核心思想
智能体工具大多在服务端执行,因此能调 API,却触及不到用户真正工作的客户端环境(浏览器状态、设备能力、应用内操作)。headless 工具反转了这一点:模型眼中它和普通工具无异,但调用被下发到客户端本地执行、再把结果送回推理循环。由此带来三重收益——能做服务端无法模拟的事(地理定位、剪贴板)、隐私数据默认留在本地、省去不必要的往返。核心是「定义与执行分离」:服务端知道要做什么,客户端知道怎么做。

太长不看:如今大多数智能体工具都跑在服务端,这意味着智能体能调用 API,却无法触及用户真正工作的地方——浏览器、应用状态和设备能力。LangChain 的 headless 工具填补了这道鸿沟:它让智能体能够像调用普通工具一样,直接调用地理定位、剪贴板访问、本地记忆、应用内操作等客户端能力。这让智能体变得更有用、更注重隐私,也更贴合真实的应用行为。
如今的智能体能力越来越强,但用户真正在意的许多能力,其实活在客户端运行时里,而非服务端。浏览器和应用掌握着本地状态、用户选区、设备 API 以及各类应用特有的操作,这些往往是后端系统无法触及的。结果就是:智能体能够推理出”接下来该做什么”,却依然难以在用户真正工作的环境里付诸行动。
造成这道鸿沟的一个原因在于,大多数智能体工具都在服务端执行。当模型决定使用某个工具时,智能体要么在进程内运行它,要么把它委托给外部服务(比如 MCP 服务器),然后再把结果喂回推理循环。这套机制对 API、数据库和后端系统来说运转良好,但它有几个明显的局限:
- 它无法直接访问浏览器专属或设备专属的 API。
- 它无法对那些从未同步到服务端的前端状态采取行动。
- 它常常迫使隐私敏感的数据离开设备。
- 对于本质上属于本地的操作,它会引入不必要的往返。
浏览器才是许多高价值智能体操作真正发生的地方:读取本地应用状态、对当前 UI 采取行动、使用设备能力——而这一切都无需先把数据送到后端。桌面应用通过本地文件、原生集成和会话特有的状态,呈现出同样的模式。如果你的智能体够不到那个运行时,它就只能擅长后端工作流,却在用户真正体验到的交互上力不从心。
设想你正在为 Figma、Google Slides 或某个富文本编辑器打造一个边车智能体(sidecar)。智能体可以在服务端对用户的请求进行推理,但文档模型、选区状态和编辑命令统统活在客户端。服务端工具无法在光标处插入文本、无法重新排版选中的对象、也无法跳转到当前激活的幻灯片——因为这些操作属于应用运行时,而非后端 API。如今,团队通常用一座临时拼凑的 UI 桥来勉强打通:把一部分客户端状态序列化送到服务端,拿回响应,再以命令式的方式给客户端打补丁。这招能用,但它脆弱、难以组合,而且对模型的推理循环完全不可见。
让你的智能体直接从用户浏览器访问记忆或地理定位 API。
这正是 LangChain 中 headless 工具所要解决的问题。
headless 工具改变了什么
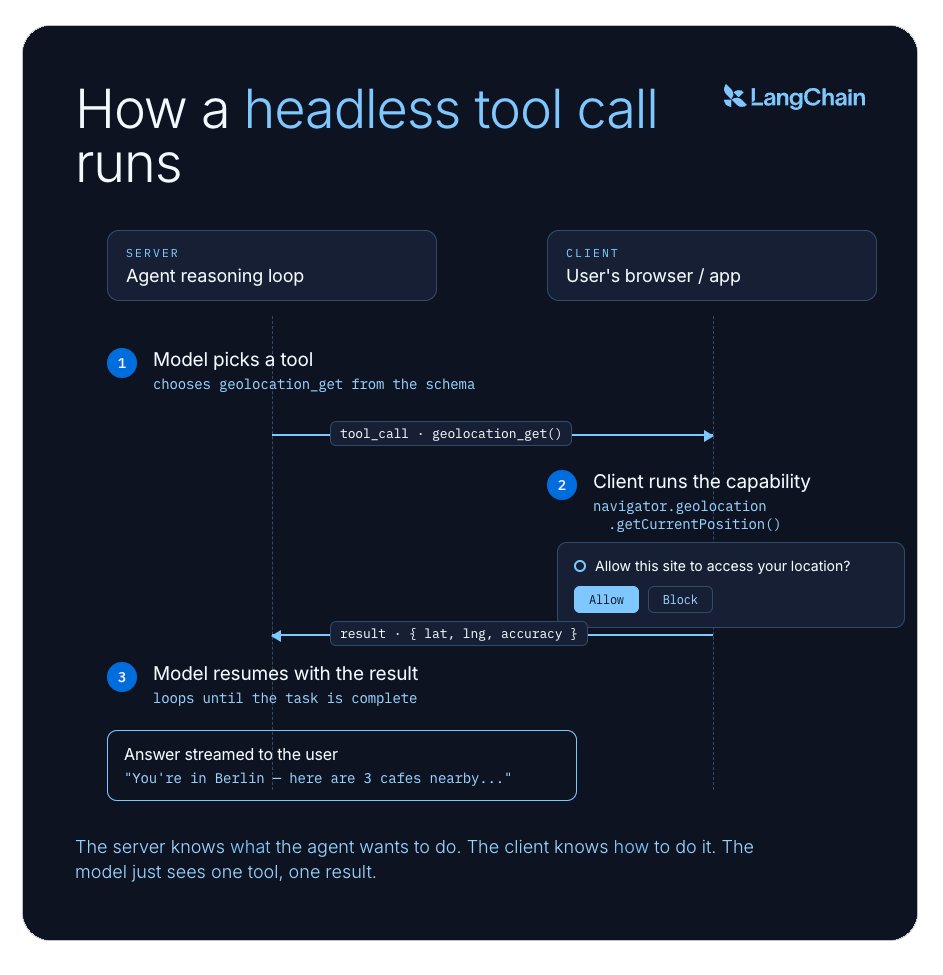
在模型眼里,headless 工具(即客户端工具)和任何其他工具并无二致:它有名字、有描述、有一组预期的输入。模型决定何时调用它,就和调用其他工具一样。区别在于调用之后发生的事。
服务端并不亲自运行这个工具,而是把工具调用发送给客户端——用户的浏览器、桌面应用,或者任何真正具备该能力的环境。客户端在本地运行这个工具,再把结果送回来,智能体便从中断处接着往下走。
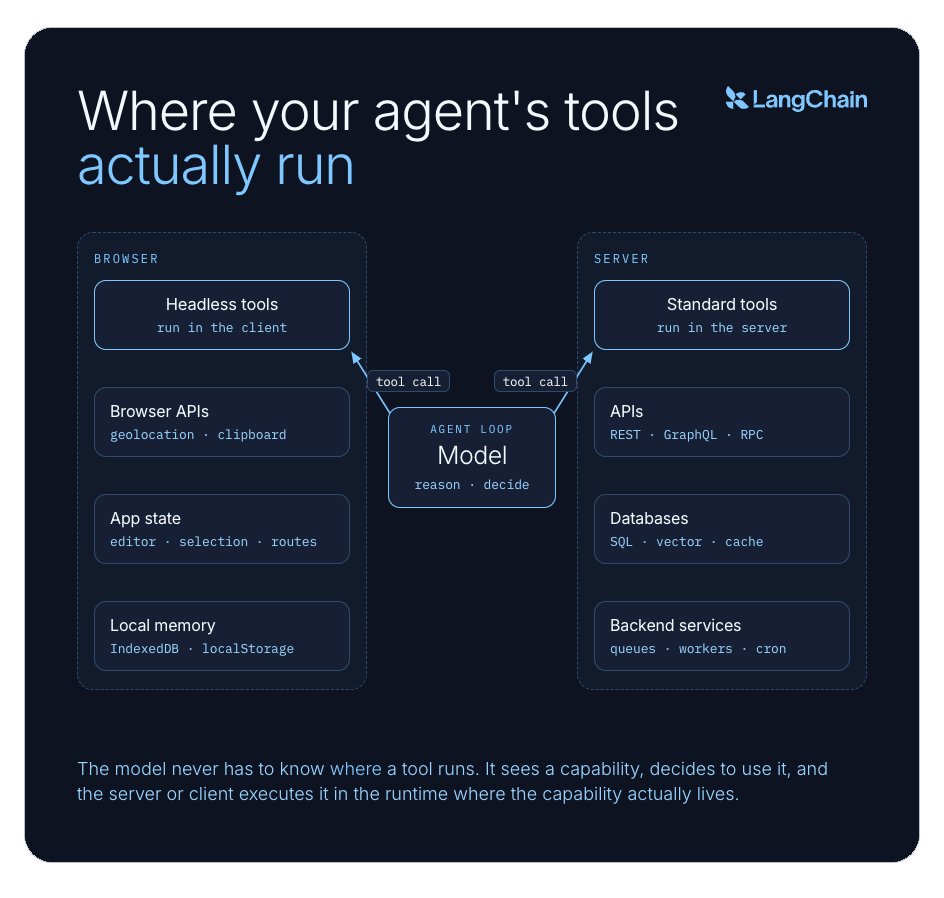
乍一听,这似乎只是个微不足道的实现细节,但它实际上改变了智能体能够可靠掌控的系统范围。
模型永远不需要知道工具跑在哪里。它看到一个工具,决定用它,然后拿到结果。但在幕后,服务端和客户端正在协同:服务端知道智能体想做什么,客户端知道该怎么做。这种职责分离,正是整个思路的内核。
你当然可以手动把这一切接起来:从你的 React 应用里调用 navigator.geolocation.getCurrentPosition(),再把结果发给智能体。但这么一来,模型就没办法发现这项能力、也无从判断何时该调用它。它游离在推理循环之外,沦为一条临时的旁路通道。而 headless 工具把客户端操作放进了智能体的推理循环之内,而不是摆在它旁边。
为什么这很重要
它带来的好处不只是”访问浏览器”这么简单。设想一个智能体正帮你打磨一套幻灯片:它应该能够跳转到当前激活的幻灯片、读取本地上下文,并就地更新演示文稿——而无需把整个会话搬到后端。headless 工具把客户端能力以真正的工具形式暴露在智能体循环之内,让这类交互成为可能。
有些操作根本无法在后端正确模拟。地理定位就是最明显的例子——浏览器掌握着权限弹窗和设备信号。剪贴板访问、画布渲染、文件选择器、实时 UI 导航,全都依赖于当前活跃的客户端环境。标准工具只能通过后端服务去近似这些能力,而 headless 工具能调用货真价实的那一个。

但 headless 工具绝不仅仅用于浏览器 API。它是一种通用机制,用来安全地赋予智能体访问应用原生操作的能力。举个例子:slidev-agent 是广受欢迎的演示框架 Slidev 的一个插件,它用一个 headless 工具来导航到用户当前演示文稿中的某一张特定幻灯片。这既不是数据检索问题,也不是服务端自动化问题。
这一模式还改变了隐私的权衡。智能体的记忆并不总是该放在中心化的后端。借助一个由浏览器存储(比如 IndexedDB)支撑的 headless 工具,记忆可以默认留在本地——持久、低延迟,并天然地限定在该用户与该浏览器的范围内——而不必把”回忆”这件事变成一道服务端的数据管理难题。
代码层面如何实现
在 TypeScript 里,定义与实现之间的分离尤其干净利落。你只需定义一次工具,用 .implement(…) 附上其实现,再把实现传入前端流式 hook。服务端与客户端共享同一份 schema,但只有客户端会加载浏览器特有的执行逻辑。
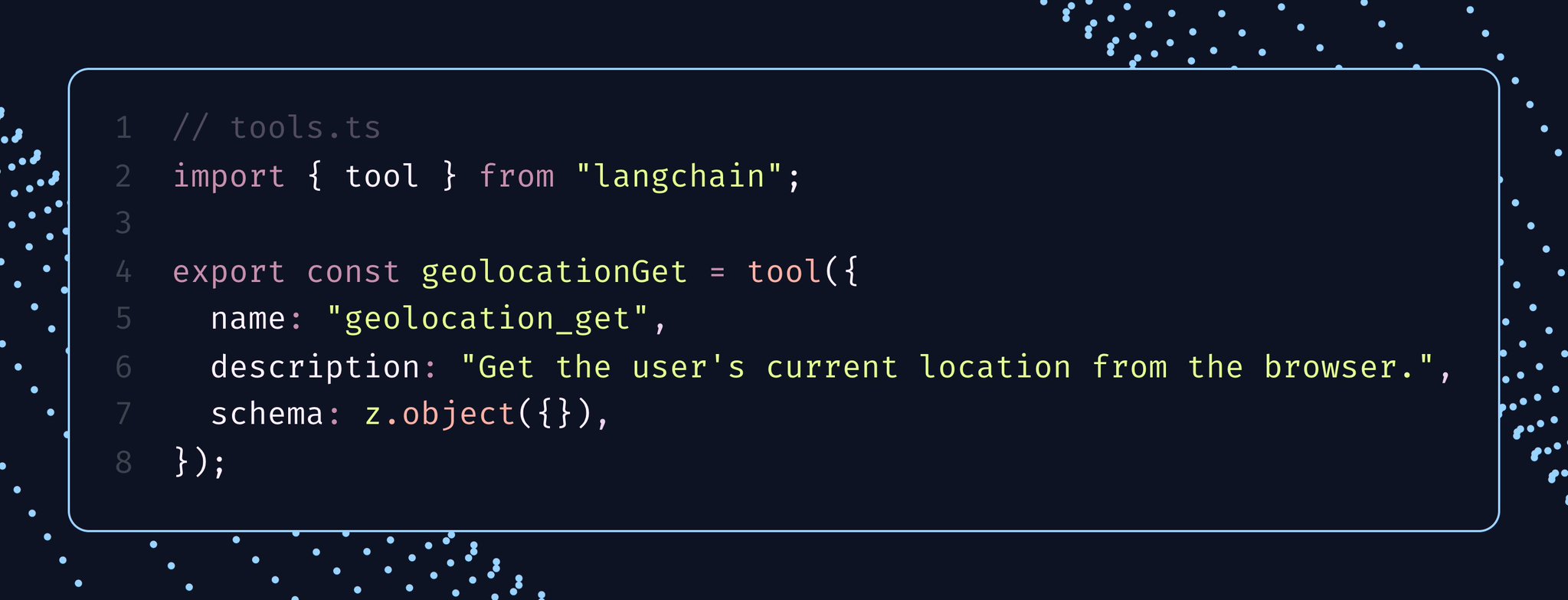
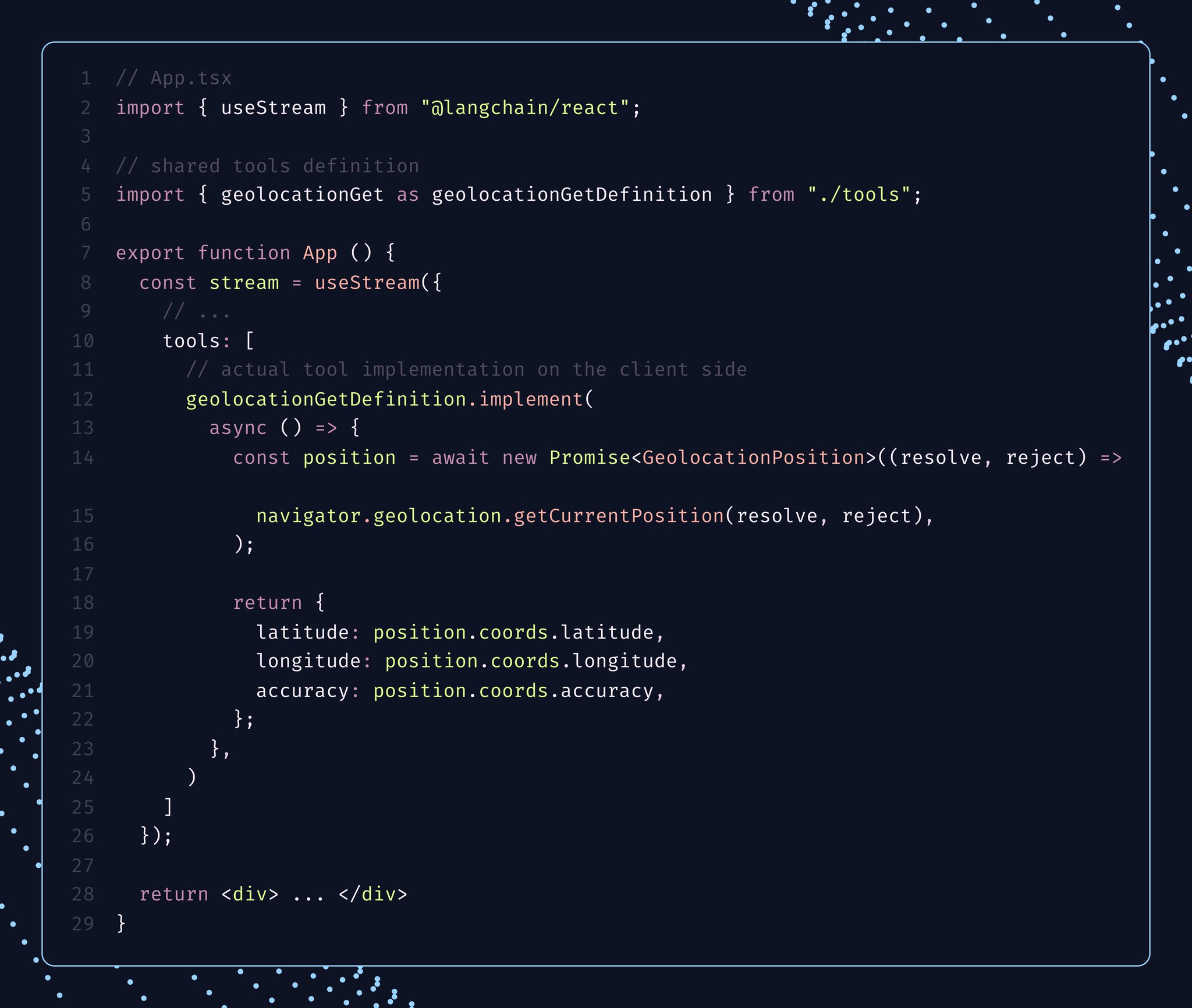
到我们的 LangChain 文档里看一个在线演示吧——它把浏览器本地记忆、地理定位以及可选的人工审批组合在了一起。
小结
标准工具赋予了智能体访问后端系统的能力。headless 工具则赋予它们访问用户真正工作之处的能力。
用户并不生活在你的后端里。他们生活在浏览器、应用和设备中——许多最有价值的智能体交互,恰恰发生在那里。headless 工具让这些交互成为可能,同时又保留了带类型的 schema、显式的能力声明、结构化输出和可审查性,从而让智能体得以使用对用户而言原生的工具,而不只是对服务端而言方便的工具。
现在就开始上手 headless 工具吧——可选 LangChain Python 或 LangChain JS。
感谢 @huntlovell、@colifran_ 和 @sydneyrunkle 提供的悉心审阅与反馈。