核心思想
AHE(智能体 Harness 工程)冻结底层模型不动,靠三层可观测性(组件 / 经验 / 决策)自动进化编程智能体的工具、中间件、记忆等七类周边组件——把每次编辑当作「可证伪的契约」,预测不兑现就自动按文件回滚。十轮迭代把 pass@1 从 69.7% 抬到 77.0%,击败所有人工调校的 Harness。最反直觉的发现:单独编辑系统提示词反而让分数掉 2.3 分;真正改变结果的是工具实现与中间件层的执行期强制,而非提示词里写的告诫。进化好的 Harness 还能跨模型迁移,且越弱的底层模型收益越大。

一篇新论文让编程智能体自动进化自己的工具、中间件和记忆。在 32 小时内,它击败了所有人工调校的 Harness。
单独靠系统提示词,反而会退化。 如果把编辑系统提示词当作唯一可调的适配面,在 Terminal-Bench 2 上 pass@1 会掉 2.3 分。
AHE(Agentic Harness Engineering,智能体 Harness 工程)就是得出这一发现的框架。它把底层模型冻结不动,针对采样运行(rollout)自动进化全部七类 Harness 组件,让一个只有 bash 工具的种子 Harness 在十轮迭代里从 69.7% 提升到 77.0%。
最终结果在同一组 89 个任务的面板上、用时 32 小时,击败了人工设计的 Codex-CLI(71.9%)、只进化提示词的自进化框架 ACE(68.9%),以及轨迹反馈基线 TF-GRPO(72.3%)。
迁移效果是把进化好的工作区原封不动地搬过去:在 SWE-bench-verified 上 token 消耗减少 12%,在另外四个模型家族上带来 +5.1 到 +10.1 个百分点的增益,其中最弱的底层模型收益最大。
「如果你刚才没太跟上开头那段,那你真该看看我们的 Harness 工程工作坊。就算你全程跟上了,也照样值得去瞧一眼!」更多细节见文末。

背景
这篇论文由 Jiahang Lin、Shichun Liu、Chengjun Pan 以及来自 Fudan University、Peking University 和 Shanghai Qiji Zhifeng 的合作者共同撰写,题为《Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses》(arXiv 2604.25850,2026 年 4 月 28 日,代码采用 MIT 许可证)。
编程智能体的 Harness,指的是模型周围的一切:系统提示词、工具定义、中间件、Skill、子智能体、记忆。生产团队靠人工调校这些东西——检视轨迹、编辑文件。这种手工循环很慢,而且收益分散在一堆没有记录的决策里。
此前的自动化工作每次只优化一个组件,几乎总是提示词或某种上下文内的「操作手册」(ACE、GEPA、DSPy),要么就是轨迹分布(TF-GRPO 及各种 GRPO 变体)。工具、中间件和记忆始终是封闭的。
AHE 把整个 Harness 当作一个组合式的整体来进化,并把每一次编辑都视为一份可证伪的契约,用下一轮任务的结果来验证它。
AHE 如何运作
整套设计的核心一招是:循环的每个阶段都产出结构化、文件级的产物,供另一个智能体读取。
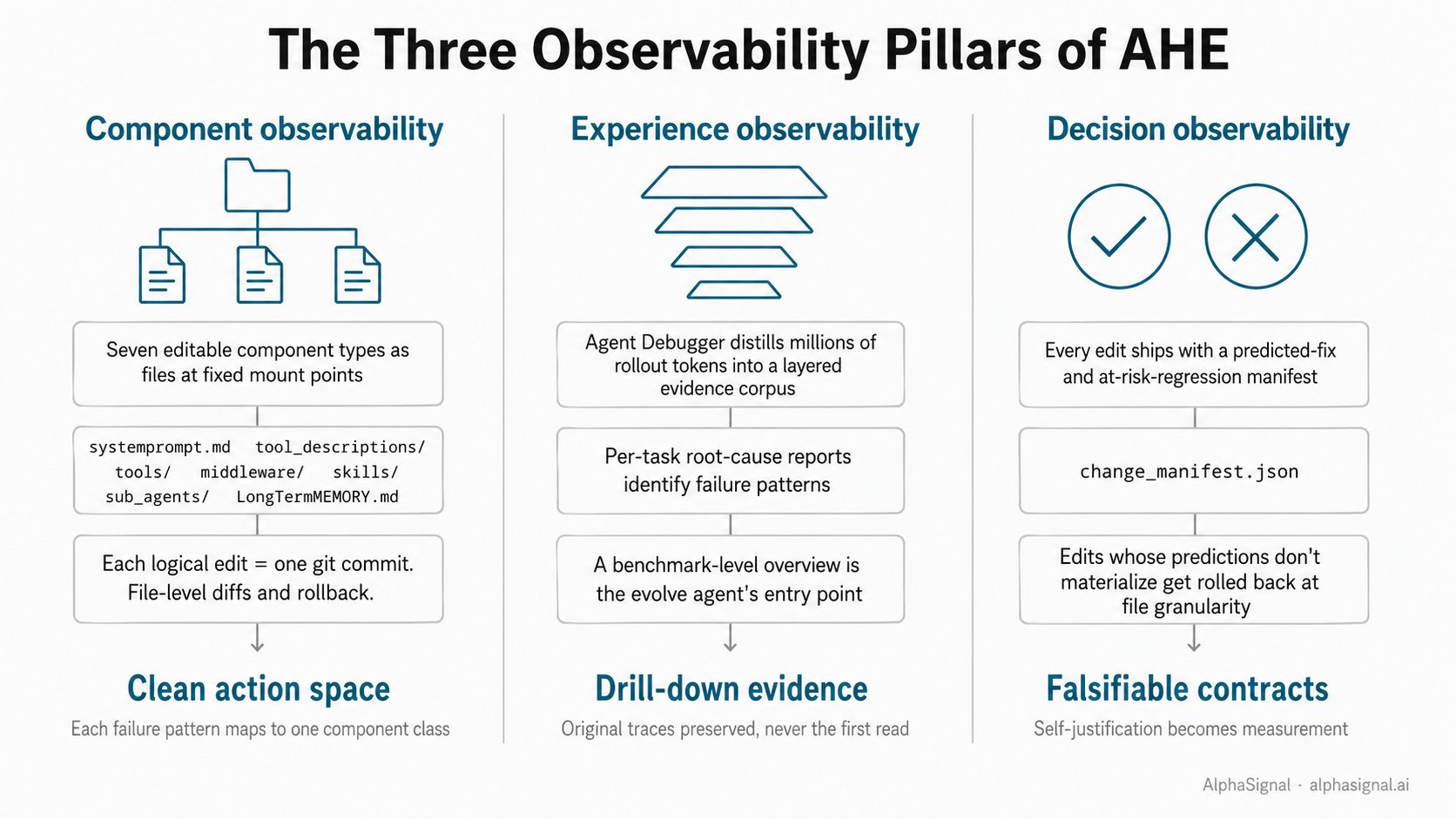
组件可观测性。 这套 Harness 构建在 NexAU 框架之上,该框架把七类可编辑的组件以文件形式暴露在固定的挂载点上:系统提示词、工具描述、工具实现、中间件、Skill、子智能体配置,以及长期记忆。每一种失败模式都能干净地对应到某一类组件。每一次逻辑上的编辑都成为一次 git 提交,于是文件级的 diff 和回滚天然就有了。
种子 Harness 被刻意做得极简——只有一个 bash 工具,没有中间件也没有 Skill,因此循环新增的每个组件都必须靠实测的采样运行来证明自己存在的价值。
经验可观测性。 Agent Debugger 框架把原始的采样运行轨迹(动辄数百万 token)蒸馏成一份分层的证据语料。每一条轨迹消息都存在自己的文件里。逐任务的根因报告则识别出失败模式。
一份基准级别的总览把所有报告聚合到进化智能体的入口处。原始轨迹仍然可供查证,但永远不是第一手要读的东西。
决策可观测性。 每一次编辑都附带一条 change_manifest.json 记录,写明它要解决的失败模式、预测会修复的任务、有风险的回归,以及约束级别(提示词、工具描述、工具实现、中间件、Skill)。
到了下一轮,循环会把预测的修复与回归同观测到的任务级变化求交集。预测没有兑现的编辑会被自动按文件粒度回滚。自我辩护就此变成了实测。
外层循环
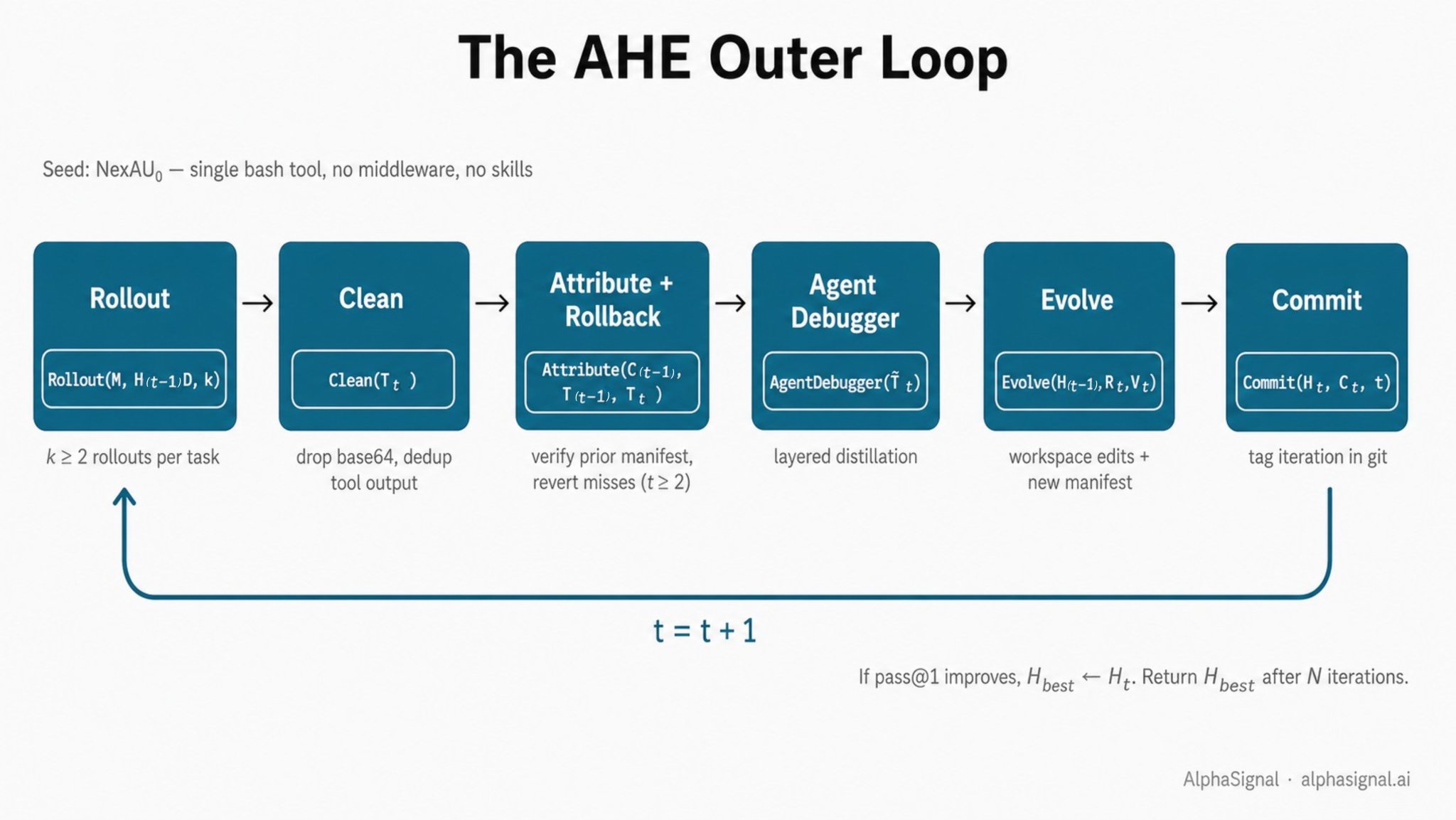
朴素版的伪代码收录在文末的附录小节。
这里有一个承重的选择:归因发生在蒸馏之前。先前编辑的判决结果会落进进化智能体要读的证据语料里,把每条清单记录绑定成一份契约,而非一段事后说辞。
进化智能体只能在 workspace/ 内部写入。runs 目录、tracer、verifier 和 LLM 配置都是只读的。种子系统提示词不可删除。
这些限制堵住了一个不受约束的自我修改器会走的捷径——比如关掉 verifier,或者抬高推理预算——并保证每一笔被记录的收益都能归因到 Harness 编辑上。
证据
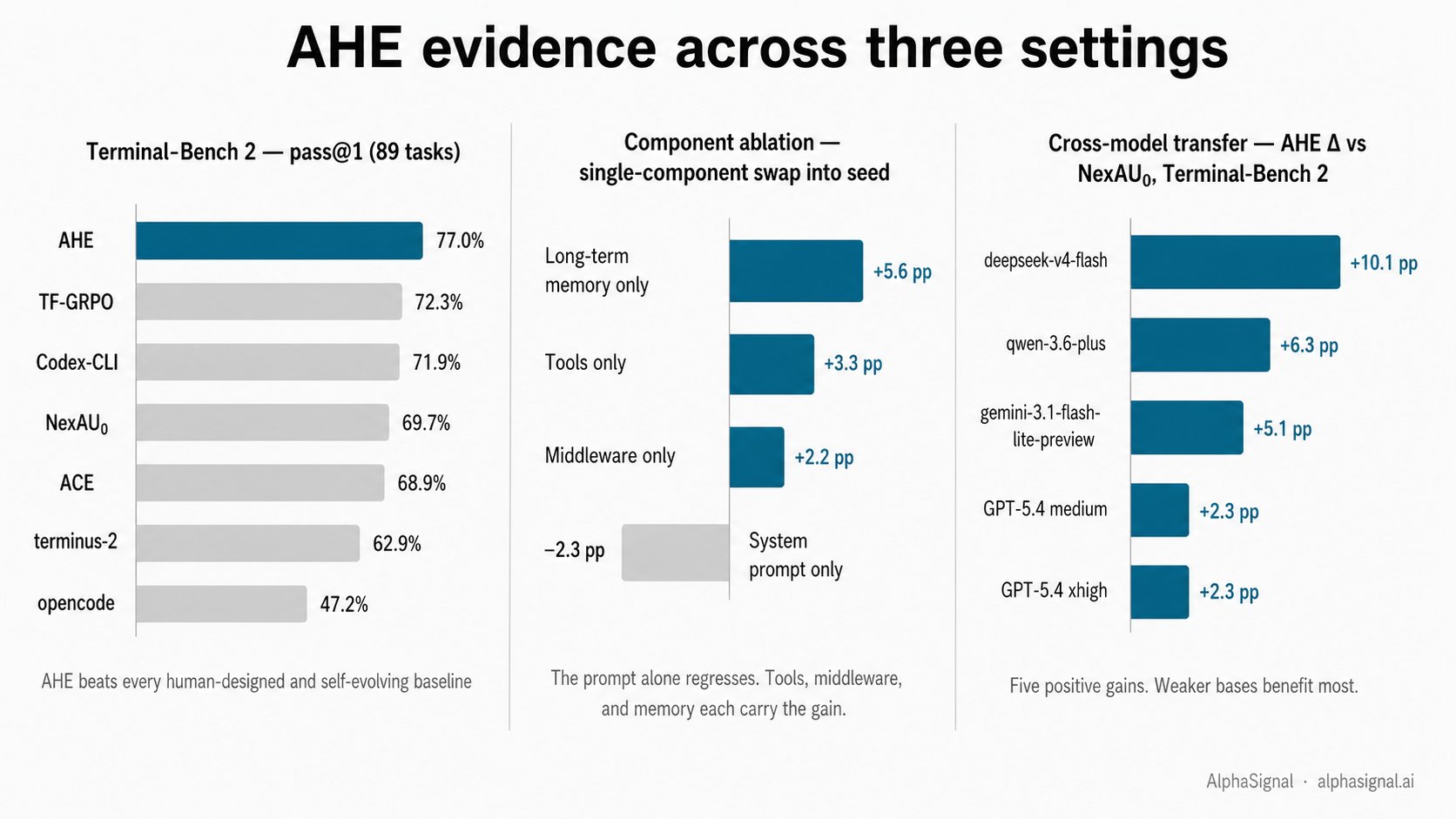
在 Terminal-Bench 2 上跑十轮 AHE 迭代(89 个任务,k=2 次采样运行,GPT-5.4 高推理档,总运行时长约 32 小时),pass@1 从 69.7% 提升到 77.0%。AHE 跑赢了三个人工设计的 Harness(opencode 47.2%、terminus-2 62.9%、Codex-CLI 71.9%),也跑赢了两个自进化基线(ACE 68.9%、TF-GRPO 72.3%)。
在简单档和中等档上,AHE 干净利落地领先。在困难档上它滑落到 53.3%,落后于 Codex-CLI 的 56.7%——根源是组件之间的相互干扰,而非能力缺失。
跨基准的迁移无需重新进化也能成立。在 SWE-bench-verified 上(500 个任务,横跨七个代码仓库),AHE 拿到了 75.6% 的最高总成绩,同时比种子少花 12% 的 token,比 TF-GRPO 少 21%,比 ACE 少 32%。
收益集中在 django 和 sphinx-doc 这两个最大、最耗 token 的仓库上。在 SWE-bench 上的成本效率(成功数 / 百万 token):AHE 1.64,NexAU₀ 1.43,TF-GRPO 1.27,ACE 1.10。
跨模型迁移是「Harness 编码了通用工程经验」这一点最有力的证据。同一个进化好的工作区,原封不动地在五个备选底层模型上评测,产生了五个正向增益:deepseek-v4-flash 上 +10.1pp(51.7→61.8),qwen-3.6-plus 上 +6.3pp(56.2→62.5),gemini-3.1-flash-lite-preview 上 +5.1pp(36.5→41.6),以及 GPT-5.4 中等档和 xhigh 档上各 +2.3pp。
越弱的底层模型受益越多,因为它们要倚靠 AHE 已经固化进工具、中间件和记忆里的协调模式。越强的底层模型则能轻松地从提示词里重新推导出同样的协调。
组件消融实验是承重的那个发现。把单个 AHE 组件换进只有 bash 的种子里:只加记忆 +5.6pp,只加工具 +3.3pp,只加中间件 +2.2pp,只加系统提示词 −2.3pp。ACE 和 TF-GRPO 从不去编辑的那些 Harness 组件,恰恰就是收益所在之处。
四个案例研究
论文追踪了四条轨迹,记录它们在第 2、5、6、8 轮迭代里从失败走向修复的过程。「迄今最佳」曲线上的每一个峰值,都对应着其中一条轨迹。

db-wal-recovery(第 2 轮迭代)。 智能体需要从一份损坏的预写日志中重建一个 SQLite 数据库。失败的那次采样运行从一个猜出来的规律(value = id × 100)里凭空造出了缺失的行,并且只按行数自检,而不去对照 verifier 的值断言。
修复方案是往系统提示词里追加 68 行内容,含八条编号规则:先看契约、照搬评估器的判定、在不过拟合可见样本的前提下做泛化。这些规则没有一条提到 SQLite、WAL 或这个任务。它们本是为另一簇部分通过的任务提出的,却被意外地带了过来——结果让 db-wal-recovery 从 1/2 翻转到 2/2,并在此后每一轮迭代里都稳住在 2/2。
path-tracing(第 5 轮迭代)。 智能体渲染出了一张正确的图像,自检通过,接着把 rm -rf 当作收尾整理的最后一步执行,并以这条清理命令的退出码来提交。verifier 在磁盘上什么也没找到,于是拒绝了这次采样运行。种子提示词里其实已经有「不要破坏已验证状态」的告诫,但没有任何执行期机制去强制它。
第 5 轮的修复在 shell 工具内部装上了一道发布状态守卫:当 shell 观察到一次成功的、评估器风格的检查时,它会解析验收命令里受保护的路径,并拦截之后的删除操作。任务从 0/2 翻转到 2/2。
mcmc-sampling-stan(第 6 轮迭代)。 智能体通过网格积分算出了一个假的后验分布,把真正的 MCMC 运行作为后台作业启动,又在它收敛之前「为了保住交付物」把它杀掉,然后提交了那个假结果。这个失败连续出现了五轮。
第 6 轮靠两个组件协同把它解决了:发布状态守卫被扩展到能保护脚本入口点(analysis.R),同时新增一个 ExecutionRiskHintsMiddleware,盯着实时的命令历史,监视七种跨步骤的风险模式(代理式验证器、浅层验证、只查 localhost、对着同一个错误反复重试,等等)。任务从 0/2 翻转到 2/2 并稳定下来。
configure-git-webserver(第 8 轮迭代)。 智能体搭起了一个能正常工作的 web 服务器,通过 localhost 的 curl 自检通过,接着执行了一串以 ALLOW_POST_SUCCESS_RESET 为前缀的清理命令,把活着的 web 根目录抹掉、把 git 引用重置,「好给评分留下一个干净的仓库」。外部 verifier 收到的是一个 404。
第 8 轮给那个覆盖令牌打了补丁:删除受保护的产物、重置受保护的根目录,都变成了硬性拦截,那个令牌再也无法越过。一个 before_model 钩子把执行风险警告升格成 FRAMEWORK 提醒,让它在模型的下一个回合可见。第 8 轮的总分达到 76.97,是整轮运行的最高水位。
四个案例贯穿始终的模式是:提示词说的是「该避免什么」,但真正改变结果的,是执行期的强制约束。四个胜出的修复里,有三个落在了工具实现或中间件这一层。
局限
困难档退步。 在困难档上,AHE 以微小差距落后于 Codex-CLI(53.3% 对 56.7%)。记忆、中间件和系统提示词全都朝着同一种收尾确认式的验证用力,这会把回合预算花在冗余的反复复查上。把 AHE 的长期记忆单独换进种子里(不带其他组件),就已经在困难档上超过了 Codex。
组件交互的非加性。 三个单组件的正向增益相加是 +11.1pp,但完整的 AHE 只达到 +7.3pp。把这些组件叠在一起要付出 3.8pp 的代价。进化智能体优化的是一个由 55 个中等任务主导的聚合指标,所以它收敛到了一个偏向中等档的折中方案,把困难档记忆效应的一部分还了回去。
回归盲区。 横跨九轮评测,进化智能体给出了 43 条不重复的回归预测,只有 5 条命中(精确率 11.6%)。实际发生了 40 次未被预见的回归(召回率 11.1%)。修复预测比随机高 5 倍,回归预测勉强只比随机高 2 倍。
智能体能说清一次编辑为什么应该有帮助。但它说不准同一次编辑会弄坏什么。
基准范围。 完整的进化运行是在 Terminal-Bench 2 上做的。跨基准和跨模型的迁移证据令人鼓舞,但能彻底消除「刷榜」疑虑的,是一次不在 Terminal-Bench 2 上做的进化运行。作者标出了这一点,并把它点名为一个泛化风险。
所以最好的建议是:把 AHE 当作一个受控的研究原型——它已经能产出一个值得研究的冻结 Harness——同时等一等在第二个基准上的进化运行结果,再决定是否把这套框架当作部署级的自我改进循环来采用。
AlphaSignal 观点
值得关注。这套框架做到了它所宣称的,那些「证据」(变更清单 + 自动回滚)用实测取代了自我辩护,而跨模型迁移是迄今最强的信号,表明 Harness 的结构编码了较弱底层模型无法廉价重新推导出来的协调模式。
两块尚未完成的拼图,是回归盲区这道缺口,以及一次第二基准上的进化运行。补上任意一块,都能把它从研究原型推向部署级。
值得留意的前瞻性主体是 NexAU——这个循环赖以运行的底座,因为这套框架能触及多远,取决于有多少生产环境的智能体采用它那套文件级的组件契约。
谁受益,谁不受益
受益的: 在多步骤终端或仓库工作流上运行长程编程智能体的团队;任何在「粗糙的初版之后」还在人工调校提示词的人;正在评估自进化循环、想找微调替代方案的 ML 工程师;以及研究「无需梯度更新的测试期适配面」的研究者。
略过的: 智能体循环属于短程 API 调用链的团队;手上没有采样运行轨迹、也没有二元通过/失败信号 verifier 的人;以及已经投入只进化提示词的框架(ACE、GEPA、DSPy)、无法打开收益所在的那些 Harness 组件的团队。
从业者启示
ML 工程师现在可以针对一个基准测试,自动进化编程智能体的工具、中间件和记忆——因为可观测性的基础设施把每一次组件编辑都变成了一份可证伪的契约。
工作坊
我们将举办一场关于 Harness 工程的分享,主题是超越简单的提示词与上下文。它讲的是如何构建那些让智能体能自主工作的约束。
5 月 14 日,太平洋时间上午 11 点。由 AJ Joobandi(Augment Code)主讲。20 个名额,150 美元。
你将学到智能体为什么会出问题、如何设计稳健的成功指标,并带走一个开箱即用的 Harness 文件。
→ 抢占席位:点这里

链接
- arXiv 上的论文(论文,约 45 分钟阅读)
- GitHub 仓库(代码,MIT 许可证)
- Agent Debugger 博客(背景,约 10 分钟阅读)
- NexAU 框架(循环赖以运行的底座)
关注 @AlphaSignalAI 获取更多此类内容。
订阅 AlphaSignal.ai 获取每日 AI 信号。28 万多名开发者在读。
附录
Algorithm 1: AHE outer loop
H_best ← H₀ # bash-only NexAU₀ seed
for t = 1 to N do
T_t ← Rollout(M, H_{t-1}, D, k) # phase 1: k≥2 rollouts per task
T̃_t ← Clean(T_t) # phase 2: drop base64, dedup tool output
if t ≥ 2 then # phase 3: attribute prior manifest, then rollback
V_t ← Attribute(C_{t-1}, T_{t-1}, T_t)
H_{t-1} ← Rollback(H_{t-1}, V_t)
R_t ← AgentDebugger(T̃_t) # phase 4: layered distillation
(H_t, C_t) ← Evolve(H_{t-1}, R_t, V_t) # phase 5: workspace edits + new manifest
Commit(H_t, C_t, t) # phase 6: tag iteration in git
if Pass@1(T_t) > Pass@1(H_best) then
H_best ← H_t
return H_best相关笔记
- Harness 工程:智能体时代真正的护城河 —— 为何 Harness 结构本身就是护城河,与本文跨模型迁移的发现呼应
- 解剖智能体Harness —— Harness 七类组件的概念拆解
- Harness 工程:在智能体优先的世界里驾驭 Codex —— 人工做 Harness 工程的实践视角
- Agent Hooks:智能体工作流的确定性控制 —— 「执行期强制」的具体形态:Hook 与中间件
- 长时间运行智能体的高效编排框架 —— 长程智能体的 Harness 设计原则