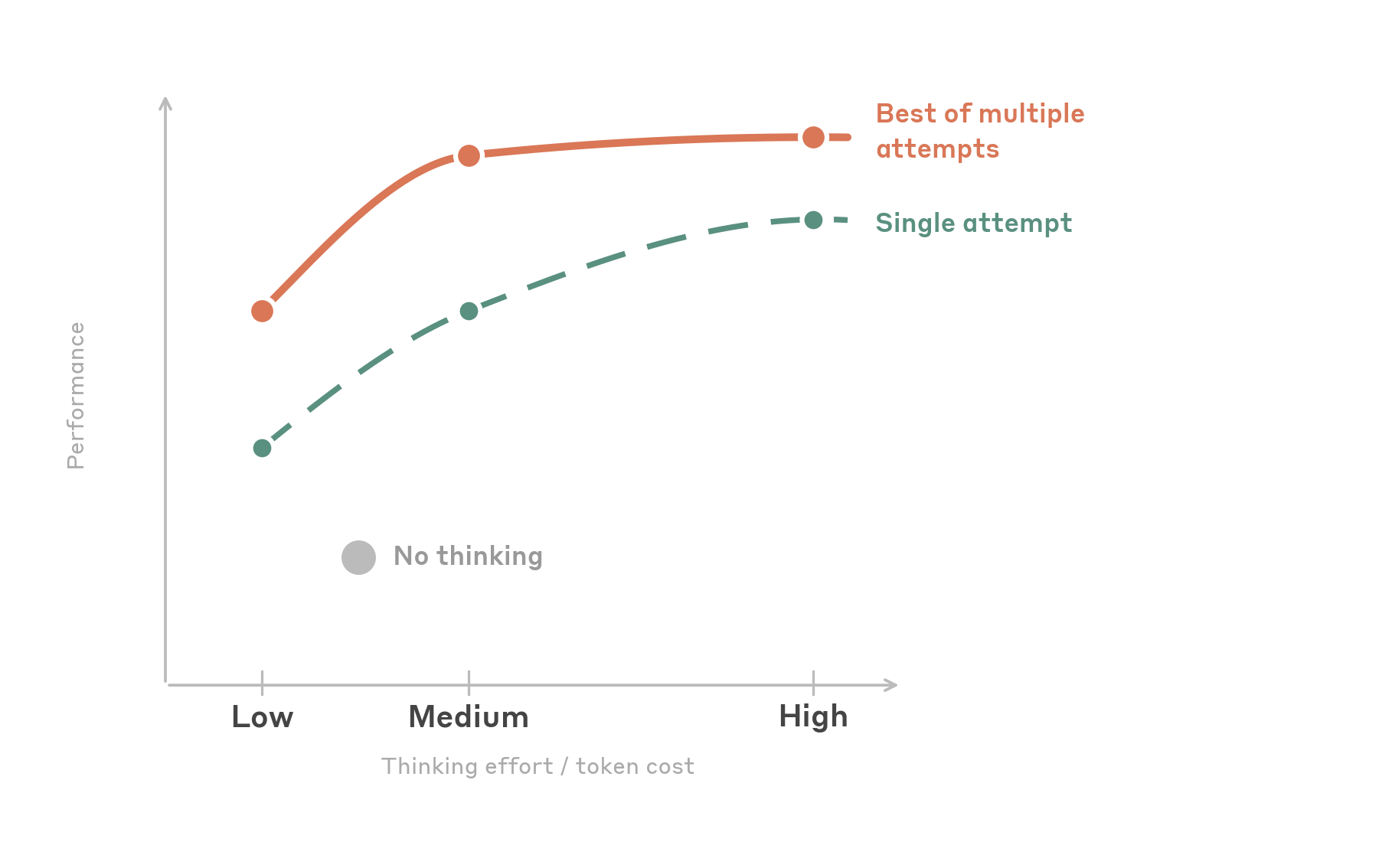
有两个模式格外突出:
medium 力度是甜蜜点。 把力度设为 medium 能取得接近最高的任务成功率,而输出 token 用量大约只有 high 的一半。超过 medium 之后,性能在一定程度上趋于平稳。值得注意的是,当任务被重试时,medium 和 high 会收敛到相同的成功率。这意味着 high 力度也许能帮助模型在第一次就把一个困难任务做对,但只要给予多次尝试,medium 可能以更低的成本同样可靠地达成目标。
少量思考,收效颇丰。 low 力度是一个出人意料地有力的选项。它实际用掉的总输出 token 比完全禁用思考还要少(模型犯的错更少,需要的重试周期也更少),同时精度持平或略高于不思考的情况。这使它成为成本敏感、高吞吐工作负载的最佳选项。下表概述了我们的力度建议。
各力度等级的建议
| 场景 | 思考力度 | 原因 |
|---|---|---|
| 大多数使用场景的默认值 | medium | 最佳的精度成本比。给模型足够的推理量来规划多步交互,又不会过度思考。在有重试的情况下,以一半的 token 成本匹敌 high 的性能。 |
| 高吞吐 / 成本敏感 | low | 比不思考更精确,但由于错误和重试更少,token 用量更低。 |
| 简单、定义明确的工作流 / 追求最快 | 禁用思考 | 当低延迟是最高优先级时使用。对于 UI 一致、工作流已知的简短、可预测任务,它已足够。 |
| 复杂的一次性任务 | high | 当任务具有挑战性、且你需要一次就做对时使用。如果你的系统支持重试,medium 可能最终达成同样的成功率。 |
我们不建议在计算机操作中使用 max 力度。在我们的测试中,相比 high 它没有带来任何精度收益,反而进一步推高了输出 token 成本。UI 任务以感知为主,而非深度逻辑性的,多出的推理预算要么用不上,要么导致过度思考。请记住,随着模型的演进,这条建议会发生变化。
medium 力度等级的配置示例
import anthropic
client = anthropic.Anthropic()
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=16000,
betas=["computer-use-2025-11-24"],
thinking={"type": "adaptive"},
output_config={"effort": "medium"},
messages=[...],
tools=[
{
"type": "computer_20251124",
"name": "computer",
"display_width_px": 1280,
"display_height_px": 720,
}
],
)为什么思考更多并不总是有帮助
UI 自动化任务与编程或数学问题有着根本性的不同。大多数计算机操作动作是感知性和机械性的:识别正确的元素、在正确的位置点击,而非深度逻辑性的。思考在以下情况下帮助最大——当模型需要:
- 在开始前规划一个多步序列(例如,「我需要打开设置,导航到隐私,然后关闭追踪」)
- 从意料之外的 UI 状态中恢复(例如,出现了一个未曾预料的对话框)
- 在屏幕上的内容与任务指令之间交叉比对信息
- 在专业软件上完成有挑战性的项目
提升安全性:善用提示注入分类器
本节介绍提示注入防护。如果你使用我们官方的计算机操作工具标头,这项防护会默认且免费提供。不过,如果你有兴趣在自定义的计算机操作或浏览器操作工具上启用它,请填写我们的提示注入分类器意向表单。
计算机操作智能体在设计上就要与不受信任的内容打交道。Claude 处理的每一张截图、每一个网页、每一个应用 UI,都可能包含对抗性指令,包括隐藏文本、被篡改的图像、欺骗性的 UI 元素,或试图劫持智能体行为的社会工程学手段。这一攻击面与你掌控输入的典型 API 集成有着根本性的不同。在计算机操作中,模型的输入是开放的互联网,以及智能体所导航的任何软件。
随着计算机操作智能体变得更强大、部署更广泛,提示注入也相应地成为更严重的风险。一个能点击、输入和导航的智能体,可能被操纵去采取真实世界中的行动,比如填写表单、下载文件,或导航到恶意 URL。为任何生产环境部署构建针对这些攻击的稳健防御,都是必不可少的一环。
我们如何应对提示注入防御
我们已经详细撰文介绍过我们针对浏览器操作和计算机操作的提示注入防御方法。我们的防御策略在多个层面运作:
训练期的稳健性。 我们使用强化学习,把提示注入抵抗力直接构建进 Claude 的能力之中。在训练期间,Claude 会接触嵌入在模拟网页和应用 UI 中的注入内容,当它正确识别并拒绝遵从恶意指令时会得到奖励。这意味着 Claude 的第一道防线就是模型本身——它已经学会区分合法的用户指令与任务执行过程中遇到的对抗性内容。
实时分类器。 我们运行探针,扫描进入 Claude 上下文窗口的内容,并标记出潜在的提示注入企图。这些探针能跨多种模态检测对抗性命令,比如隐藏在页面内容中的文本、嵌入在图像里的指令,以及设计来欺骗智能体的欺骗性 UI 元素,并在识别出攻击时相应地调整 Claude 的行为。
持续的红队演练。 我们的安全研究人员持续探查这些防御,我们也参与外部的对抗性评估,以对照不断演进的攻击技术来衡量稳健性。
自从我们最初的计算机操作研究预览版以来,我们一直在这三个层面持续大力投入。每一代新模型都纳入了更强的训练期防御和更强大的分类器,我们也扩展了红队评估所针对的攻击技术范围。
使用 Claude 内置的分类器
当你通过 API 使用 Claude 的官方计算机操作工具时,提示注入分类器会在每个请求上自动运行。这些分类器与主模型推理并行运作,给你的请求增加的延迟约为零,也不增加任何额外成本。
启用这项防护你无需配置任何东西。当你使用官方的 computer_20251124 工具类型时,它默认开启。分类器会评估截图和其他内容是否有提示注入的迹象,并据此影响 Claude 的响应。
# Classifiers run automatically when using the official CU tool — no extra config needed
tools = [
{
"type": "computer_20251124",
"name": "computer",
"display_width_px": 1280,
"display_height_px": 720,
}
]如果你没有使用官方的计算机操作工具
许多开发者使用自定义的工具定义来构建计算机操作集成,而非官方的 computer_20251124 工具类型,比如定义自己的截图工具和点击工具。如果你的设置属于这种情况,上述内置分类器目前不会在你的请求上运行。
我们正在积极探索如何把提示注入防护扩展到这些自定义实现。如果你正在不使用官方工具类型的情况下构建计算机操作或浏览器操作集成,并且对提示注入分类器感兴趣,请填写这份意向表单,待这项能力可用时我们会与你跟进。
无论是否使用分类器都适用的最佳实践
分类器是一道防御层,而非完整的解决方案。我们建议任何计算机操作部署都遵循以下实践:
对高风险动作实施人工介入。 让智能体在执行不可逆动作之前暂停并请求用户确认,比如提交表单、进行购买、发送消息或修改数据。无论分类器表现如何,这都是针对提示注入最有效的单项缓解措施。
收窄智能体的权限。 限制智能体能做的事。如果你的工作流不需要下载文件,就别给智能体下载文件的权限。如果它不需要发送邮件,就别给它访问邮件客户端的权限。缩小一次成功注入的杀伤半径,与阻止注入本身同样重要。
监控并记录智能体的动作。 记录智能体所采取的完整动作序列,包括每一步的截图。这让你能够检测异常行为、在出错时审计发生了什么,并构建一个反馈循环以持续提升系统的稳健性。
把所有 Web 内容都视为不受信任。 设计你的智能体系统提示词时,要明确区分用户的指令与任务执行过程中遇到的内容。提醒模型,网页上、邮件里或应用 UI 中发现的文本并非来自用户,不应被当作指令对待。
计算机操作的上下文管理
构建计算机操作智能体时,截图累积得很快。每个动作都会生成一张新图像,而每张图像视分辨率不同会消耗大约 1000–1800 个 token。把系统提示词、工具定义和文本内容算进去之后,一个 200k 的上下文窗口在远不到 100 张截图时就会被填满。
把这个上下文管理好有两个目标:1)让总 token 数保持有界,2)让提示缓存保持有效,这样你就不必为同一段前缀反复支付全价。我们发现,有效的上下文管理对长时运行智能体的成本和延迟,影响超过几乎任何其他优化。本节介绍三个能干净叠加的层次:放置缓存断点、在不破坏缓存的前提下修剪旧截图,以及在修剪还不够时对历史做摘要。
放置缓存断点
提示缓存只有在断点落在会跨多轮复现的内容上时才有用。API 总共支持四个缓存断点。把四个全放在稳定的前缀上(系统提示词、工具定义)是一种浪费,因为那段前缀已经被命中过一次、且永远不会失效,所以一个断点就够了。另外三个更值得花在近期历史上——那里失效风险最高,而且在长会话中节省的成本会复利累积。
我们建议:
- 一个断点放在系统提示词或末尾的工具定义上。 这段前缀在一个会话内很少变化。
- 最多三个额外的断点放在最近的工具结果上,每轮向前推进,并清除上一轮迭代的断点,这样你就不会超出四个断点的上限。
把断点分散到近期的多个位置,能让你获得优雅的降级。如果你最近的那个断点失效了——比如因为一次图像修剪、一次压缩或一次工具定义变更——更靠前的某个断点仍可能命中,于是你继续支付全额输入成本的 10%,而非 100%。
缓存控制与设置断点的示例:
def set_trailing_cache_control(messages, max_breakpoints=3):
"""Place up to \`max_breakpoints\` ephemeral cache_control markers on the
most recent tool_result blocks, after clearing any existing markers."""
for msg in messages:
for block in msg.get("content", []):
if isinstance(block, dict):
block.pop("cache_control", None)
placed = 0
for msg in reversed(messages):
for block in reversed(msg.get("content", [])):
if placed >= max_breakpoints:
return
if isinstance(block, dict) and block.get("type") == "tool_result":
block["cache_control"] = {"type": "ephemeral"}
placed += 1方案一:滚动缓冲(缓存感知)
让 token 数保持有界的最简单办法,是只保留最近的 N 张截图、丢弃其余的。在每次 API 调用之前,遍历消息数组,把较旧的图像块替换为一个简短的占位符(例如,一个写着「[Image omitted]」的文本块)。
这一范式的朴素版本是随着截图变旧而逐张丢弃,这会在每一轮改变前缀,从而持续地使提示缓存失效。这正是滚动缓冲落下「破坏缓存」名声的原因。修复办法是分批修剪,让前缀连续若干轮保持逐字节一致,然后失效一次,再保持稳定一阵。
我们测试过的一个具体范式是:
- 把最近的 keep_n 张截图保留为全分辨率。
- 一旦截图总数超过 keep_n + interval,就在单次遍历中把最旧的 interval 张截图替换为占位符。
- 在两次修剪事件之间,消息数组跨多轮逐字节一致,因此你的缓存断点会持续命中。
起步时的合理默认值:keep_n = 3,interval = 25。这些值是可调的,更大的 interval 意味着更少的修剪事件(缓存效率更好),但上下文中会留有一条更长的全分辨率截图尾巴(token 更多)。在一条有代表性的轨迹上测量缓存命中率和总输入 token,并据此调整。
在保留缓存断点的同时修剪旧截图的示例:
def prune_old_screenshots(messages, keep_n=3, interval=25):
"""Replace older screenshots with text placeholders in batches.
Only prunes when the total count exceeds keep_n + interval, so the
message prefix stays byte-stable for \`interval\` turns between prunes."""
image_positions = [
(msg_idx, block_idx)
for msg_idx, msg in enumerate(messages)
for block_idx, block in enumerate(msg.get("content", []))
if isinstance(block, dict) and block.get("type") == "image"
]
if len(image_positions) <= keep_n + interval:
return messages
to_prune = image_positions[:-keep_n][-interval:]
for msg_idx, block_idx in to_prune:
messages[msg_idx]["content"][block_idx] = {
"type": "text",
"text": "[Image omitted]",
}
return messages滚动缓冲仍有一个实实在在的局限:缓冲区之外的一切都消失了。最初的指令、智能体已经尝试过什么、它在任务中处于什么位置——全都随着被修剪的截图一起不见了。对于简短任务(约 50 个动作以内),这没问题。对于更长的任务,要把它与压缩结合起来。
方案二:基于 LLM 的压缩
与其默默丢弃旧图像,不如在丢弃整段对话之前先对它做摘要。摘要会保留发生了什么、用户要求了什么、已经完成了什么,以及从哪里继续。少量近期截图会与摘要一同保留,这样智能体就能看到自己当前正在看的东西。
压缩与缓存感知的滚动缓冲是互补的。用滚动缓冲做逐轮处理,让 token 增长保持可控;偶尔用压缩来回收窗口的其余部分,同时不丢失更早的上下文。每次压缩事件在设计上就是一次缓存失效,所以你会希望它很少发生,而非每隔几轮就来一次。
摘要提示词
下面这个示例提示词提供了一个脚手架,其中每一节都针对一种特定的失败模式。提示词必须捕获智能体继续任务所需的一切,使其无需重读原始对话,如下例所示:
COMPACT_PROMPT = """Your task is to create a detailed summary of this conversation that
will REPLACE the conversation history. The agent will continue working with only this
summary and a few recent screenshots as context.
CRITICAL: Preserve ALL user instructions verbatim. User instructions are the most
critical element. If they are lost, the agent will deviate from the task.
Before providing your summary, analyze the conversation in tags:
1. Extract every user instruction, requirement, and constraint
2. Identify if this is a repeatable workflow (e.g., processing N items)
3. Chronologically trace what actions were taken and what happened
Your summary MUST include these sections:
1. USER INSTRUCTIONS:
- Complete initial task definition (verbatim when possible)
- ALL specific requirements and criteria
- Every "DO NOT", "ALWAYS", "MUST" instruction
- Any corrections or feedback that changed the approach
2. TASK TEMPLATE (if this is a repeatable workflow):
- The pattern being repeated
- Decision criteria for each iteration
- Standard workflow steps
- Example of one completed iteration
3. CONSTRAINTS AND RULES:
- All user-specified rules and restrictions
- Edge cases and exceptions discovered
4. ACTIONS TAKEN:
- Pages visited and elements interacted with
- Forms filled and buttons clicked
5. ERRORS AND FIXES:
- What went wrong and how it was resolved
- Approaches that failed (so they aren't retried)
6. PROGRESS TRACKING:
- Items completed vs. remaining
- Current position in the workflow
7. CURRENT STATE:
- Current application, URL and domain (optional)
- Important page state (logged in, form progress, etc.)
8. NEXT STEP:
- Exactly what should be done next to continue
"""在上面的提示词中,用户指令防止任务偏移:没有它,智能体会在压缩后偏离任务。任务模板捕获可重复的模式,让智能体能在压缩后继续迭代,而无需从头重新推导工作流。约束与规则保留了任务开始前设定或任务过程中发现的限制和边界情况,这样智能体就不会违反它本已知晓应遵守的既有规则。已采取的动作有助于追踪过往进度。错误与修复防止重试失败过的方法(「我已经试过点击提交了;在勾选条款复选框之前它不起作用」)。进度追踪防止重启和漏项。当前状态和下一步给出一个明确无歧义的恢复入口。
服务端压缩(beta)
使用这个提示词最简单的方式,是让 API 通过服务端压缩(beta)来处理压缩。把你自定义的摘要提示词作为 context_management 中的 instructions 参数传入,当输入 token 超过一个触发阈值时,API 就会自动做摘要。instructions 参数会完全替换默认的摘要提示词,所以上面那些章节正是模型将要遵循的内容。设置 pause_after_compaction,可以把最近的消息(包括截图)跨压缩事件附带过去。
使用自动压缩工具的示例:
# Minimal — turn on autocompaction with API defaults
response = client.beta.messages.create(
model="claude-opus-4-7",
max_tokens=16000,
betas=["compact-2026-01-12", "computer-use-2025-11-24"],
context_management={"edits": [{"type": "compact_20260112"}]},
messages=[...],
tools=[...],
)
# Customized — set your own trigger threshold and summarization prompt
response = client.beta.messages.create(
model="claude-opus-4-7",
max_tokens=16000,
betas=["compact-2026-01-12", "computer-use-2025-11-24"],
context_management={
"edits": [
{
"type": "compact_20260112",
"trigger": {"type": "input_tokens", "value": 150_000},
"instructions": COMPACT_PROMPT,
}
]
},
messages=[...],
tools=[...],
)在客户端截断以与服务端保持一致
当 API 运行一次服务端压缩时,它会在自己那一侧替换掉压缩前的内容,但你本地的消息数组仍然持有完整的历史。如果你在之后的每一轮继续发送完整历史,你就会为服务端不再需要的 token 付费,而且你的滚动缓冲修剪器所操作的消息切片,会与服务端实际看到的不同,这可能破坏你在上文精心维护的缓存稳定前缀。
修复办法是在客户端镜像服务端的截断,如下面的代码片段所示。当响应报告发生了压缩时,在下一轮之前,把本地消息数组中压缩标记之前的一切都丢弃掉。这能让客户端与服务端的视图保持一致,并让滚动缓冲继续正确工作。
def truncate_to_last_compaction(messages, response):
"""If the server compacted on this turn, drop pre-compaction messages
locally so the next turn's cache prefix matches what the server sees."""
context_mgmt = getattr(response, "context_management", None)
if not context_mgmt or not context_mgmt.get("applied_edits"):
return messages
compaction = next(
(e for e in context_mgmt["applied_edits"] if e["type"] == "compact"),
None,
)
if compaction is None:
return messages
keep_from = compaction["message_index_after_compaction"]
return messages[keep_from:]客户端压缩
如果你使用的模型不支持服务端压缩,或者你想要完全的控制权,那就用同一个提示词在客户端实现压缩。在每次 API 调用之后,从响应的 usage 字段检查总输入 token 数。当它越过一个阈值(例如,上下文窗口的 90%)时,把对话发送给一个摘要模型,并以 COMPACT_PROMPT 作为系统提示词。用摘要加上少量近期截图替换消息历史,然后继续智能体循环。
整合运用
一个长时运行的计算机操作智能体,其良好的默认配置如下:
- 一个缓存断点放在稳定前缀上,三个放在末尾的工具结果上,每轮清除并重新放置。
- 缓存感知的滚动缓冲,keep_n = 3,interval = 25,分批把较旧的截图替换为占位符。
- 服务端压缩在输入 token 达到 150k 左右时触发,配一个自定义提示词,再加一道客户端截断来让两侧视图保持一致。
这三个层次到位之后,一个典型的长跨度计算机操作会话会在绝大多数轮次上命中提示缓存,让总输入 token 保持远低于上下文窗口的有界状态,并在压缩事件中保留足够的历史,使智能体不会跟丢任务。
改善计算机与浏览器操作的实验性设置
下面这些范式是我们一直在自己的实现中测试的技术,它们展现出潜力,但还不是普遍适用的推荐。每一种都以复杂度或成本为代价,换取在特定类型工作负载上的潜在提升。我们把它们收录于此,让你可以在自己的工作流上试一试,但请预期本节的指导意见会很快演变。
批处理工具
在更新后的参考实现中,我们在标准的计算机工具和浏览器工具之外又暴露了两个工具:computer_batch 和 browser_batch。它们各自接受一个子动作列表,并在单次工具调用中执行这些动作。举例来说,模型可以发出一个包含点击、输入、按键这三个动作的 computer_batch 调用,而不必分成三个独立的轮次。
它的吸引力在于效率:一个含 N 个机械动作的工作流变成单次往返,而非 N 次往返,这在长跨度任务上能显著减少实际耗时和输出 token 开销。风险在于误差累积——如果动作 2 依赖于动作 1 所改变的视觉状态,而动作 1 落空了,批处理的其余部分就会基于过时的假设运行,智能体可能一路漂移,却始终看不到实际状态的截图。
我们建议,当子动作彼此自包含、不依赖对方的视觉结果时,使用批处理工具(在表单中填写多个字段、串接键盘快捷键、滚动并点击一个已知目标)。我们会在探索性导航、错误恢复序列,或任何「如果动作 1 失败我就需要重新规划」属于真实状态的工作流中避免使用它们。
由于批处理工具是你自己的自定义定义,它们能与标准的计算机工具或浏览器工具干净地叠加。把两者都保持可用,让模型自己选择。
顾问工具(beta)
顾问工具把一个执行者模型与一个更高智能的顾问模型配对,执行者可以在生成过程中咨询顾问以获取战略性指导。执行者运行循环,当它遇到需要更深推理的情况时,就调用顾问,收到一份计划或方向修正,然后继续。这一切发生在服务端、在单个请求之内,你这一侧没有额外的往返。
具体到计算机操作,这一范式在长跨度任务上最有用——那些大多数轮次都是机械点击、但偶尔会有规划时刻(选择打开哪个标签页、从意料之外的模态框中恢复、决定是否放弃一个策略)从 Opus 级别推理中受益的任务。你能获得接近「顾问单独作业」的质量,而绝大部分 token 生成发生在执行者的费率上。
启用顾问工具的示例:
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=16000,
betas=["advisor-tool-2026-03-01", "computer-use-2025-11-24"],
tools=[
{
"type": "advisor_20260301",
"name": "advisor",
"model": "claude-opus-4-7",
},
{
"type": "computer_20251124",
"name": "computer",
"display_width_px": 1280,
"display_height_px": 720,
},
],
messages=[...],
)顾问工具有用的控制项包括:
max_uses: 限定每个请求的顾问调用次数。当你想为最坏情况的成本设上界时很有用。- 你的 Harness 中的会话级上限: 顾问每次咨询都按 Opus 4.7 的费率计费,所以在非常长的会话中,你可能希望在若干次使用之后就不再提供顾问。
- 顾问侧缓存: 在多次调用的对话中,缓存顾问的前缀在大约三次咨询之后就开始划算。在参考实现中我们默认采用 5 分钟的临时缓存。
有两件不那么显而易见、但值得了解的事:顾问运行时不带工具、也不带上下文管理,所以它无法替你点击或浏览,只会返回文本建议。还有,由于执行者模型在长跨度任务上并不总是记得顾问的存在,请参阅下文的提醒推送一节。
清理被孤立的顾问块
当顾问工具触发时,执行者会发出一个 name 为 “advisor” 的 server_tool_use 块,紧接着在返回内容中是一个 advisor_tool_result 块。这些块与其他一切一起存在于你的消息数组中。
如果你之后从 tools 数组中移除了顾问工具——因为你触及了会话级上限、改了配置,或切换了模型——那些先前的 server_tool_use / advisor_tool_result 块就会变成孤立块。API 会在下一个请求上返回 400,因为被引用的工具不再被声明。
修复办法是一道简单的发送前遍历:每当某一轮禁用顾问时,遍历消息历史,剥除任何类型为 server_tool_use(且 name == “advisor”)和 advisor_tool_result 的内容块。
移除过时顾问块的示例:
def strip_orphaned_advisor_blocks(messages):
"""Remove advisor server_tool_use / tool_result blocks from history.
Call this before any request that doesn't include the advisor tool."""
for msg in messages:
content = msg.get("content")
if not isinstance(content, list):
continue
msg["content"] = [
block for block in content
if not (
isinstance(block, dict)
and (
(block.get("type") == "server_tool_use"
and block.get("name") == "advisor")
or block.get("type") == "advisor_tool_result"
)
)
]
return messages周期性提醒推送
在长会话中,执行者模型可能会忘记有哪些工具可用,或者它应该优先用哪些。有两种简短的提醒范式在我们的测试中起到了帮助:
批处理提醒。 如果你在标准工具之外暴露了 computer_batch 或 browser_batch,又观察到模型在适合批处理时却仍在串接单动作调用,那就在下一个工具结果之后追加一条简短的系统级推送:「记住,当多个连续动作不依赖中间截图时,你可以使用 computer_batch 把它们合并进单次工具调用。」目的是把模型拉回到批处理的方向,而不规定具体何时使用。
顾问提醒。 顾问工具很容易被执行者忘记其存在,尤其是当它已经许多轮没被调用时。在超过约 20 轮没有顾问调用的会话上,追加一条简短的提醒,说明顾问可在规划或方向修正的时刻使用。在参考实现中,我们采用 20 轮的节奏,并追加一行单句提示。
这两种推送都是轻触式的上下文注入,而非系统提示词的重写。它们每次追加耗费几十个输入 token。如果你的系统提示词已经很长,或者你的缓存断点放置得很精确,请权衡这点提升是否值得增加的失效风险。
参考实现中的调试范式
当某些东西行为失常、而你又不确定问题出在你的 Harness、你的截图还是模型身上时,参考实现中有三个辅助工具值得在你开始添加日志之前先用上:
- 轨迹查看器(streamlit run viewer/app.py)。 加载一条录制的轨迹,让你逐轮浏览智能体的过程,附带每一步的截图、思考、工具调用和用量。最适合在一次失败的运行之后回答「模型实际看到了什么,又做了什么决定?」。
- 工具调试面板(uvicorn debug.server:app —reload)。 一个小型 Web UI,让你单独操练每个工具:截图、捕获点击坐标、输入、滚动、缩放。用于确认你的捕获流水线和坐标缩放是否真的产出了你所期望的东西。
- 定位试验场(uvicorn localize.server:app —reload —port 8001)。 上传任意图像,让模型指出一个目标。它会把预测出的坐标在显示分辨率和原生分辨率两种尺度下回绘到你的图像上。这是诊断一次点击失误究竟是缩放 bug、坐标缩放 bug,还是真正的模型错误的最快方式。当某位客户报告点击不准、而你想在隔离环境中复现故障时,它尤其有用。
这些工具没有一个是构建一个可用集成所必需的;它们是当默认反馈循环(记日志、重跑、眯着眼看对话记录)不够快时的调试辅助。
提升可靠性:教 Claude
与其在文本提示词上反复迭代直到 Claude 把一个工作流做对,你可以直接向它展示正确的行为。录下你自己执行任务的过程,捕获每一步的截图、动作,以及可选的语音旁白,然后在 Claude 执行同一工作流时把这段演示作为上下文回放。这段录制就成了一份可复用的规范,Claude 可以遵循它,并适应实时 UI 状态中的差异。
我们在 Claude in Chrome 中内部使用这一范式(我们称之为「教学模式」),并在此分享,因为其底层方法对任何构建计算机操作或浏览器操作产品的人都有广泛的用处。它在两个方面提供帮助:提升 Claude 大体能应对、但偶尔出错的工作流的可靠性,以及解锁 Claude 仅凭文本提示词无法完成的全新工作流。其核心思想(捕获一段演示、再作为上下文喂回)实现起来很直接,并能很好地适应浏览器和桌面两种环境。
核心理念:展示而非描述
传统的提示词工程要求用户用文字描述他们想要什么,然后在 AI 误解时反复迭代。这一范式把它反转过来:用户演示任务,而系统录制他们的动作、截图,以及(可选的)语音旁白。在回放期间,Claude 收到完整的演示作为上下文,并遵循同样的步骤序列,适应当前 UI 状态中的任何差异。
关键的洞察在于,回放并非严格的重放。Claude 把演示当作一份指引,同时对实时环境进行推理。如果一个按钮移动了位置,或一个菜单被重新组织过,Claude 能在当前 UI 中找到等效的元素,而非盲目地在录制的坐标上点击。
数据模型
最基本的单元是一个「工作流步骤」——录制期间捕获的单个动作。每个步骤打包了做了什么、在哪里发生,以及屏幕当时是什么样子:
from dataclasses import dataclass, field
from typing import Literal, Optional
@dataclass
class WorkflowStep:
action: Literal["click", "type", "navigate", "scroll", "select"]
description: str # Human-readable, e.g. "Click the Submit button"
timestamp: float
selector: Optional[str] = None # CSS selector or XPath
coordinates: Optional[dict] = None # {"x": int, "y": int}
url: Optional[str] = None
screenshot: Optional[str] = None # Base64-encoded screenshot
viewport_dimensions: Optional[dict] = None # {"width": int, "height": int}
speech_transcript: Optional[str] = None # Voice narration, if captured
value: Optional[str] = None # For type actions
@dataclass
class SavedWorkflow:
id: str
name: str # e.g. "Submit expense report"
steps: list[WorkflowStep] = field(default_factory=list)
description: Optional[str] = None # AI-generated summary of the workflow
start_url: Optional[str] = None
created_at: float = 0.0
usage_count: int = 0同时捕获选择器和坐标是有意为之的:选择器对布局变化更稳健,但坐标提供了一个视觉回退,当选择器失效时 Claude 可以用它。视口尺寸被存储下来,是为了当回放环境与录制环境不同时可以缩放坐标。
录制:该捕获什么
至少要捕获点击事件、键盘输入、导航变化,以及每个动作处的一张截图。对每次点击,生成一段人类可读的描述(来自 aria-label、文本内容,或通过一次快速的 Claude 调用),并在截图上的点击位置标注一个视觉标记:
def on_click(event):
step = WorkflowStep(
action="click",
selector=generate_selector(event.target),
coordinates={"x": event.client_x, "y": event.client_y},
url=current_url(),
description=generate_description(event.target),
timestamp=now(),
viewport_dimensions=get_viewport_size(),
)
# Annotate screenshot with a circle at the click position
screenshot = capture_screenshot()
step.screenshot = annotate_with_circle(screenshot, event.client_x, event.client_y)
workflow_steps.append(step)这个标注(点击位置处的一个有色圆圈)有两个用途:它帮助用户核实录制是否捕获了正确的元素,而在回放期间,它向 Claude 准确地显示动作发生在何处。你的回放提示词应当讲清楚,这些标记是录制的产物,并非实时 UI 的一部分。
回放:构造提示词
这是最重要的一环。当用户触发一个已保存的工作流时,你要构造一条发给 Claude 的消息,其中包含三样东西:用户的意图、一个解释演示格式的上下文块,以及录制的截图。
上下文块告诉 Claude 如何解读带标注的截图,以及当实时 UI 出现差异时如何适应:
def generate_playback_context(steps: list[WorkflowStep]) -> str:
steps_description = "\n".join(
f"Step {i+1}: {step.description}"
for i, step in enumerate(steps)
)
return f"""<demonstration_context>
The user has recorded a demonstration showing how to perform this task.
RECORDED STEPS:
{steps_description}
ABOUT THE SCREENSHOTS:
- Each screenshot shows the screen state when an action was taken
- BLUE CIRCLES mark where the user clicked — these are recording annotations
- The blue highlighting is NOT part of the actual interface
- Your own screenshots will NOT have these markers
HOW TO USE THIS DEMONSTRATION:
1. Review all steps and screenshots to understand the complete workflow
2. Take your own screenshot to see the CURRENT page state
3. The blue highlights show which element to interact with — find it in your current view
4. Follow the same sequence of actions, adapting to any differences
5. If the UI has changed significantly, use judgment to find equivalent elements
</demonstration_context>"""然后把完整的消息组装起来,包含用户的提示词、上下文块,以及每个步骤的截图作为图像:
import anthropic
client = anthropic.Anthropic()
content = [
{"type": "text", "text": user_prompt},
{"type": "text", "text": generate_playback_context(workflow.steps)},
]
for i, step in enumerate(workflow.steps):
if step.screenshot:
content.append({"type": "text", "text": f"[Step {i+1}: {step.description}]"})
content.append({
"type": "image",
"source": {"type": "base64", "media_type": "image/jpeg", "data": step.screenshot},
})
response = client.beta.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
betas=["computer-use-2025-11-24"],
messages=[{"role": "user", "content": content}],
tools=[{
"type": "computer_20251124",
"name": "computer",
"display_width_px": 1280,
"display_height_px": 720,
}],
)回放模式
并非每个工作流都需要对录制演示保持同等程度的遵循。有些工作流过长,会消耗大量输入 token,最终拖慢延迟并推高成本。可以考虑支持一个严格度参数,把它包含在上下文提示词中:
严格(Strict): 严格按步骤执行;如果 UI 变化太大就停下并报告。适合那些精确序列至关重要、对合规敏感的工作流。
自适应(Adaptive): 把演示当作指引,但适应 UI 的变化。对大多数使用场景而言这是最佳的默认值——它能优雅地应对轻微的布局变动、更新过的按钮标签,以及重新组织过的菜单。
目标导向(Goal-oriented): 聚焦于最终结果;把录制的步骤当作提示而非指令。当 UI 频繁变化但目标保持不变时很有用。用一个模型来对录制的演示做摘要,使用与下一节所述类似的策略,然后把那份摘要传给计算机操作模型。
示例:端到端的费用报销工作流
这里是一个已保存的工作流在实践中的样子。这个工作流捕获了五个步骤:导航到费用表单、选择一个费用类型、从下拉菜单中选「差旅」、输入一个金额,以及点击提交。
expense_workflow = SavedWorkflow(
id="wf_abc123",
name="Submit Expense Report",
start_url="https://expenses.company.com/new",
steps=[
WorkflowStep(
action="navigate",
url="https://expenses.company.com/new",
description="Navigate to new expense form",
timestamp=1700000000,
),
WorkflowStep(
action="click",
selector="#expense-type-dropdown",
coordinates={"x": 400, "y": 200},
description="Click on expense type dropdown",
timestamp=1700000001,
),
WorkflowStep(
action="click",
selector="[data-value='travel']",
coordinates={"x": 400, "y": 280},
description='Select "Travel" expense type',
timestamp=1700000002,
),
WorkflowStep(
action="type",
selector="#amount-input",
value="150.00",
description="Enter expense amount",
timestamp=1700000003,
),
WorkflowStep(
action="click",
selector="#submit-expense-btn",
coordinates={"x": 1150, "y": 420},
description="Click the Submit button",
speech_transcript="Now I'll click submit to send the report for approval",
timestamp=1700000004,
),
],
)当用户之后说「为团队午餐提交我的费用报销(85.50 美元)」时,回放服务会构造一个提示词,包含演示上下文、全部五张带标注的截图,以及来自新请求的具体数值。Claude 准确地看到该在哪里点击、该遵循什么序列,并把金额和描述调整为与当前任务匹配。如果你的工作流因输入 token 数过多而长到让这种做法不再实用,那就考虑先对工作流做压缩,再把它用作示例。关于管理上下文的技巧,参见下一节。
开始使用计算机与浏览器操作
这些实践反映了我们目前对「什么让计算机操作集成在生产环境中可靠」的最佳理解。它们适用于 Claude 4.6 模型系列和 Opus 4.7,并将随着新模型和新技术的出现而更新。
随着你的集成日趋成熟,最要紧的范式将取决于你的具体环境、目标应用和可靠性要求。
从计算机操作文档开始上手,看看我们这些最佳实践的全新演示实现,或者重温最初的计算机操作研究文章,了解这些能力是如何构建的、又将走向何方。
致谢:本文及对应的演示由 Lucas Gonzalez 和 Luca Weihs 撰写。作者感谢 Molly Vorwerck、Javier Rando、Maya Nielan、Gabe Mulley 和 Brigit Brown 的贡献。
相关笔记
- 构建 Claude Code 的经验教训:提示缓存就是一切 —— 提示缓存的原理,与本文的缓存断点策略呼应
- Claude Code 会话管理与百万上下文 —— 会话边界与上下文管理的工程实践
- 长时间运行智能体的高效编排框架 —— 长程智能体的 Harness 设计
- 多智能体协调模式:五种方案及其适用场景 —— 编排者 + 子智能体模式的更多形态
- 生产环境中的 AI 智能体监控 —— 智能体行为的监控与日志记录