
核心思想
智能体 = 模型 + Harness。如果你不是模型,那你就是 Harness。**一个普通模型配上出色的 Harness,稳稳压过出色模型配上糟糕的 Harness。** 真正的工程门槛不在选模型,而在沉淀一套”由失败史塑造的脚手架”——把每次错误都升格为一条
AGENTS.md规则、一个钩子或一个子智能体。模型变强,Harness 不会缩水,只会迁移到下一段地平线。
编码智能体 = 模型 + 围绕它构建出来的一切。Harness(脚手架)工程把这层支架当作一个有生命的工件,每次智能体犯错就拧紧一次。
说白了:智能体每失败一次,你就用工程化的方式给它打上一个永久补丁,让它再也不会犯一模一样的错。
过去两年,行业一直在围着模型转:哪个最聪明、哪个写出来的 React 最干净、哪个幻觉最少。这种讨论当然重要,但它丢掉了系统的另一半。
模型只是一个正在运行的智能体的输入之一。其余部分才是 Harness——包裹在模型外面的提示词、工具、上下文策略、钩子、沙箱、子智能体、反馈循环和恢复路径,让模型真正能把任务做完。
一个普通模型配上出色的 Harness,稳稳压过出色模型配上糟糕的 Harness。 越来越多最有意思的工程工作,重点已经不在选模型,而在设计模型外面的那层脚手架。
这门门道现在有了名字。@Vtrivedy10 提出了 harness engineering 这个术语,干净利落地拆解了一个 Harness 到底是什么、每一块为什么存在。其他业内人士也在汇合到大致相同的判断:@dexhorthy 在追踪新兴模式,HumanLayer 把智能体失败重新定义为配置层面的「技能问题」,Anthropic 的工程团队在发布长跑应用的设计指南,Birgitta Böckeler 则在探索用户侧的体验。
这篇文章把这些线索串起来。
Harness 到底是什么
Trivedy 的核心定义本身就够给力:
智能体 = 模型 + Harness。如果你不是模型,那你就是 Harness。
Harness 涵盖除模型本身之外的所有代码、配置和执行逻辑。原始模型不是智能体。只有当 Harness 给它提供状态、工具执行、反馈循环和可强制执行的约束,它才成为智能体。
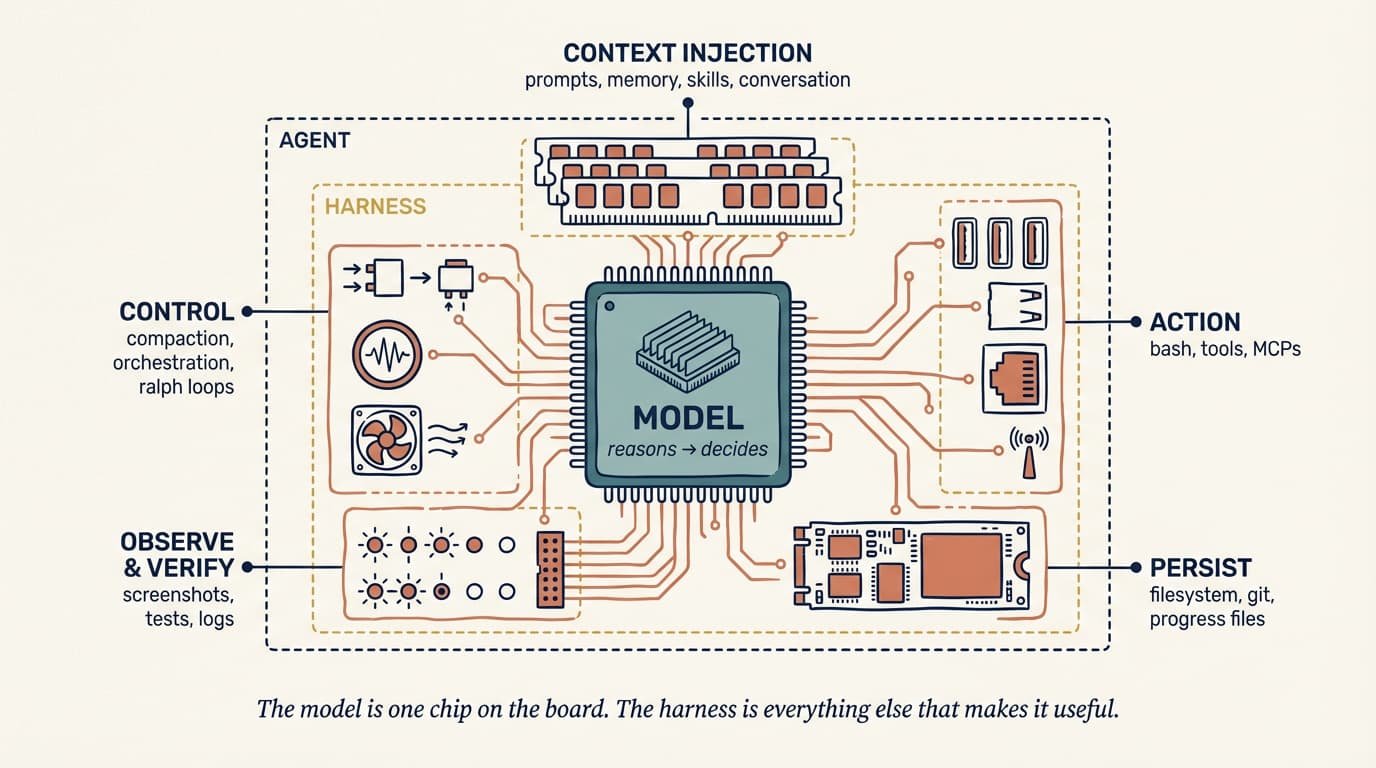
具体来说,一个 Harness 包含:
- 系统提示词、
CLAUDE.md、AGENTS.md、技能文件,以及子智能体指令。 - 工具、技能、MCP 服务器,以及它们的技术描述。
- 内置的基础设施,比如文件系统、沙箱和无头浏览器。
- 用于派生子智能体、处理任务交接、路由模型的编排逻辑。
- 用于确定性执行的钩子与中间件,比如 lint 检查或上下文压实。
- 用于日志、追踪、成本与延迟度量的可观测性工具。
本质上,智能体就是一个在循环里调用工具去达成目标的系统。真正的功夫,在于把工具和这个循环都设计好。
这是一个巨大的接触面,但它是你的接触面,不是模型供应商的。Claude Code、Cursor、Codex、Aider、Cline 全都是 Harness。底层模型在各平台之间可能完全相同,但你感知到的行为,几乎完全由 Harness 决定。
重新框定「技能问题」
工程师们常常在智能体干出蠢事时把锅甩给模型,把问题搁置为「等下个版本再修」。
Harness 工程的思路拒绝这种默认反应。失败大多是有迹可循的。如果智能体忽略了某个约定,把它写进 AGENTS.md。 如果它跑了一条破坏性命令,写一个钩子把它拦下。如果它在一个 40 步的任务里迷路,就把架构拆成规划器和执行器。如果它每次完工时代码都是坏的,给循环接上一条类型检查的反压信号。
正如 HumanLayer 所说:「这不是模型问题,这是配置问题。」看一下性能基准就明白:一个一线模型跑在开箱即用的框架里,分数往往远低于同一个模型跑在精心调过的定制 Harness 里。把模型搬进一个工具更完备、提示词更紧、反压更锋利的环境,能解锁原本被埋没的能力。
**模型「理论上能做的」与你看到它「实际在做的」之间的差距,大部分是 Harness 的差距。**
棘轮:每个错误都升格为规则
Harness 工程里最关键的习惯,是把智能体的每个错误当作永久信号——而不是「重试一下就忘」的偶发故障。
如果某次智能体提交的 PR 里有一行被注释掉的测试,结果还被合进了主干,那就是一份输入。下一版 AGENTS.md 必须写明:「禁止注释掉测试,要么删掉要么修好。」下一版 pre-commit 钩子要自动把 diff 里出现的 .skip( 标红。负责评审的子智能体要被升级,专门拦下被注释掉的测试。
约束只在你观察到真实失败之后才加,也只在某个足够能干的模型让它变得多余之后才删。一份好的系统提示词,每一行都应该能追溯到一次具体的、历史上发生过的失败。
正因为这样,Harness 工程是一门学科,而不是一个万能框架。一份适配某个特定代码库的 Harness,完全由它独一无二的失败史塑造。
从行为反推 Harness
设计 Harness 最有效的方法,是从想要的行为出发,再反向构建能交付它的组件:「想要的行为 → 设计出能达成它的 Harness」。
Harness 的每一块都必须有自己分内的活。如果你说不出某个组件是为什么具体行为而存在,那它就该被砍掉。
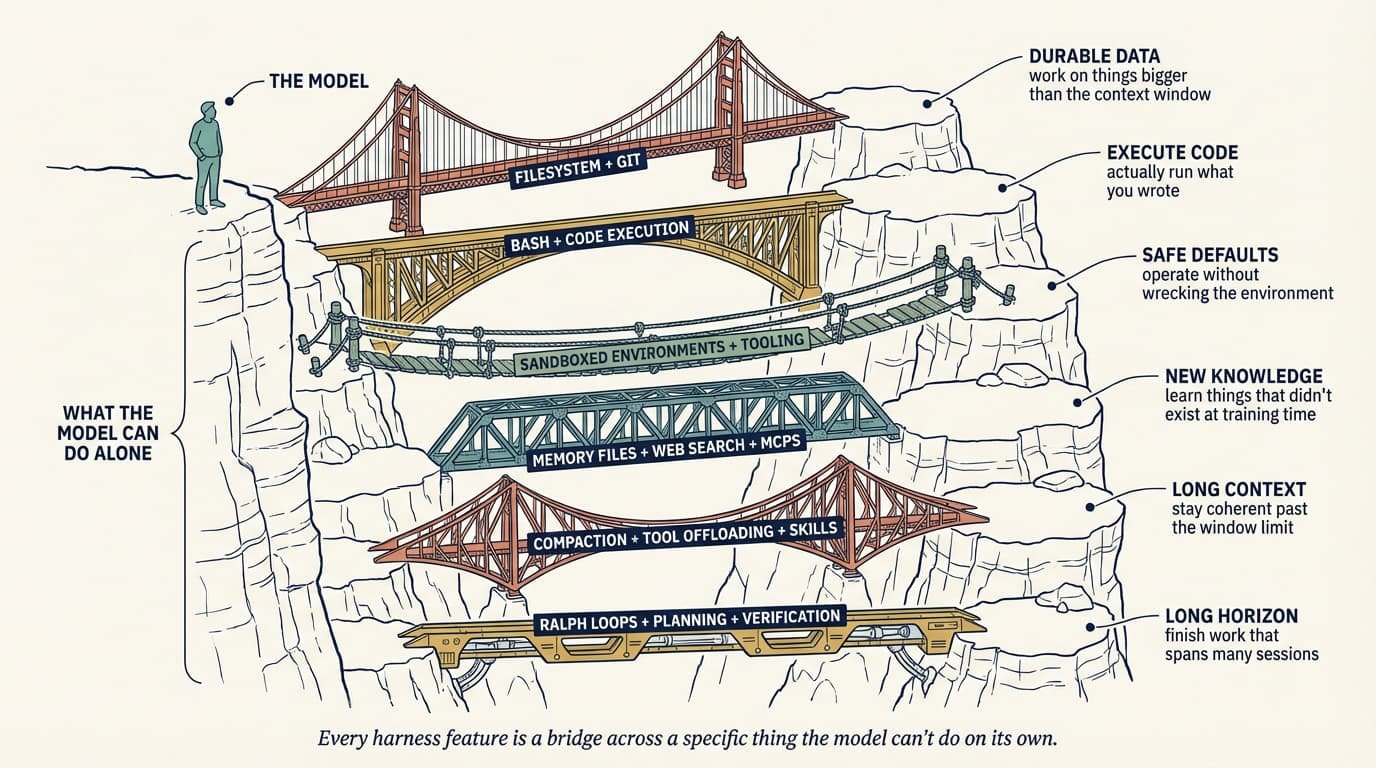
文件系统与 Git:持久化状态
文件系统是地基。模型只能处理装得进上下文窗口的内容。文件系统给智能体一个工作区去读数据、一个地方去寄存中间产物,以及一个让多个智能体协作的接触面。
加上 Git,就免费获得了版本管理,让智能体能记录进度、开实验分支、回滚出错的改动。
Bash 与代码执行:通用工具
大多数智能体跑在一个 ReAct 循环上:推理、通过工具调用执行动作、观察、重复。与其为每一种可能的动作都预先封装一个工具,不如直接给智能体 bash 权限,让它现场打造自己需要的东西。
智能体通常很擅长 shell 命令,这让 bash 和代码执行成为自主解题的默认策略。
沙箱与默认工具链
Bash 只有跑得安全才有用。沙箱给智能体一个隔离环境,让它能运行代码、检视文件、验证产出,而不会牵连宿主机。
一个好沙箱要自带强默认值:预装好的语言运行时、测试 CLI、无头浏览器,这样智能体才能观察自己的产出,闭合自我验证循环。
记忆与搜索:持续学习
模型除了训练权重和当前上下文之外,一无所知。Harness 用记忆文件(比如 AGENTS.md)填补这个缺口,把知识在每次会话开头注入进来。
对于实时信息——比如新的库版本或实时数据——网页搜索和 MCP 工具会被直接焊进 Harness 里。
对抗上下文腐烂
上下文窗口被填满的过程中,模型的推理会退化。Harness 用三种主要技术管理这种稀缺:
- 上下文压实: 智能地总结并卸载较旧的上下文,避免 API 报错。
- 工具调用卸载: 把工具的大块输出(比如 2000 行的日志)丢进文件系统,只在上下文里保留必要的头尾。
- 渐进式披露: 只在任务明确需要时才暴露相应的指令和工具,而不是在启动时一股脑全加载进来。
长周期执行
自主、长跑的任务最容易吃亏在「提前终止」和糟糕的问题分解上。Harness 用结构化设计反击:
- 循环: 拦截模型试图退出的动作,强制它在新鲜的上下文窗口里继续推进完成目标。
- 规划: 强制模型把目标拆成一份分步计划文件,每完成一步用自我验证钩子检查。
- 拆分: 把生成和评估拆给不同的智能体,避免模型给自己打分时天然带正向偏差。
钩子是你的执行层
钩子填补了「请求一个动作」与「真的强制它发生」之间的鸿沟。它们在特定生命周期触发:在工具调用之前、在文件编辑之后、在提交之前。钩子能拦下破坏性命令、强制自动格式化以节省 token、跑测试套件。
理想状态下,**成功是沉默的,失败是响亮的。** 类型检查通过,智能体什么都听不见;一旦失败,错误就被直接灌回循环,供它自我修正。
规则手册与工具的取舍
仓库根目录的一份扁平 markdown 文件,至今仍是撬动效果最大的配置点。但要把它当作飞行员的检查清单,而不是风格指南。保持精简,确保每条规则都是用过去的一次失败换来的。
工具同理。十个高度聚焦的工具,永远跑赢五十个互相重叠的工具。
更进一步,因为工具描述会被填进提示词,恶意或邋遢的外部集成(比如未经验证的 MCP 服务器)甚至可以在智能体开始干活之前,就给它注入坏提示。
生产环境里它长什么样
我见过的、关于一个成熟 Harness 最清晰的公开拆解,是 Fareed Khan 对 Claude Code 架构做的(估算式)剖析。
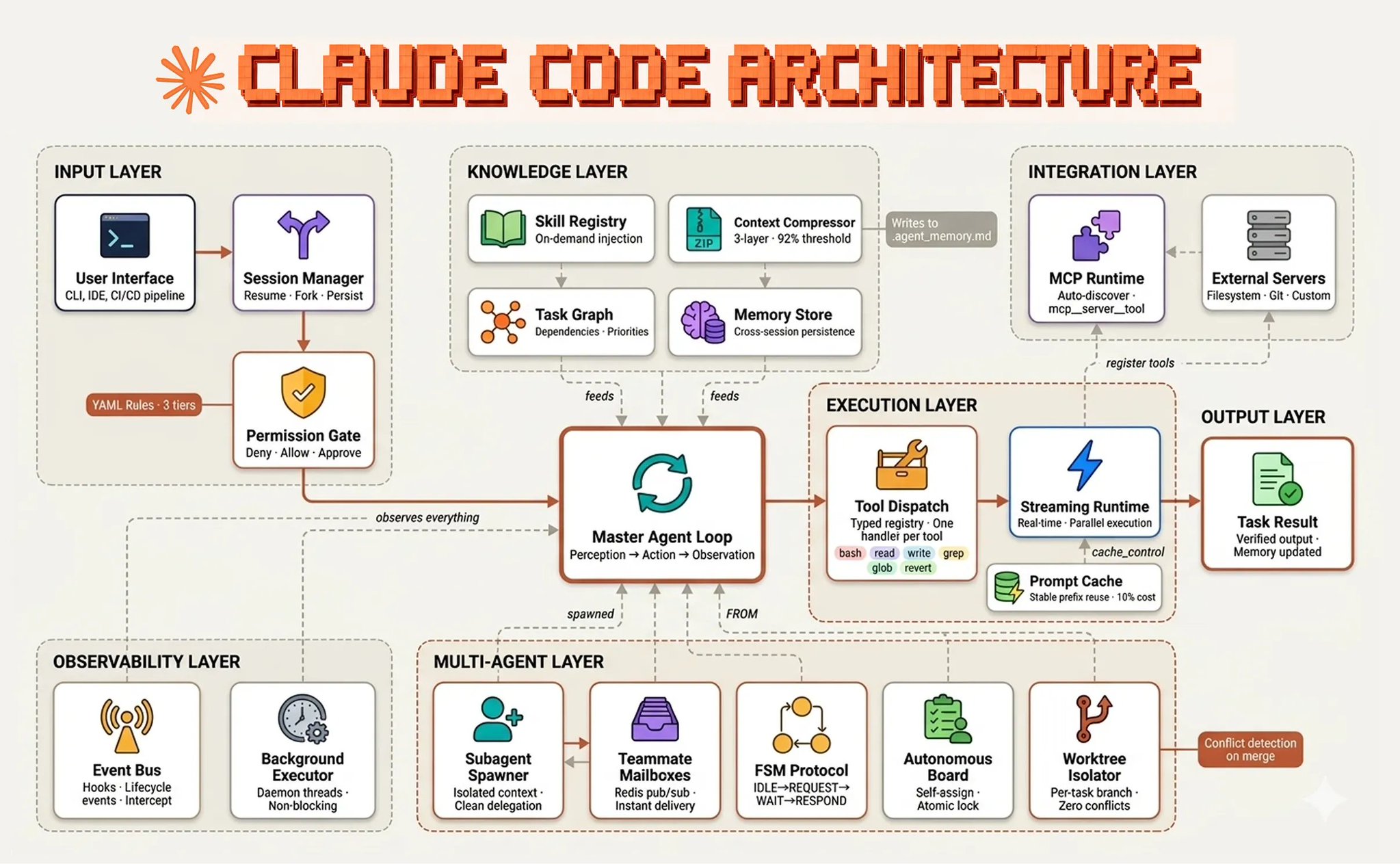
前一节里的几乎每个概念,都以「具名组件」的形式出现在这张图上。上下文注入就是知识层。循环状态由记忆存储和工作树隔离器承载。破坏性动作的钩子坐在权限闸后面。子智能体的上下文防火墙撑起了整个多智能体层。工具分发注册表,是 MCP 服务器和 bash 共同插入的接口。Claude Code 的发展轨迹,至少有一半是关于 Harness 的,而非底层模型。
Harness 不会缩水,它会迁移
模型变强,并不意味着 Harness 不再需要——它只是换了位置。
人们很容易假设,更好的模型会让脚手架变得多余。例如最近一轮模型升级,确实把「上下文焦虑」相关的缓解措施需求大幅压低了。但地板抬高的同时,天花板也抬高了。过去够不到的任务现在进了视野,带来全新的失败模式。
Harness 里的每一个组件,都编码着一个「关于模型自己做不到什么」的假设。当模型变强,过时的脚手架要拆掉,新的脚手架要搭起来,去够到下一段地平线。
那训练循环呢?
Harness 设计和模型训练之间存在一个活跃的反馈循环。
如今的模型常常在后训练阶段把特定的 Harness 也塞进闭环,这制造了一定程度的过拟合。模型会变得特别擅长 Harness 设计者优先考虑的那些动作(比如文件系统操作、bash、子智能体派发)。
这使得 Harness 是一个活的系统,而不是一份静态配置文件,也证明了所谓「最好的 Harness」,是为你独特的任务与工作流专门调优过的那一个。
Harness 即服务(HaaS)
行业的重心,正在从「在 LLM API 上构建」(提供文本补全 completions)转向「在 Harness API 上构建」(提供运行时)。如今的 SDK 直接把循环、工具、上下文管理、钩子和沙箱都装在盒子里给你。
从零搭编排不再是默认选项;现代默认是选一套 Harness 框架,配好它的几根核心支柱,然后把精力专注在领域特定的提示词和工具设计上。
这就是规模化排障的前提:你是在调一个结构良好的配置面,而不是把整个智能体架构再发明一遍。
终点在哪里
看看今天最强的几个编码智能体,它们之间的相像程度,已经超过了它们底层模型之间的相像程度。 模型各异,但 Harness 的模式正在收敛。行业正在迅速识别出那些「承重」的脚手架——把生成式文本变成能真正发版的软件所必需的骨架。
最让人兴奋的开放问题,已经超出了单智能体的范畴:并行编排多个智能体;让智能体分析自己的执行轨迹来修补 Harness 层面的故障;构建出能即时动态拼装工具的环境。
最终,这是一个 Harness 不再是静态配置文件,而越来越像编译器的阶段。
如果你在找一套出色的智能体 Harness 框架,@FredKSchott 写了 Flue。它扎实可靠,而且——据说——是被这篇文章的一个早期版本启发的。
相关笔记
- 我的 AI 工具采用之旅 —— Mitchell Hashimoto 把作者所说的「棘轮」(每个错误升格为规则) 在 Ghostty 项目里走过一遍的亲历记
- Harness 工程:在智能体优先的世界里驾驭 Codex —— Codex 视角下的同主题实战
- 解剖智能体Harness —— 把 Harness 拆成提示、工具、钩子、子智能体的工程细节版
- AI代理的上下文工程:构建Manus的经验教训 —— 重点对照本文「对抗上下文腐烂」一节
- 长时间运行智能体的高效编排框架 —— 与本文「长周期执行」一节互补
- 多智能体协调模式:五种方案及其适用场景 —— 对应文末「并行编排多个智能体」的开放议题