核心思想
标准智能体 RL 把终端输出 token 当作上下文「读了就扔」。ECHO 提出一个混合目标——在动作 token 上跑原来的 GRPO 损失、同时在终端输出 token 上加一项简单的交叉熵——几行代码、零额外 rollout、几乎零额外算力,却让 TerminalBench-2.0 pass@1 翻倍、训练加速 2.3 倍、可替代专家 SFT,甚至撑得起无验证器自我改进。更深的暗示是:智能体的每一次失败 rollout 都自带监督——只要这些输出是「系统状态变化的有信息投影」。 代价是要平衡 λ 与目标 token 的选择。

与 @VaishShrivas 合著
我们教 CLI 智能体在 RL 训练时顺手预测终端响应,跟常规的 GRPO 动作损失放在一起。改动极其微小:同样的 rollout、同样的前向传播,只是不再把终端输出 token 掩蔽掉。效果却很惊人:所有评测都提升,训练出来的模型还能可度量地学到终端的行为方式。
CLI 智能体可以免费学到终端模型——并且利用它做得更好!
这就是 ECHO:一个混合目标,同时训练交互的两侧——智能体写出来的内容,以及终端回写的内容。
原帖含一段动画,演示动作 token 与终端输出 token 的混合训练流程。

如果你没时间读完整篇,这里是我们的发现:
- 标准智能体 RL 把环境响应扔掉了。 GRPO 只在动作 token 上训练,把终端响应掩蔽掉,尽管这些 token 已经在上下文里、已经过模型、并且是「智能体行动如何影响环境」的 ground truth 信号。
- ECHO 通过同时训练交互两侧来修复这个问题。 它保留对动作 token 的标准 GRPO 损失,并在终端输出 token 上加一个简单的环境交叉熵损失。它在任何 GRPO 训练器上只需要几行代码。同样的 rollout 和前向传播,只是在 logits 上换了个掩码。
- ECHO 真的有效,而且免费! ECHO 在我们测试的所有基准上都改进了 Qwen3-8B、OpenThinker-Agent-v1-SFT 和 Qwen3-14B。要达到同样性能,ECHO 训练速度快了最多 2.3 倍。TerminalBench-2.0 pass@1 在 8B(2.7 → 5.2)和 14B(5.2 → 10.8)上几乎翻倍。
- ECHO 教会模型终端动态! 在留存轨迹上,环境 token 的交叉熵随 ECHO 训练大幅下降,而普通 GRPO 几乎没动。这是 ECHO 教会了模型「终端实际如何响应」的直接证据。能更准预测终端输出的同一批 checkpoint,也能解决更多任务。
- ECHO 可以替代专家教师。 从一个没有任何专家演示的基座 Qwen3-8B 出发,ECHO 几乎追平了「GRPO + 专家演示 SFT」的成绩。
- ECHO 让智能体在没有验证器奖励的情况下也能自我改进! 在完全没有验证器奖励的设定里,纯 ECHO(连 GRPO 都不要)只靠「行动 + 预测后果」就能让智能体进一步变强。
这一切起源于一个简单问题:既然每条命令都会产生终端响应,RL 为什么只在命令上训练?
Vaish 把这个想法落地的所有工作都做了。我贡献了一个无厘头的迷宫实验*、对标题的强硬意见,以及在她展示第一份结果时回了句「卧槽」。感谢 Ahmed Awadallah 给我们空间——以及 GPU——去追这种从「研究痒点」起步的想法。
值得一提的是:ECHO 的第一次集群训练运行,是 3 月 29 日启动的 😊
这项工作出自 AI Frontiers,微软研究院内部的一个小而精的研究实验室。
怎么样才算持续学习?
这个想法第一次冒头时,灵感来自一个关于自我改进和持续学习的简单问题:智能体仅靠在世界中行动,怎么变得更好?
我和 Vaish 从去年秋天就在讨论 CLI 智能体里的自我改进——也就是:「靠跟环境(也就是终端)交互来进步」是什么意思,尤其是在没有验证器的情况下。
无验证器 RL(verifier-free RL)是一个被研究了很多年的问题,大多数尝试都撞上同一堵墙:如果没有奖励,监督信号从哪儿来?
差不多同一时间,我一条无厘头的 twitter 帖子让我和 @willccbb 通了个电话,又聊到持续学习。聊天中我记得自己说了一句类似下面这样、听起来挺傻但其实有意思的话:
也许持续学习就是:训练在「环境对你动作的响应」上,不管它返回的是什么。
这应该能教会模型点东西,对吧?
事实证明,确实可以!
世界就是一个损失函数!
智能体在环境中行动,环境对那个动作的响应永远是真实的。
举个物理世界的例子:你按一下灯开关,灯要么亮,要么不亮。如果不亮,那也是一个合法的响应:它告诉你某些信息——可能是灯泡、可能是线路、可能是断路器,等等。无论是哪种情况,回来的都是一小段信息,说明世界因你的行动发生了什么变化。你没看到电流、开关、灯泡运作的完整机制,但你看到了结果。灯亮没亮?这足以让你开始构建「按开关让灯亮起来」的心智模型。
终端的工作方式差不多也是这样。
执行完一条 bash 命令之后的输出,是「这条命令执行后计算机/容器的状态如何变化」的一个小总结。你看到 stdout、stderr、退出码、文件列表等等。你看不到内核状态、进程树这种超细节的东西。
你看到的回应,是「幕后发生了什么」的一个低维投影——而这也正是 CLI 智能体用来决定下一步动作、推进任务的依据。和灯开关一样,这点信号足以构建一个心智模型——你想叫它世界模型也行——去描述系统的行为方式。
更妙的是,终端输出——再说一次,这是系统状态变化的反映——本身就是监督信号,每一步都被免费算给你了。
赞!
问题是,标准智能体 RL(比如 SkyRL 里的 GRPO)只在动作 token 上回传梯度,却忽略了终端输出 token。哪怕终端输出已经在上下文里——模型在注意它、前向传播在为它计算 logits——训练器却把它从 loss 里掩蔽掉。
多浪费这么好的 token 啊 😊
那如果我们不这么做呢?
模型本来就已经在这些 token 上做了条件分布,它本来就为它们产生了概率分布。再加一项交叉熵损失,基本上不花钱。
而如果我们这么做……模型就有动力学习终端真正怎么表现,从而在自己内部构建一个对所操作系统的隐式模型。要想预测终端会返回什么,模型必须记得自己刚创建了哪些文件、什么东西放在哪里,等等。
正如 Ilya 所说:
把下一个 token 预测得好,意味着你理解了导致那个 token 出现的底层现实。
放到我们的设定里,这就是说:一个能很好预测终端输出的智能体,在很小但很真实的意义上,已经在内部建好了一个终端的隐式模型。
那么我们怎么让智能体去预测终端输出呢?
ECHO:免费学一个世界模型
终端智能体的 rollout 本身就是两股 token 流交错出现的:智能体的动作 token,以及环境的观察 token。标准 GRPO 只在动作 token 上做 loss。
这特别浪费,因为终端奖励是稀疏的、延迟的、二元的。在我们 Qwen3-8B 的设定里,很多任务的 on-policy rollout 成功率不到 15%。但失败的轨迹并不是失败的数据:它们里面仍然有文件列表、报错、日志、堆栈轨迹、grep 输出,以及智能体命令带来的其他后果。
我们的方法,是从这些后果中学习的、简单到有点尴尬的方式 😊
我们在环境观察 token 上加了一项按长度归一化的交叉熵损失,跟标准的 GRPO 动作 loss 并列。ECHO 是这个混合目标:
L_{ECHO} = L_{GRPO}(\text{Actions}) + \lambda \cdot L_{env}(\text{Observations})其中 Actions 是智能体动作所在位置,Observations 是终端输出所在位置。
原帖含一段动画,演示混合损失同时对两类 token 起作用。

一些技术细节:
- ECHO 是 on-policy 学习。 ECHO 不是在某个固定的、由基座模型或教师生成的终端转录上训练,而是从 RL 过程中当前模型自己产出的终端响应里学习。智能体越变越好,它就探索环境的新区域、从新的「动作 → 观察」转移里拿到新鲜监督。更好的策略带来更好的反馈,更好的反馈预测又让策略拥有更好的动作先验。一个循环!多好玩?
- 混合目标里,λ 很关键。 太小,环境 loss 几乎不塑造模型;太大,策略会去优化「可预测的输出」而不是「任务进展」。得平衡一下!
- 目标 token 也很关键。 我们在真实终端输出上训练,而不是在 harness 警告上训练。警告很容易被记住,但有用的信号是实际终端响应——文件名、堆栈轨迹、报错信息。
那么这要付出什么代价?
机灵的读者会问:
既然在更多 token 位置回传梯度,反向传播不是更贵了吗?
几乎没贵多少。反向传播里贵的部分是注意力层和 MLP 层的矩阵乘法(matmul),这些跑的是同一段 token 序列,跟哪些输出位置进入 loss 无关。每个响应位置的 logits 早就为 GRPO 算好了。动作掩码和观察掩码,只是把它们的不同子集挑出来,喂给不同的 loss 项。
到这里停一下:我们加了一个世界建模损失,而代价基本上是零! 不用额外 rollout、不用教师模型、不用额外前向传播。
ECHO 真的训练出更强的 CLI 智能体了吗?
我们在多轮终端任务上做了能做得最干净的对照:相同的模型、相同的 GRPO 配方、相同的任务、相同的 rollout 和回合预算、相同的训练步数。智能体在 n 轮内通过测试用例则 Reward=1,否则 0。
唯一的区别是:终端输出 token 是否进入 loss。
粉色曲线是 ECHO,青绿色是 GRPO。无论模型大小、无论哪个评测切片,答案都一样:加入环境预测让智能体显著变强。
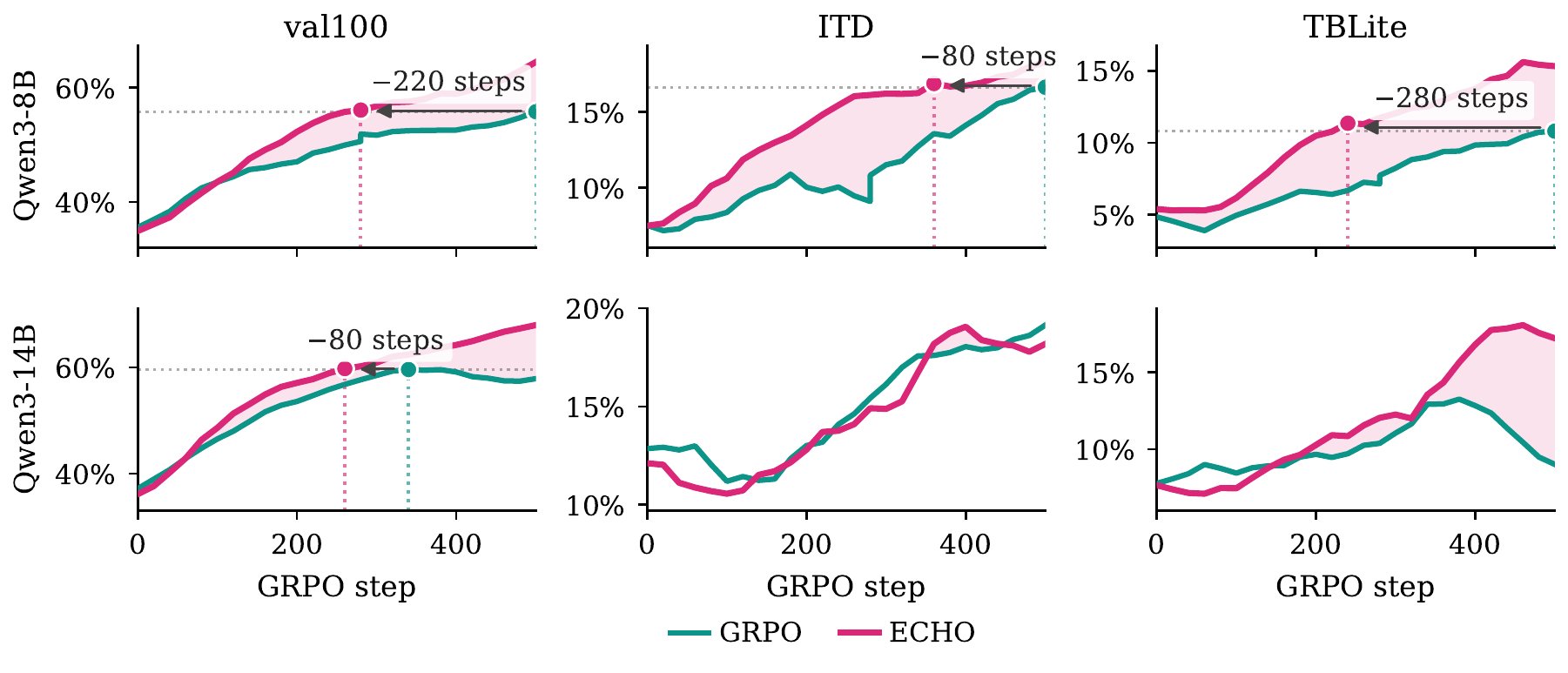
ECHO 在我们三个留存验证集上都一致提升性能——粉色曲线很早就跟青绿色分开,并且基本一直在上面。
ECHO 学得也快得多:在 Terminal-Bench Lite 上,ECHO 用比 GRPO 少 280 步的训练就追上了 GRPO 500 步的水平!2.3 倍加速,曲线还在往上走! 😊
这些结果坐实了我们对 ECHO 的直觉。GRPO 只用稀疏、二元的结果奖励来训练。对于像终端任务这种小模型通过率低的难领域,这意味着很多任务几乎拿不到信号。
ECHO 把失败的动作变成了监督,让训练的样本效率大幅提升。 即使某个动作没解决任务,终端响应仍然在教模型「这个动作造成了什么」!而预测失败动作的后果,反过来能帮助智能体选出更好的动作。
如果你更喜欢看跨评测的数字,故事在表格里同样成立:
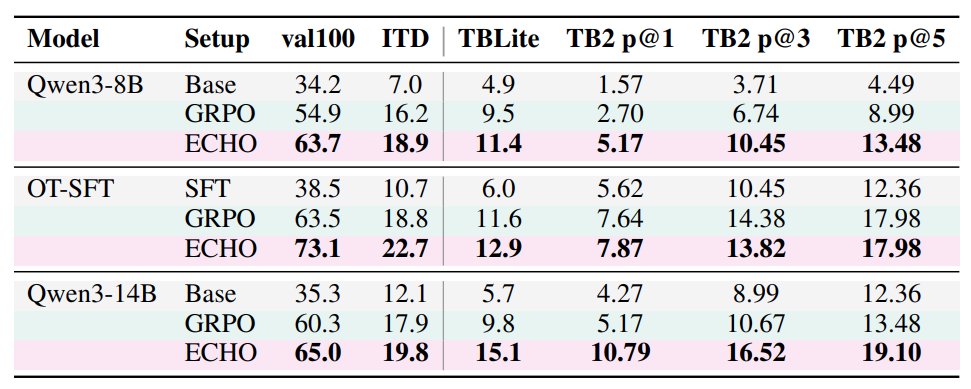
看每个 block 的最后一行:ECHO。TerminalBench-2.0 pass@1 在 8B(2.7 → 5.2)和 14B(5.2 → 10.8)规模上几乎翻倍。 重要的是,这不是靠多加数据、多加 rollout、多加教师模型或换验证器达成的。终端响应早就在 rollout 里了,ECHO 只是从中学习而已。
**「性能几乎翻倍而代价为零」,这是你整个科研生涯里都很少能写出来的一句话** 😊。
ECHO 在所有基准、所有模型尺寸上都大幅超过 GRPO,样本效率更高,而代价基本为零。你的策略在改进的同时,免费学到了一个世界模型,而这个世界模型反过来让策略改进得更快。
不过怀疑论者可能会反驳:你们真的学到了世界模型吗?
来看看!
ECHO 真的学到了终端动态吗?
这里我们要小心一点,因为搞世界模型那拨人有时挺较真。
我们不会主张 ECHO 在最强意义上学到了世界模型。但我们会主张:ECHO 训练出的策略,其隐藏状态已经吸收了一些关于「终端如何表现」的信息,并且它预测终端动作的能力可度量地变强了。
如果你把 Ilya 那句话反过来,就得到一个更可证伪的版本。对应到我们的场景,大概是这样:
如果模型学到了终端动态,它就必然很擅长预测终端输出。
因为没有别的办法能持续地把高概率分配给正确的 token。一个更好的预测器,在信息论意义上,就是一个对所预测系统更好的压缩器。
所以问题就变成了实证问题:ECHO 真的让模型变成了更好的终端输出预测器吗?
答案是:是的。而且差距很大。
为了让这个测试干净,我们用了一个更强的教师模型 Qwen 3 32B(它没有出现在我们的任何一次训练里)为每个验证集生成轨迹。然后我们评估了起始策略、用 GRPO 训练后的策略,以及用 ECHO 训练后的策略,衡量每个模型对生成的终端输出 token 有多「惊讶」。
每张图上的模式都一样:GRPO 几乎没改变环境 token 的交叉熵(相对于起始策略),ECHO 则把它显著拉低。
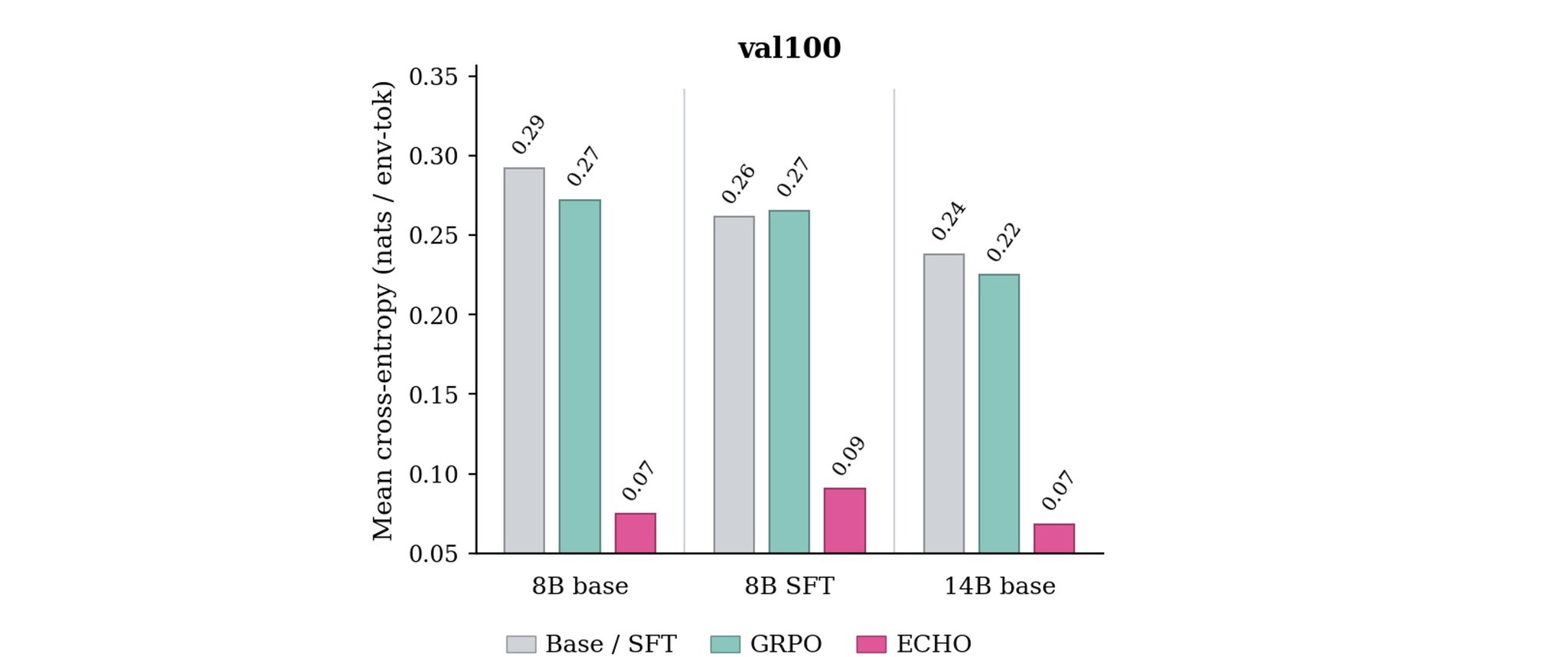
所以我们不会大写字母 W 地说「World Model」。但我们会说:
ECHO 训练出的策略,在它们自己没生成过的轨迹上,可度量地更擅长压缩终端动态。
这是标题主张的一种可操作版本,也是完全经得起验证的版本。
意外发现 1:ECHO 减少了对专家 SFT 的依赖
智能体 RL 一个常用的配方是:先从更强的模型那里行为克隆专家轨迹,再跑 RL。这在终端智能体上尤其常见,因为这种任务奖励稀疏、动作空间巨大。
在我们的设定里,专家 SFT 基线是 OpenThoughts-Agent-v1-SFT(OT-SFT):用更强的 GLM-4.6 教师生成的终端智能体演示,在 Qwen3-8B 上做的微调。
于是我们问:不去行为克隆教师,ECHO 能恢复多少专家 SFT 的好处?
ECHO 能让你跳过专家 SFT 吗?在我们的设定里,基本上能!
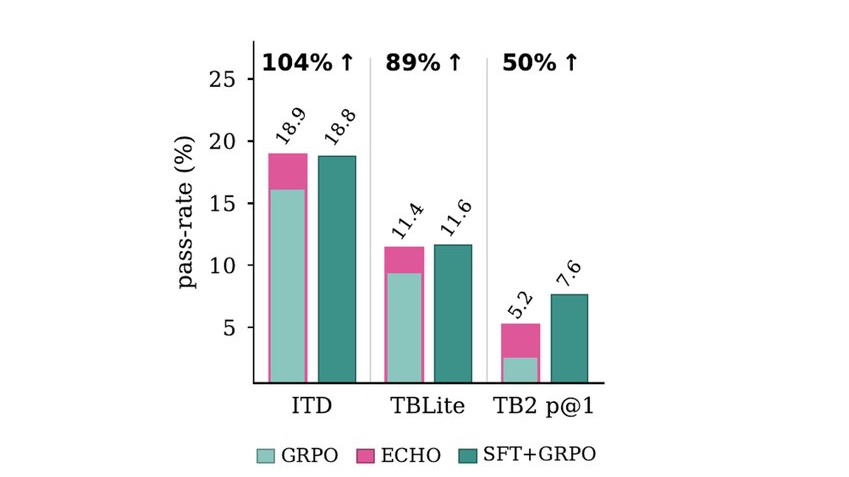
这张图比较了三个 run:基座模型上的纯 GRPO、基座模型上的 ECHO,以及 SFT 模型上的 GRPO(SFT + GRPO)。相对于 GRPO 和 SFT+GRPO 之间的差距(也就是 SFT 提供的增益),ECHO 恢复了 ITD 上 104% 的增益,Terminal Bench Lite(TBLite)上 89%,TerminalBench-2.0(TB2)pass@1 上 50%。
这个结果暗示:专家 SFT 价值的很大一部分,也许是来自于教模型一个交互先验,而不仅仅是一个专家策略先验。专家演示同时展示了两件事——「如何像终端智能体那样行事」(查文件、跑测试、跟着 traceback 走,等等),以及「专家在某些具体状态下会做什么」。ECHO 没有去模仿那些专家选择。它训练模型预测自己动作的终端后果,所以它学到的是:哪些命令能暴露有用的状态,哪些报错是诊断性的,哪些终端输出 token 标志着进展。更好的策略,可以通过交互而非模仿涌现出来。
这也帮我们理解评测的分布:在 ITD 和 TBLite 上,ECHO 几乎追平了专家 SFT,说明 SFT 的优势中很大一部分来自更好的终端交互模型。在 TB2 上,ECHO 在没有任何演示的情况下仍然恢复了 50% 的差距。剩下的差距,跟 TB2 更难、且分布上离训练集更远的事实是一致的。
我们不会把这当成一个固定的天花板:在 TB2 类任务上做更宽或更久的训练,应当让智能体进一步变强。
所以结论不是「专家 SFT 过时了」,而是:专家 SFT 的相当一部分价值,本质上是更好的终端交互模型,而这一部分可以直接从环境学到。
归根结底:终端就是老师!
意外发现 2:无奖励自我改进的火花
到目前为止,ECHO 一直是「GRPO + 一个辅助环境 loss」。验证器仍然告诉智能体它有没有解决任务,GRPO 仍然在动作 token 上更新模型。是标准的 RL 设定加一个小补丁。
但如果 ECHO 真的在教策略一些关于「终端如何表现」的东西,那也许我们根本不需要验证器信号。
我们问:把验证器关掉会怎么样? 没有奖励可学,只剩下这个:
L = L_{env}(\text{Observations})也就是说:模型行动、观察,只通过预测「自己动作所导致的终端输出」来更新。
这听起来不该提升任务性能。没有标签告诉哪个动作是好的。如果策略变好,那一定是因为「学习预测终端」间接重塑了策略的动作先验。
所以我们试了!
我们拿出最强的 Qwen3-8B+ECHO 检查点,把 GRPO 项完全去掉,只用环境交叉熵 loss 在留存任务上又训练了 100 步。问题是:仅靠跟环境交互、预测环境的回应,模型能在它从没见过的 OOD 任务上变好吗?
这个疯狂的想法成了吗?算是吧!
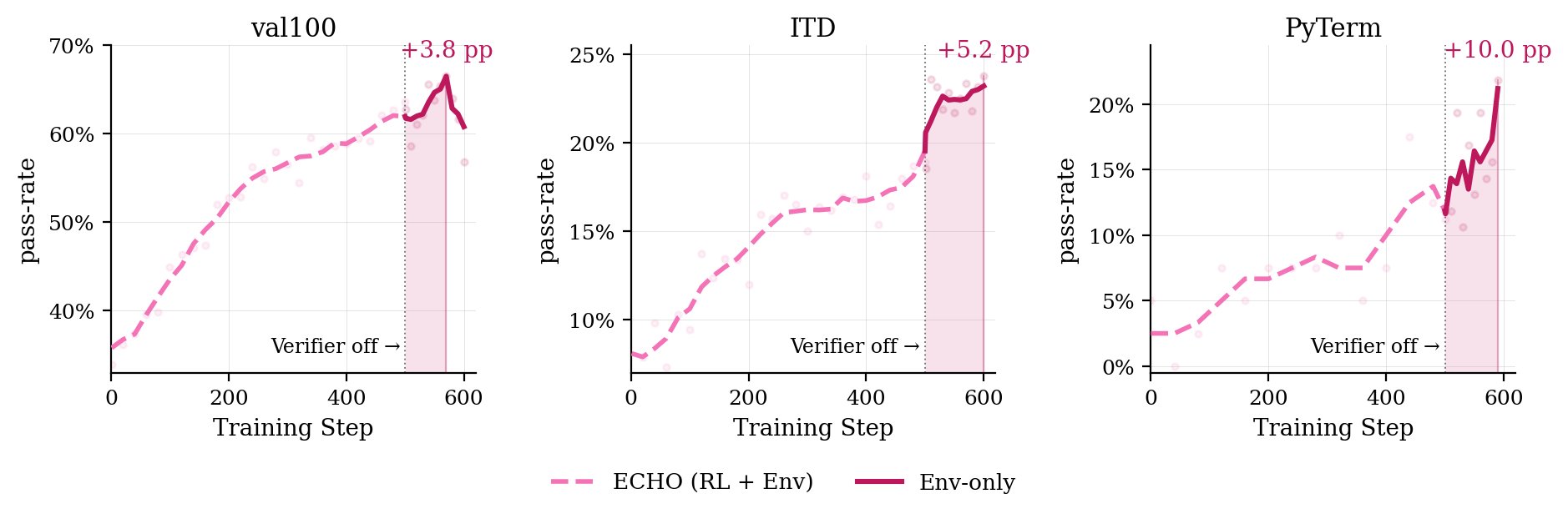
在 val100(分布内)上:+3.8 pp。在 ITD 上:+5.2 pp。在 PyTerm(留存的 Python 重型终端任务集)上,过滤到干净的工具调用轨迹后:+10.0 pp。
仅环境训练能改进策略的前提是:终端输出本身是有用的监督。没有奖励信号,模型只为「预测自己动作所导致的输出」而训练,所以收益取决于这些输出是否暴露出有用的动态。
在 val100 上——它跟训练集分布接近——增益是真实的但不大:+3.8 pp,然后就饱和。策略在 ECHO 训练阶段已经学到了大部分局部动态。
在 ITD 上,起始策略较弱,产生的轨迹噪声较大——无效命令、解析错误、死循环。过滤到干净 rollout 能去噪,得到 +5.2 pp。
不过光是干净轨迹还不够。同样的过滤在 TBLite 上没有一致提升,而 PyTerm 从相近的通过率出发,却在同样配方下得到提升——这说明瓶颈不只是策略强弱。关键差别在于「观察的信息量」:Python 任务给出密集的、跟动作紧密绑定的反馈——「代码 → traceback → 修复」——而更广义的终端任务则通过文件、配置、多步骤搭建间接暴露状态。
我们认为,无验证器适配是可能的:一旦 RL 训练出一个不错的探索模型,智能体有时可以仅凭「行动的后果」继续改进——但前提是它的 rollout 必须干净,且终端反馈必须有信息。这才是意外的部分。不是「智能体能完美自我改进」,而是「它真的能自我改进」——除了行动和预测反馈,什么都没有。
这把我们带到哪儿了
ECHO 的核心教训很简单:智能体的 rollout 里包含的监督信号,远不止最终的奖励——我们应该把它用起来。
智能体跑的每条命令都产生终端响应——stdout、错误、堆栈、文件、日志,等等——而标准 RL 只把这些 token 当作下一步动作的上下文。ECHO 把它们变成训练目标。不用教师模型、不用额外 rollout、不用单独的世界模型。我们只是不再把转录里已经在那儿的环境 token 扔掉。
这点小改动带来三个意外结果:更强的 RL 性能、对专家 SFT 的依赖大幅下降,以及在某些设定下、仅靠环境交互的无验证器自我改进。我们不认为这意味着奖励或演示过时了。专家轨迹仍然在教智能体怎么操作,而验证器提供了最干净的任务级信号。但 ECHO 说明:介于「模仿专家」和「等待稀疏奖励」之间,还有一种密集而严重利用不足的监督——智能体自己动作的后果。
更宏观地看,这个想法是辅助预测的延续,辅助预测在 RL 里有很长历史。最近的工作也在为 LLM 智能体重启世界建模目标,例如 Agent Learning via Early Experience 把动作-后果信号当作 RL 前的预阶段,VAGEN 给 VLM 智能体加了一个世界建模奖励,RWML 在「下一状态预测」上做预训练,CWM 在「观察-动作」轨迹上对一个代码模型做 mid-training。ECHO 就是这个思路的在线、嵌在 RL 循环里、CLI 口味的版本。
这个想法能走多远?
下一步是让这个环境信号更有力,并测试它能泛化多远。ECHO 用的是原始终端输出,因为它们本来就在 rollout 里;但最好的学习目标也许是更干净、更紧凑的表示——比如状态的摘要或任务相关视图。还有:我们应该在哪些观察上训练?什么时候应该过滤轨迹?如何在环境预测和策略优化之间分配权重?同样的想法能不能在终端之外起作用——浏览器智能体、多工具系统、长时编程智能体,或者面向用户的助手?用户的追问、纠正、偏好,也是一种交互反馈。
我们的赌注是:只要智能体在行动、世界以 token 形式回应,这些响应 token——或它们更好的表示——就应当成为学习信号的一部分。ECHO 是我们能想到的「这种想法」的最简版本;我们怀疑某种形式的环境 token 预测,会在 2026 年底之前成为智能体 RL 训练器的标配。
试试 ECHO,告诉我们你的智能体训练快了多少。
*脚注:在我的笔记本上训练一个迷宫世界模型……算是吧
记得我说自己「贡献了一个无厘头的迷宫实验」吗?就是下面这个。
设定是 ECHO 的微缩版:一个小终端里的网格迷宫。智能体(一个 10M 的 transformer 在循环里跑)发出方向——上、下、左、右——终端就告诉它,它相对于「邻居」的位置(基本上就是个 2D 网格里的寻路问题),以及到目的地的距离。这样 rollout 看起来就和 CLI 智能体的 rollout 一样(对于小尺度的「一样」),只是简单很多 😊:动作 → 环境响应 → 动作 → 环境响应,如此循环。
我在一个从零开始训练的 10M 参数 transformer 上测试了两个条件:1)只在动作 token 上训练;2)同时在动作 token 和终端响应(邻居、距离等)上训练。所有训练都用全新的 6×6 / 7×7 / 8×8 迷宫。
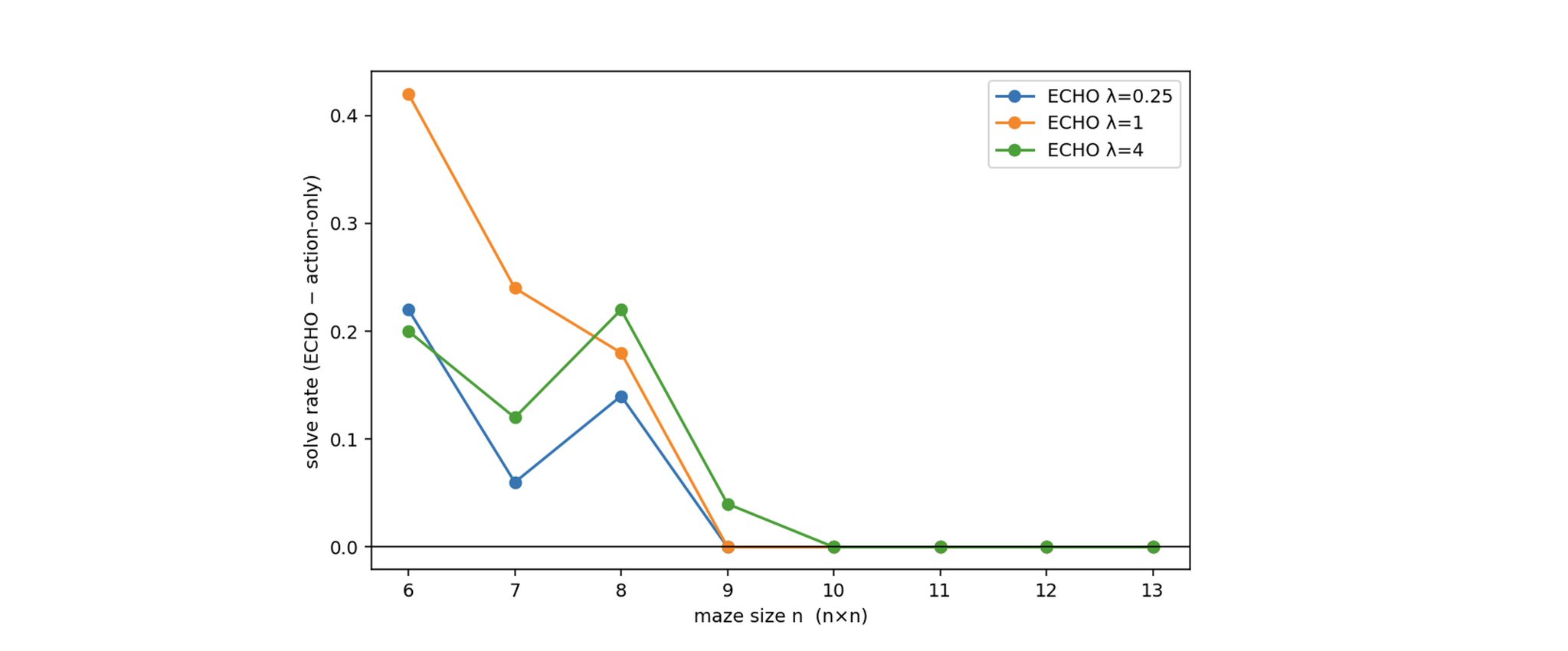
这是按迷宫尺寸画的 |ECHO − 只训练动作| 的解题率。正数表示在同样计算量下,ECHO 比只训练动作的基线解出了更多迷宫。这张无厘头的图基本上是在说:ECHO 在迷宫上有效。
这迷宫小玩意儿是 Nature 论文吗?当然不是。但我一直在反复表达一个观点,而它一直在被验证:
几乎每个干净的想法都有一个微观版本:一个小到能在一个晚上跑在笔记本上的缩小版,告诉你这个想法值不值得放大。
迷宫没能证明 ECHO 一定可行,只是给了我足够的把握给 Vaish 发一条 Teams 消息,而不是把这个想法忘掉。结果发现 Vaish 自己也在独立思考类似的事;当她第一次集群跑出来的结果回来时,我又兴奋又真的惊讶。ECHO 迷宫只是暗示了方向是对的,它没法预测「TerminalBench 翻倍」「恢复大部分专家 SFT」「无奖励自我改进」这种结论——那些都是 Vaish 的成果。「算是解了 6×6 迷宫」和「在 TerminalBench 上翻倍」是非常不同的认知状态。
但这条附录的重点,不是说笔记本能取代集群实验。重点是:我大部分想法都是错的,而笔记本实验(配合 Claude Code 和 Codex)告诉我哪些可以先扔掉,免得浪费别人的时间。偶尔,有个想法活下来了——一旦它活了下来,也许就配得上某位合作者的时间和 GPU。
ECHO 就是其中之一。
相关笔记
- 解剖智能体Harness:从执行循环、状态、提示词的角度系统拆解 harness 内部结构
- Harness 工程:智能体时代真正的护城河:harness 工程为何是当下智能体竞争的核心
- 不碰模型与提示词,让编程智能体更聪明:在 harness 层而非模型/提示工程层提升智能体能力
- LLM 中的 KV 缓存:原理与权衡:理解 ECHO 为何「几乎零额外算力」的底层视角
- Claude Code 会话管理与百万上下文:rollout 越来越长时,状态如何留住