核心思想
这篇综述把「智能体框架(agent harness)」推到一线:代码不再只是 LLM 的输出物,而是智能体推理、行动、环境建模与多智能体协调的可执行介质。作者把整个领域组织为三层——**框架接口**(代码作为推理基质、行动接口与环境表示)、**框架机制**(规划、记忆、工具、反馈控制让长周期执行可靠)、**框架扩展**(把单智能体推广到多智能体共享的代码工作区)——并指出当下的开放问题:超越任务成功的评估、不完整反馈下的验证、无回归的框架改进、共享状态一致性、人在环路安全治理与多模态扩展。对在做 Claude Code、Codex、Manus 这类系统的人,这是一份「俯瞰整个领域」的地图。
代码即智能体框架 ◆ 迈向可执行、可验证、有状态的智能体系统 ◆
Xuying Ning, Katherine Tieu, Dongqi Fu, Tianxin Wei, Zihao Li, Yuanchen Bei, Jiaru Zou, Mengting Ai, Zhining Liu, Ting-Wei Li, Lingjie Chen, Yanjun Zhao, Ke Yang, Bingxuan Li, Cheng Qian, Gaotang Li, Xiao Lin, Zhichen Zeng, Ruizhong Qiu, Sirui Chen, Yifan Sun, Xiyuan Yang, Ruida Wang, Rui Pan, Chenyuan Yang, Dylan Zhang, Liri Fang, Zikun Cui, Yang Cao, Pan Chen, Dorothy Sun, Ren Chen, Mahesh Srinivasan, Nipun Mathur, Yinglong Xia, Hong Li, Hong Yan, Pan Lu, Lingming Zhang, Tong Zhang, Hanghang Tong, Jingrui He
机构:University of Illinois Urbana-Champaign、Meta、Stanford University
通讯作者:Hanghang Tong、Jingrui He
摘要
近年来,大语言模型(large language models, LLMs)在理解与生成代码方面展现出强劲能力——从竞赛编程到仓库级软件工程都已取得令人瞩目的成绩。在新兴的智能体系统中,代码不再仅是输出目标,而是越来越多地成为智能体推理、行动、环境建模与基于执行的验证的操作介质。本文以”智能体框架(agent harness)“为视角刻画这一转变,并提出”代码即智能体框架(code as agent harness)“这一统一观点:将代码置于智能体基础设施的核心。为系统性研究这一视角,我们围绕三个相互衔接的层次组织本综述。第一,框架接口(harness interface)——代码如何连接智能体的推理、行动与环境建模。第二,框架机制(harness mechanisms)——支撑长周期执行的规划、记忆与工具使用,以及让框架保持可靠且自适应的反馈驱动控制与优化。第三,框架扩展(scaling the harness)——从单智能体到多智能体场景,共享代码产物如何支撑多智能体的协调、审查与验证。横跨这三层,我们梳理”代码即智能体框架”的代表性方法与实际应用,覆盖编程助手、GUI/OS 自动化、具身智能体、科学发现、个性化与推荐、DevOps 及企业工作流。我们进一步勾勒框架工程的开放挑战:超越最终任务成功的评估、不完整反馈下的验证、无回归的框架改进、多智能体间一致的共享状态、安全关键操作的人机协同监督,以及向多模态环境的扩展。通过将代码定位为智能体 AI 的框架,本综述为可执行、可验证、有状态的 AI 智能体系统提供了一份统一路线图。
关键词:Agent Harness、Coding Agent、Harness Engineering、Agentic AI
Github 仓库:https://github.com/YennNing/Awesome-Code-as-Agent-Harness-Papers
1 引言
近年来,大语言模型(LLMs)在理解与生成代码方面展现出强劲能力 [chen2021evaluating, austin2021program, nijkamp2022codegen],并在从竞赛编程 [li2022competition] 到仓库级软件工程 [jimenez2023swe] 的任务中表现优异。基于这些能力,代码在智能体系统中的角色正从”待生成的目标产物”持续扩展。程序日益成为 LLM 智能体进行推理、行动以及环境建模的媒介。程序辅助推理方法将中间计算外化为可执行代码 [chen2022program, gao2023pal, li2023chain];机器人与具身智能体把生成的程序作为与物理或仿真世界交互的可执行策略 [ahn2022can, liang2023code];软件工程或交互式环境则把代码库、执行轨迹、测试与运行时反馈作为环境状态与动态的结构化表示,智能体在其中规划、行动、修订自身行为 [yang2023intercode, jimenez2023swe, liu2023agentbench]。综合来看,这些进展揭示了一个更宏观的视角:代码不仅是 LLM 生成的产物,更是智能体推理、行动、观察反馈并验证进度的可执行、可检查、有状态的媒介。我们将这一视角称为”代码即智能体框架(code as agent harness)”。
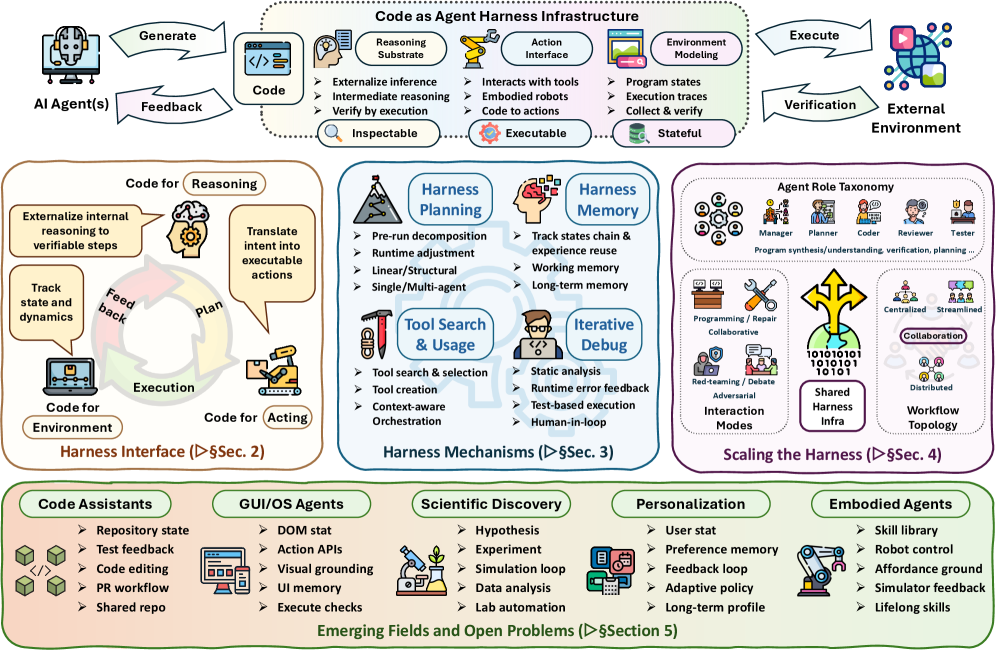
图 1:代码即智能体框架的分类法。
近期关于”智能体框架”的讨论 [lee2026metaharness, lou2026autoharness, anthropic2025longrunning, lopopolo2026harnessengineering] 为理解这一转变提供了系统级视角。智能体框架指包裹 LLM 的软件层,它提供工具、API、沙盒、记忆、验证器、权限边界、执行循环与反馈通道,从而将无状态的模型转变为能够长时间执行任务的功能性智能体 [zhang2025agentic, agrawal2025gepa, zhang2023toolcoder, wang2025teaching, lavon2025execution, cheng2026llm, dai2025feedbackeval]。从这一视角看,自主性的瓶颈不仅在于基础模型的推理能力,也在于将模型输出连接到长周期行动与持久状态的系统可靠性。
为厘清代码在这一更广阔框架视角下的角色,本文区分长时运行智能体系统的三个相互耦合的要素:模型内置能力(model-internal capabilities)、系统提供的框架基础设施(system-provided harness infrastructure)与智能体发起的代码产物(agent-initiated code artifacts)。模型内置能力指模型的推理、感知、规划、仿真与评估能力。系统提供的框架基础设施指预定义的工具、API、沙盒、记忆系统、验证器、权限边界、遥测与工作流——它们将模型输出与外部行动和反馈相连,是框架工程的主要研究对象 [openai2026harnessengineering, langchainanatomyharness2026]。与之相对,智能体发起的代码产物尚未被充分探索:它们是智能体在任务执行循环中创建、执行、观察、修订、持久化与共享的交互式代码对象。借助执行反馈,这些产物帮助智能体推理、行动、验证进度、存储状态并与其他智能体协作。典型例子包括回归测试、临时工具、DSL 程序、可执行工作流、可复用技能以及中间程序状态。Claude Code [claudecode2025]、Codex [codex2025]、LangChain [langchaindeepagentsharness2026] 等代表性系统以及企业级智能体平台共同表明,这些要素如何协同支撑长时运行智能体系统的自适应。
带着这一区分,本文重新审视代码在智能体系统中的角色。现有综述通常将代码视为 LLM 的最终输出。本文转而聚焦”智能体发起的代码产物”,研究模型能力如何通过与框架基础设施的交互来构建并演化这些产物——代码在此成为接口、智能体能力与多智能体协调的组织中心。在各类智能体系统中,代码不仅用于产出解决方案,也用于执行推理、grounded 行动、维护状态与暴露反馈。我们将这一视角称为”代码即智能体框架”:代码作为智能体推理、行动与适应的可执行、可检查媒介。这一视角将研究焦点从”产出正确程序”转向”理解代码如何支撑可靠的闭环智能体行为”。
为系统刻画”代码即智能体框架”,我们将综述组织为三个相互衔接的层次,如图 1 所示。这一组织方式反映代码作为操作介质如何进入智能体循环:它首先作为推理、行动与环境表示的框架接口出现;接着支撑规划、记忆、工具使用、执行与修复的长期框架机制;最终成为多智能体在仓库、测试、轨迹、工作流与执行状态上协同的共享产物。
第一,**框架接口:用于推理、行动与环境建模的代码(§2)**研究代码如何构成模型与任务环境之间的基础接口。在这一层,代码是把模型输出转化为可执行、可检查结构的媒介。我们综述代码即推理:程序外化中间计算,解释器、符号求解器、执行轨迹或过程奖励据此检查并精炼推理 [gao2023pal, chen2022program, li2023chain, ye2023satlm, ni2024next, li2025codeprm]。接着回顾代码即行动:生成的程序作为策略、工具调用、行为树或可复用技能,服务于具身、GUI 与软件环境 [ahn2022can, liang2023code, wang2023voyager, mu2024robocodex, zhang2025codebt, lin2026ui]。最后讨论代码即环境建模:程序状态、仓库、轨迹、模拟器与测试作为智能体交互的状态、动态与反馈信号 [tang2024worldcoder, copet2025cwm, zheng2026code2world, jimenez2023swe, liu2023agentbench, gandhi2026endless]。这一层确立框架的核心接口:代码让推理可执行、行动可编程、环境状态可检查。
基于这一接口,**框架机制:规划、记忆、工具使用、控制与优化(§3)**研究代码化智能体如何在超越单步生成的尺度上保持可靠。一旦代码进入智能体循环,框架就必须决定下一步执行什么、保存何种状态、暴露哪些工具,并将失败转化为修正行动。本文因此综述若干分支:通过任务分解、结构 grounded、轨迹搜索或工作流编排来组织长周期软件任务的规划方法 [jiang2024selfplanning, gur2023webagent, bairi2024codeplan, li2025codetree, islam2024mapcoder];维护工作状态、检索仓库证据、存储可复用经验、支持共享交互历史的记忆方法 [gaurav2025codemem, zhang2024autocoderover, zhang2023repocoder, wang2026memgovern];将智能体连接到 API、仓库、执行环境与验证工具的工具使用方法 [zhang2023toolcoder, liu2024toolnet];利用静态分析、运行时错误、测试与人类反馈,通过反复执行修订代码的反馈驱动控制与框架优化方法 [huang2023agentcoder, ukai2024adacoder, Nunez2024AutoSafeCoder, li2026agentharness]。这一层将 §2 的接口转化为操作性框架:规划控制执行轨迹,记忆保存状态,工具扩展行动空间,反馈驱动适应在失败与修订之间形成闭环。
最后,**框架扩展:基于代码的多智能体编排(§4)**将框架从单智能体扩展至协作生态。当多个智能体在代码上协同工作时,框架不仅要支持个体的推理与执行,还要协调角色、共享中间产物、维护共同状态、验证集体进度。本文综述代码中心的多智能体系统:角色包括经理、规划者、编码者、审阅者、测试者;协作模式涵盖编程、修复、辩论、红队对抗与对抗式交互;工作流拓扑从集中协调到分布式或流式协作 [wu2024autogen, Hong2023MetaGPT, Dong2024SelfCollaboration]。这一层展示代码如何成为编排式自主性的共享框架:仓库、测试、轨迹与结构化产物构成共享工作区,智能体在其中协同、检查并改进彼此的行为。
综述范围
本综述研究代码即智能体框架:以代码为中心的智能体系统,其推理、行动、状态、反馈与验证均围绕可执行、可检查、有状态的程序组织。我们将截至 2026 年的文献组织为三个相互衔接的层次:
- 框架接口:代码作为推理基质、行动接口与环境表示进入智能体循环。
- 框架机制:规划、记忆、工具使用、控制与框架优化让代码中心的智能体在长周期执行与修订中持续运作。
- 框架扩展:共享的代码产物、执行状态、仓库与结构化工作流支撑多智能体系统中的协调、审查与集体验证。
除分类法之外,本文考察智能体发起的代码交互如何贯穿五大应用领域。在编程辅助中,智能体在真实仓库上撰写补丁、测试与 issue 解决流程 [jimenez2023swe, yang2024swe, wang2024openhands]。在 GUI 与 OS 自动化中,智能体基于 DOM 树、辅助功能 API 与可执行评估器合成并执行界面命令 [deng2023mind2webgeneralistagentweb, zhou2024webarenarealisticwebenvironment]。在科学发现中,智能体动态组装并执行跨越仿真、实验协议与数据分析的假设检验流水线 [bran2023chemcrowaugmentinglargelanguagemodels, boiko2023autonomous, lu2024aiscientistfullyautomated, huang2025biomni]。在个性化与具身控制中,智能体根据环境反馈撰写并修订可执行策略、模拟器与技能库 [ahn2022can, liang2023code, wang2023voyager]。我们进一步勾勒框架工程的开放挑战:超越最终任务成功的评估、不完整反馈下的验证、无回归的框架改进、多智能体间一致的共享状态、人类监督以及向多模态环境的扩展。本综述提供一份路线图:不仅将代码视为智能体生成的对象,更将其视为智能体执行、适应、协同可靠行为的运行时媒介。
主要贡献
- 概念框架:本文形式化”代码即智能体框架”,将代码从生成产物重新定义为可执行、可验证、有状态的 AI 智能体系统的操作基质。
- 分类与综合:本文将”代码即智能体框架”组织为三个相互衔接的层次——框架接口、框架机制、框架扩展——并综合代表性方法。
- 应用与未来议程:本文将分类法与现实应用相连,勾勒评估、验证、安全与协调方面的关键挑战。
2 框架接口:用于推理、行动与环境建模的代码
框架将无状态的语言模型转化为功能性智能体——其方式是将模型输出 grounded 到外部执行、持久状态与可验证反馈中。任何框架最基本的设计问题因此都是:何种媒介将模型连接到任务环境?
本文主张:答案是代码。与自然语言不同,代码是可执行的——模型输出转化为具备形式化可验证结果的操作;可检查的——中间计算以结构化轨迹的形式暴露给框架以供读取、存储与处理;有状态的——演化中的程序以可持久、可修改的形式跨步骤地表征任务进度。关键在于,这些不仅是代码作为符号系统的属性,而是代码作为框架接口的功能性属性。可执行性意味着框架可以核验模型的意图。可检查性意味着失败可以被诊断并反馈。有状态性意味着智能体的交互历史不会在步骤间丢失。
范围边界
我们对代码的使用是宽泛的,但并非比喻性的。在本综述中,代码指可执行或机器可检查的产物,包括程序、脚本、形式化规范、证明脚本、API 模式、工具定义、测试、仓库、模拟器、配置文件,以及由可执行系统产生或消费的代码相邻执行产物(例如轨迹与日志)。相对地,原始感知、物理状态、人类意图与模型内部的潜在推理本身不是代码。它们可以通过代码被感知、估计、序列化、验证或作用,但不应与代码接口相混淆。这一边界很重要,因为代码作为框架接口并不取代感知、具身、人类目标或模型推理,而是让它们的某些方面在智能体循环中变得可执行、可检查、有状态。
我们围绕代码在智能体系统中承担的三种角色组织该接口。代码即推理将内部逻辑外化为可验证的计算,允许外部解释器、符号求解器、执行轨迹或过程奖励据以检查并精炼推理(§2.1)。代码即行动将高层意图翻译为 grounded 于具身、GUI、软件或工具使用环境的可执行操作(§2.2)。代码即环境建模通过程序状态、仓库、模拟器、测试与日志来表征世界状态、转移动态与反馈信号,智能体可以执行、编辑与查询这些产物(§2.3)。总体而言,这三种角色定义了框架接口:代码让推理可执行、行动可编程、环境状态可检查。
2.1 代码即推理
智能体框架的核心角色之一,是将模型推理从短暂的文本生成转化为可执行、可验证的计算。早期提示技术(如纯思维链 CoT [wei2022chain])完全在自然语言内进行推理与计算,迫使模型在单一潜在文本过程内既分解问题又执行中间操作。尽管语言模型常常善于提出推理步骤,但在忠实执行符号、逻辑或算术计算方面仍不可靠 [gao2023pal]。更重要的是,纯文本推理几乎不给智能体框架提供验证中间状态、检查执行行为或跨步骤持久化计算进度的能力。
“代码即推理”因此引入代码作为模型与框架之间的执行接口,超越纯文本推理。模型生成可执行程序,外部运行时、解释器、符号求解器或验证模块可以执行并评估这些程序。这将高层推理与低层计算解耦:模型提出过程,框架执行它们、观察运行时行为、存储中间状态,并将执行结果反馈给后续推理。
近期工作进一步将这一接口从”程序执行作为外部计算器”扩展为”执行产物作为可复用的推理信号”。输入与输出、执行轨迹、变量状态、控制流结构以及函数级测试,都可以作为中间状态,由框架进行核验、打分并反馈给后续推理。现有工作因此可以组织为三种范式:程序委派推理、形式验证与符号推理,以及迭代式代码 grounded 推理。下文逐一详述。
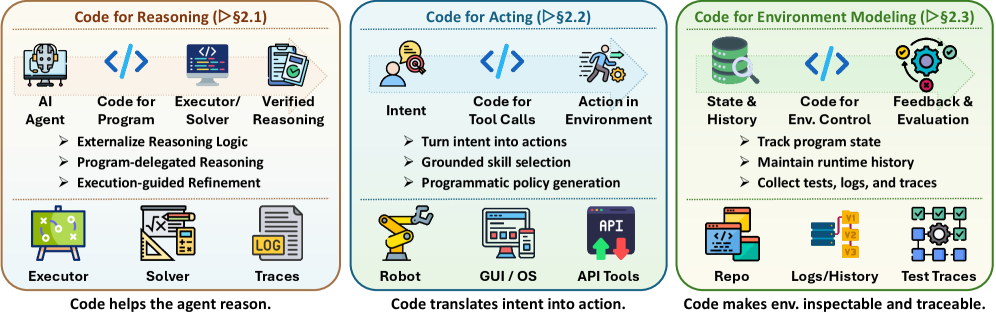
图 2:代码作为框架接口的概览——通过可执行程序、工具调用、状态跟踪与反馈轨迹,将智能体连接到推理、行动与环境建模。
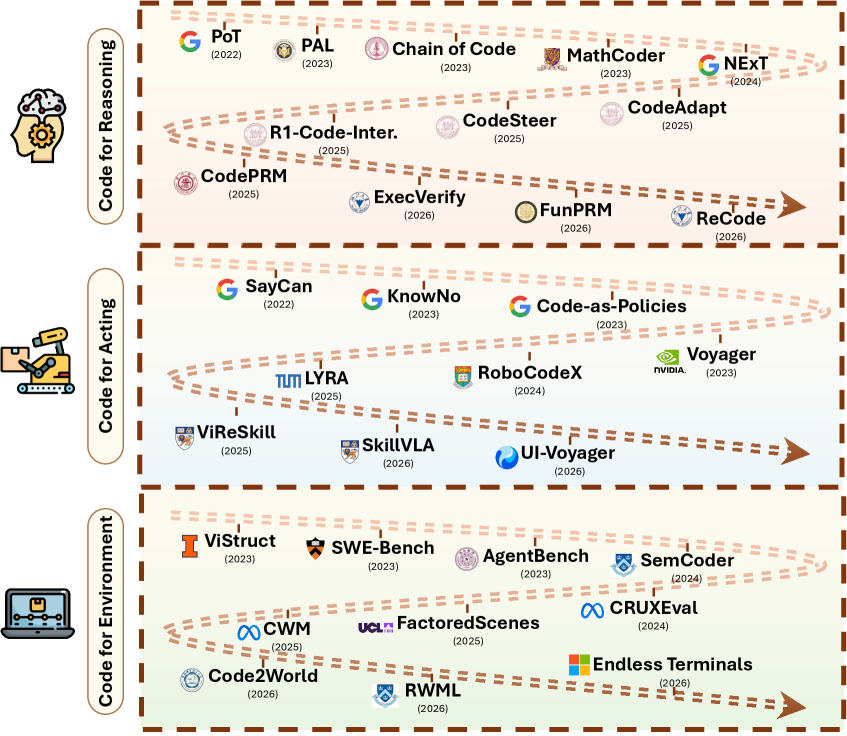
图 3:框架接口的路线图,按代码在推理、行动与环境建模中的角色组织,代表性工作按时间顺序排列。
2.1.1 程序委派推理
程序委派推理将可执行程序用作问题分解与计算之间的主接口。不再仅依赖自然语言推理,模型生成代码,由外部解释器执行以产出形式化 grounded 的输出。早期工作 [nye2021show, gao2023pal] 表明,将计算委派给程序大幅提升了可靠性,因为中间推理被纳入结构化、可验证的执行轨迹。Program-of-Thoughts(PoT)提示 [chen2022program] 进一步系统化这一范式——显式将推理分解为可执行程序;POET [pi2022reasoning] 与 MathCoder [wang2023mathcoder] 等后续工作改进了执行保真度与领域专门化。后续工作研究程序委派在何种条件下有效,包括执行正确性、任务结构与运行时交互的作用。例如,Chain of Code(CoC)[li2023chain] 与 CIRS [bi2024program] 分析可执行推理相对于纯语言推理的失败模式如何变化。后续方向将这一接口扩展到孤立任务执行之外。跨语言推理框架 [payoungkhamdee2025towards] 表明,基于程序的推理可以通过共享的可执行结构跨越语言环境;基于方法的推理 [su2025method] 引入了跨任务复用的可编程过程。CodeAdapt [zhang2025code] 等更近系统进一步表明,将语言模型与可执行推理接口紧密耦合可以超越专门的推理导向模型。此外,CodeI/O [pmlr-v267-li25t] 将上下文 grounded 的程序转化为代码输入-输出预测任务,暴露逻辑流规划、状态空间搜索、决策树遍历与模块化分解等推理原语,并通过可执行验证保留过程严谨性。
2.1.2 形式验证与符号推理接口
混合的神经-符号方法将灵活的语言推理与结构化的符号计算相结合,把代码与符号产物作为持久的中间表示,而不仅仅是生成的文本。Graph-of-Thoughts [besta2024graph] 等早期表述将思维链推理推广为图结构轨迹,使中间状态能够分支、合并与复用。在此方向上,自验证反思 [yu2025self]、MA-LoT [wang2025ma] 与 Socratic self-refine [shi2025ssr] 引入了迭代验证循环——其中符号一致性检查引导对解题路径的精炼。
近期工作通过基于代码的接口进一步紧密耦合神经生成与符号执行。CodeSteer [chen2025codesteer] 与 Code-as-Symbolic-Planner [chen2025code] 显式协调自由形式的语言推理与可执行符号操作,把程序视为框架可以跨阶段检查、变换与执行的结构化基质。VisualCoder [chi-etal-2025-visualcoder] 通过控制流表征让程序行为可见,将生成的推理与可视化控制流图、执行路径对齐,从而把动态程序行为转化为可检查的产物,用于程序行为预测。这些方法将神经-符号接口从纯文本代码拓展到框架可以引用、验证与复用的多模态执行产物。
一条互补的工作线把机器可验证的形式语言本身作为推理接口。Lean [moura2021lean]、Isabelle [nipkow2002isabelle] 与 Coq [barras1999coq] 等证明助手基于严密的逻辑基础提供形式化证明语言,使每个推导步骤都可由验证器检查。早期基于 LLM 的定理证明系统,包括 ReProver [yang2023leandojo]、DeepSeek-Prover [xin2025deepseek] 与 TheoremLlama [wang2024theoremllama],为将语言模型与证明助手反馈结合用于数学推理建立了实用配方。近期系统(如 DeepSeek-Prover-V2 [ren2025deepseek2]、Kimina-Prover [wang2025kimina]、MA-LoT [wang2025ma] 与 Goedel-Prover-V2 [lin2025goedel2])通过审慎的证明搜索、自我修正、反复证明生成与验证改进这一过程。形式验证接口也在向数学定理证明之外扩展。HybridReasoning [wang2025let] 应用形式证明器支撑自然语言推理;Lean4Physics [li2025lean4physics] 与 PhysLib [physlib] 将基于 Lean 的验证扩展到物理学;VERINA [ye2025verina] 与 Goedel-Code-Prover [li2026goedel] 将形式化方法适配到代码验证。Lean4Agent [wang2026lean4agent] 进一步把这一脉络扩展到智能体系统——用 Lean4 对智能体工作流与轨迹进行建模与验证。从框架视角看,这些系统表明,形式语言不仅可以作为推理工具,还可以作为约束、认证与审计智能体行为的可执行契约。
2.1.3 迭代式代码 grounded 推理
迭代式代码 grounded 推理聚焦于生成、执行与反馈之间的闭环交互。在这些系统中,推理不是单步过程,而是一条 grounded 于可执行状态转移的迭代计算轨迹。NExT [ni2024next] 等早期工作训练模型通过程序轨迹推理来预测执行行为,从而将中间推理 grounded 在运行时语义中。相关工作 [armengol2025cannot] 也强调:可执行轨迹比仅有的最终文本输出提供了更丰富的监督信号。在此基础上,后续方法引入显式的”生成-执行-验证-精炼”循环。CodePRM [li2025codeprm] 与 ORPS [yu2024reasoning] 等方法利用执行结果来评估并精炼中间推理轨迹,使框架能够通过运行时反馈而非纯下一 token 预测来引导推理。沿同一方向,CYCLE [ding2024cycle] 与 Self-Edit [zhang2023self] 等系统利用执行感知的修正信号迭代修订生成的解。强化学习进一步强化了这一范式——把执行反馈视为对推理轨迹的优化信号。CodeRL [le2022coderl]、CodeRL+ [jiang2025coderl+] 与 RLTF [liu2023rltf] 通过单元测试奖励优化功能正确性,而 StepCoder [dou2024stepcoder] 等方法在优化过程中加入细粒度的编译器与运行时反馈。RLEF [gehring2024rlef] 将这一交互形式化为 grounded 于多步执行反馈的策略优化,使推理策略能够通过迭代式运行时交互进行适应。更近的方法走向完全交互的推理环境。例如,EG-CFG [lavon2025execution] 在生成过程中直接注入执行信号以支持步级修正;R1-Code-Interpreter [chen2025r1] 等系统在持久的交互式会话中交错推理与多轮代码执行。
表 1:代码作为推理基质的代表性系统。
| 方法 | 机制 | 推理范式 | 关键创新 |
|---|---|---|---|
| PoT [chen2022program] | 委派 | 混合注释 | 将代码与自然语言 CoT 融合 |
| PAL [gao2023pal] | 委派 | 程序辅助 | 解耦逻辑与计算 |
| CodeAdapt [zhang2025code] | 委派 | 可泛化逻辑 | 代码使能 LLM 胜过推理模型 |
| CodeI/O [pmlr-v267-li25t] | 委派 | I/O 预测 | 将代码转为可验证的输入-输出推理任务 |
| SATLM [ye2023satlm] | 形式 | SAT/SMT 求解 | 用符号求解器作机器可检查推理后端 |
| ReProver [yang2023leandojo] | 形式 | Lean 证明搜索 | LLM 生成结合证明助手反馈 |
| Dpsk-Prover [xin2025deepseek] | 形式 | Lean 定理证明 | 训练 LLM 生成形式化数学证明 |
| Dpsk-Prover-V2 [ren2025deepseek2] | 形式 | 审慎证明 | 通过分解与自我修正进行 Lean 证明搜索 |
| Goedel-Code-Prover [li2026goedel] | 形式 | Lean 代码证明 | 搜索层级化 Lean 证明用于代码验证 |
| Lean4Agent [wang2026lean4agent] | 形式 | 智能体验证 | 在 Lean4 中建模与验证智能体工作流与轨迹 |
| Chain of Code [li2023chain] | 混合 | LMulator | 仿真不可执行的语义代码 |
| SATLM [ye2023satlm] | 混合 | 形式逻辑 | 用 SAT/SMT 求解器作推理后端 |
| CodeSteer [chen2025codesteer] | 混合 | 符号控制 | 显式在符号代码与神经文本间切换 |
| VisualCoder [chi-etal-2025-visualcoder] | 混合 | CFG grounded | 把代码推理与可视化控制流产物对齐 |
| NExT [ni2024next] | 迭代 | 轨迹 grounded | 通过程序轨迹预测执行行为 |
| MathCoder [wang2023mathcoder] | 迭代 | 反馈驱动 SFT | 交错代码、输出与反思 |
| CodePRM [li2025codeprm] | 迭代 | 过程奖励 | 在推理-执行轨迹上学习奖励函数 |
| RLEF [gehring2024rlef] | 迭代 | 多步 RL | 利用执行反馈直接优化策略 |
| EG-CFG [lavon2025execution] | 迭代 | 执行引导 | 在生成中直接集成执行信号 |
| R1-Code-Int. [chen2025r1] | 迭代 | 完全交互 | 自主交错推理与多次执行 |
| ExecVerify [tang2026execverifywhiteboxrlverifiable] | 迭代 | 步级 RL | 使用语句级与变量级执行奖励 |
| FunPRM [zhang2026funprmfunctionasstepprocessreward] | 迭代 | 函数级 PRM | 把函数视为可验证的过程奖励单元 |
| ReCode [fan2026recodereinforcingcodegeneration] | 迭代 | 过程 RL | 用推理过程奖励强化代码生成 |
2.2 代码即行动
除推理之外,智能体还必须把模型连接到外部环境——在那里决策会产生真实的可执行效果。在这一阶段,代码不再主要作为计算媒介,而是作为行动接口,把模型输出转换为 grounded 操作,例如工具调用、机器人控制策略、GUI 动作或软件命令。框架借助这一接口,把高层意图翻译为可与具身、数字、交互式环境互动的可执行行为。核心挑战因此是 grounding:框架必须把抽象的语言输出映射为符合目标环境约束(包括具身极限、接口 API、环境动态与安全要求)的可执行行为。与”代码即推理”不同——那里解释器常常可以直接验证正确性——行动执行发生在部分可观测、动态演化的环境中,失败可能通过无效状态转移、延迟反馈或沉默执行错误浮现。例如,机器人可能试图抓取其可达工作空间之外的物体,而不产生任何显式的运行时异常。
重要的是,可执行行动代码是这些组件的接口,而非它们的替代品。在具身场景中,感知模块提供观测,affordance(可供性)或可行性模型估计哪些行动可行,运动规划器与控制器把符号命令连接到传感器与执行器,安全层约束危险或无效行为。在 GUI 与软件场景中,对应组件包括屏幕解析器、DOM 或辅助功能树、后端 API、用户意图模型、权限系统与程序化验证器。代码位于模型与这些组件之间:它序列化观测、调用 grounding 与规划模块、调用可执行行动,并把验证结果暴露给框架。
“代码即行动”因此引入结构化的可执行程序,作为模型与环境之间的控制接口,使框架能够通过交互反馈执行、监控、验证、复用与精炼行动。这一接口可以以不同形式实现:预定义的技能库、生成的控制策略、持久的技能记忆、GUI/API 工具协议或显式的行动验证框架。AutoHarness [lou2026autoharnessimprovingllmagents] 显式实现了最后一种——通过自动合成一个代码框架,在 LLM 与环境之间充当中介,在执行前过滤无效行动。这凸显了”代码即行动”的核心框架视角:代码不仅是要执行的行动,也是连接模型意图与感知、grounding、affordance 估计、控制器、API、执行器与安全约束的可执行边界。
表 2:代码作为行动接口的代表性系统。
| 方法 | 机制 | 行动范式 | 关键创新 |
|---|---|---|---|
| AutoHarness [lou2026autoharnessimprovingllmagents] | 框架合成 | 行动验证 | 合成代码框架,中介模型行动并过滤无效环境交互 |
| SayCan [ahn2022can] | 技能选择 | 基于 affordance | 将 LLM 计划链接到物理可行性 |
| KnowNo [ren2023robots] | 技能选择 | 共形预测 | 为模糊指令校准规划器不确定性 |
| SkillVLA [zhai2026skillvla] | 技能选择 | 双臂 grounding | 将 grounding 扩展到组合式技能复用 |
| BOSS [zhang2023bootstrap] | 技能选择 | 技能引导 | 通过引导练习合成新的可执行技能链 |
| LLM-Guided Traj. [ha2023scaling] | 技能选择 | 轨迹生成 | 生成多样的操作轨迹与可执行成功条件 |
| LRLL [tziafas2024lifelong] | 技能选择 | 终身 grounding | 通过记忆与自我探索演化的技能接口 |
| CaP [liang2023code] | 策略生成 | 层级化 Python | 生成响应式机器人控制策略 |
| RoboCodeX [mu2024robocodex] | 策略生成 | 多模态树 | 跨导航合成树状结构代码 |
| Code-BT [zhang2025codebt] | 策略生成 | 行为树 | 通过代码到行为树规划强加规则约束 |
| ALRM [santos2026alrm] | 策略生成 | 闭环控制 | 集成程序化生成与 ReAct 执行 |
| CP-Agent [szeider2025cp] | 策略生成 | 约束求解 | 用持久执行循环修复形式化约束模型 |
| Robot-Code Sim. [wang2025llm] | 策略生成 | 静态仿真 | 将 LLM 用作机器人代码评估的静态模拟器 |
| GenSwarm [ji2026genswarm] | 策略生成 | 多机器人控制 | 跨机器人智能体协调策略生成与部署 |
| NormCode [guan2025normcode] | 策略生成 | 受治接口 | 通过半形式化代码强制可审计性与数据隔离 |
| RACAS [ashley2026racas] | 策略生成 | 协作控制 | 闭环协作智能体的机器人无关架构 |
| Voyager [wang2023voyager] | 终身 | 技能库 | 面向开放式任务的自主课程 |
| LYRA [meng2025growing] | 终身 | 人在环路 | 将人类纠正编码为可复用的结构化技能 |
| ViReSkill [kagaya2025vireskill] | 终身 | 视觉 grounded | 利用技能记忆缓存在失败时重规划 |
| UI-Voyager [lin2026ui] | 终身 | 自演化 | 移动 GUI 智能体的拒绝微调与自蒸馏 |
| SkillsCrafter [wang2026lifelong] | 终身 | 持续技能 | 缓解可执行操作技能累积时的遗忘 |
2.2.1 grounded 技能选择
grounded 技能选择研究智能体如何通过可复用的技能接口将高层语言意图映射为可执行行为。这些系统不直接生成低层动作,而是把环境视为可执行能力的集合,智能体框架可以在环境约束下调用、组合并精炼这些能力。SayCan [ahn2022can] 通过将语言规划与 grounded 技能执行耦合奠定了核心范式——智能体不仅依据语义相关性选择行动,还考虑具身可行性。后续工作沿多个方向扩展这一执行接口。KnowNo [ren2023robots] 通过共形预测引入不确定性感知控制,使框架在不安全执行前检测模糊状态并触发澄清。BOSS [zhang2023bootstrap] 处理固定技能库的僵化问题——用语言引导的实践合成新的可执行技能链,使框架能随时间扩展行动空间。类似地,[ha2023scaling] 处理 grounded 交互的数据瓶颈——用 LLM 引导的生成构造多样的操作轨迹与可执行成功条件,以支持自动重试与重标注。除静态执行之外,LRLL [tziafas2024lifelong] 引入记忆与自我引导探索,以跨任务维护一个持久且演化的技能接口。最后,SkillVLA [zhai2026skillvla] 将这一范式扩展到组合式双臂交互——强调 grounded 行动接口必须在愈发复杂的具身环境下支撑结构化技能复用与重组合。
2.2.2 程序化策略生成
程序化策略生成把代码本身视为模型与环境之间的控制接口。框架不再从预定义技能中选择,而是直接把可执行策略物化为程序——指定控制逻辑、感知条件分支、反馈循环与 API 交互。CaP [liang2023code] 将这一范式具体化——把 LLM 生成的 Python 程序框定为可执行机器人策略。在此之上,RoboCodeX [mu2024robocodex] 引入多模态与树状结构的代码生成,以支撑更复杂的操作与导航行为。后续工作聚焦于扩展交互基质。RoboPro [xie2025robotic] 从大规模真实视频合成可执行策略代码;Code-BT [zhang2025codebt] 将生成的程序编译为行为树控制器,以支撑受约束执行与迭代式运行时反馈。除机器人之外,CP-Agent [szeider2025cp] 表明,持久执行循环可以通过迭代执行与修复支撑形式化约束求解智能体。为降低对昂贵物理环境的依赖,[wang2025llm] 将语言模型配置为机器人代码评估的静态执行模拟器。GenSwarm [ji2026genswarm] 把程序化控制进一步扩展到多智能体机器人系统——框架必须在多个具身智能体之间协调策略生成、约束分析与部署。在系统层面,NormCode [guan2025normcode] 强调治理与可审计性——引入半形式化编程接口并强制数据隔离,使执行轨迹与控制逻辑保持可检查与受约束。最后,ALRM [santos2026alrm] 与 RACAS [ashley2026racas] 把这些思想整合为持久的闭环控制架构——在统一的智能体框架中集成代码生成、执行、监控与迭代交互。
2.2.3 终身代码型智能体
终身代码型智能体研究可执行交互接口如何在长周期交互中持续存在、演化并积累能力。在这些系统中,代码不仅是执行机制,也是持久的记忆基质——框架借此存储可复用的行为、交互轨迹与环境知识。Voyager [wang2023voyager] 通过 Minecraft 中的自动课程与持续扩展的可执行技能库,为开放式交互奠定了这一范式。LRLL [tziafas2024lifelong] 将这一思想扩展到具身环境——引入持久记忆、自我引导的任务探索与技能抽象,以克服固定策略库的限制且无需梯度更新。终身框架面临的核心挑战是:交互反馈与纠正往往是短暂且难以复用的。LYRA [meng2025growing] 通过把人类纠正转化为可复用的可执行技能与检索增强的记忆结构来处理这一问题。ViReSkill [kagaya2025vireskill] 将视觉 grounded 重规划与技能记忆缓存相结合,以在环境失败与输出变异下维持稳定交互。近期工作进一步聚焦在持久部署下的持续适应与自演化。SkillsCrafter [wang2026lifelong] 引入持续的语言条件化操作结构,以缓解可执行能力累积时的灾难性遗忘;UI-Voyager [lin2026ui] 将自演化交互范式推广到 GUI 智能体——通过失败驱动的适应与自蒸馏实现。这些系统共同将一次性执行推向持久智能体框架——后者随时间持续扩展、精炼并复用可执行交互接口。
2.3 代码即环境
智能体还必须显式维护与其交互的环境的表征。若无此表征,环境就只能通过文本观测、API 返回值或稀疏反馈信号间接呈现给智能体。结果是环境状态常常是隐式、短暂、难以验证的——这使得跨长周期任务跟踪状态转移、评估交互结果或复用过往交互历史变得困难。这一限制在复杂软件、机器人及多步交互环境中尤为严重——成功交互依赖于在时间维度上保持一致的世界状态与 grounded 反馈。
“代码即环境”通过引入可执行程序作为环境接口本身来处理这一限制。这些系统不再把环境视为不透明的外部过程,而是通过模拟器、仓库、测试、执行轨迹、日志与状态转移程序等计算产物物化环境结构与动态。这使智能体能在整个交互过程中显式地存储、检查、执行并修改环境状态。通过可执行代码表示环境带来两大优势:第一,可执行环境暴露可验证的状态转移,允许智能体通过执行而非模糊的自然语言判断来评估交互结果;第二,基于代码的环境是持久、可修改的——智能体可以在交互中查询、仿真、编辑并精炼它们。智能体框架不再只能通过语言与不透明世界交互,而能将推理与行动 grounded 到显式的计算状态与运行时动态中。该方向的工作可以组织为四种范式:结构化世界表征、执行轨迹世界建模、代码 grounded 的评估环境与可验证环境构造。
表 3:代码作为环境表征的代表性系统。
| 方法 | 机制 | 环境范式 | 关键创新 |
|---|---|---|---|
| ViStruct [chen2023vistruct] | 结构化 | 类/对象层次 | 把视觉场景编码为数据结构 |
| FactoredScenes [hsu2025programs] | 结构化 | 房间程序 | 组合对象/关系函数生成 3D 布局 |
| PoE-World [piriyakulkij2025poe] | 结构化 | 程序化专家 | 将符号化世界模型扩展到简单网格世界之外 |
| Code2World [zheng2026code2world] | 结构化 | 渲染感知 RL | 把 GUI 状态预测重新表述为可渲染 HTML 生成 |
| SemCoder [ding2024semcoder] | 基于轨迹 | 语义对齐 | 把代码与详细执行轨迹配对 |
| WorldCoder [tang2024worldcoder] | 基于轨迹 | 基于模型的 RL | 合成转移与奖励模型 |
| CWM [copet2025cwm] | 基于轨迹 | 开源权重轨迹 | 在程序执行轨迹上原生训练大型 LLM |
| RWML [yu2026reinforcement] | 基于轨迹 | 自监督 RL | 把仿真的下一个状态与已实现的环境状态对齐 |
| AWM [wang2026agent] | 基于轨迹 | 世界建模 | 跨任务对齐多个可执行世界模型 |
| WorldMind [ren2026aligning] | 基于轨迹 | 模型融合 | 协调来自知识源的可执行世界模型 |
| SWE-bench [jimenez2023swe] | 评估 | 仓库级测试 | 把单元测试作为客观世界状态 |
| AgentBench [liu2023agentbench] | 评估 | 多环境交互 | 在 OS、数据库与游戏之间做基准 |
| CRUXEval [gu2024cruxeval] | 评估 | 执行任务 | 对功能输入与输出预测做基准 |
| End Terms. [gandhi2026endless] | 评估 | 程序化 RL 环境 | 自动化终端使用评估任务的生成 |
| InterCode [yang2023intercode] | 评估 | 交互式执行 | 把编程任务框定为带沙盒反馈的行动 |
| LiveCodeBench [jain2024livecodebench] | 评估 | 实时编程评估 | 持续更新基于执行的评估流水线 |
| CRUXEval-X [xu2025cruxeval] | 评估 | 多语言执行 | 把输入-输出执行评估扩展到多种语言 |
| CoRe [xie2025core] | 评估 | 运行时推理 | 通过执行中心任务评估代码推理 |
| CodeGlance [wang2026codeglance] | 评估 | 多模态代码评估 | 在视觉与结构化场景下评估代码理解 |
| SWE-smith [yang2025swesmithscalingdatasoftware] | 构造 | 合成 SWE 环境 | 生成仓库级任务与执行环境 |
| EnvScaler [song2026envscalerscalingtoolinteractiveenvironments] | 构造 | 工具交互环境 | 合成带程序化验证器的工具使用环境 |
2.3.1 结构化世界表征
结构化世界表征通过智能体可以执行、检查与操作的显式程序结构来建模环境。这些方法不仅通过隐变量或文本描述表征环境,还把世界状态、对象关系、空间布局与交互动态编码为结构化的计算产物。例如,ViStruct [chen2023vistruct] 用编程语言结构作为视觉结构化知识提取的显式接口,使多粒度视觉事件能通过一致的可执行结构表征。FactoredScenes [hsu2025programs] 类似地把室内环境建模为组合式”房间程序”——可复用的对象与关系函数定义物理一致的场景布局。在此基础上,PoE-World [piriyakulkij2025poe] 引入组合式框架——结合许多小型程序化专家来表征日益复杂的环境动态。更近的系统把结构化环境接口扩展到高保真交互世界。Code2World [zheng2026code2world] 把 GUI 状态预测重新表述为可渲染 HTML 生成——允许通过可执行渲染代码来表征与评估环境转移。Code2Worlds [zhang2026code2worlds] 进一步把这一范式扩展到 4D 仿真环境——通过语言到仿真程序生成,物理感知的执行循环在环境构造与交互期间减少语义-物理不一致。
2.3.2 执行轨迹世界建模
执行轨迹世界建模研究智能体如何直接从可执行交互轨迹学习环境动态。这些方法不再仅把执行作为最终评估步骤,而是把运行时转移本身建模为环境行为的主要表征。SemCoder [ding2024semcoder] 通过训练语言模型对功能行为、语句级执行效果与输入-输出转移进行推理,弥合静态程序与运行时语义。Code World Model(CWM)[copet2025cwm] 在此基础上直接从程序轨迹学习预测性世界模型,使智能体能通过可执行动态预见未来环境状态。WorldCoder [tang2024worldcoder] 进一步引入基于模型的交互框架——智能体显式撰写并更新表示为 Python 程序的可执行世界模型。智能体不再仅在模型参数中隐式存储环境知识,而是维护可在规划与交互中执行、修订与复用的可编辑计算表征。后续工作把这一范式扩展到持续与交互式世界模型适应。RWML [yu2026reinforcement] 将执行轨迹与强化学习结合,通过运行时交互精炼环境动态;AWM [wang2026agent] 与 WorldMind [ren2026aligning] 研究如何在任务与知识源之间对齐、融合并协调多个可执行世界模型。
2.3.3 代码 grounded 的评估环境
代码 grounded 的评估环境用可执行系统作为衡量智能体行为与交互质量的接口。与仅基于文本输出的静态基准不同,这些环境暴露显式的运行时状态转移、执行反馈与可验证的交互结果,智能体可以直接观察并评估它们。InterCode [yang2023intercode] 通过把编程任务重新框定为交互式执行环境奠定了这一范式——代码充当行动,执行反馈作为观测,沙盒化运行时提供 grounded 交互。CRUXEval [gu2024cruxeval] 进一步通过可执行输入-输出预测任务评估程序理解;LiveCodeBench [jain2024livecodebench] 引入持续更新的评估流水线——在演化的问题分布下评估执行、自修复与运行时推理能力。SWE-bench [jimenez2023swe] 将可执行评估扩展到真实软件仓库——智能体必须修改大规模代码库,并通过仓库级单元测试执行而非仅靠文本正确性来评估。更广义上,AgentBench [liu2023agentbench] 表明可执行交互环境可以在多样的具身与数字任务上评估推理与决策。后续基准如 CRUXEval-X [xu2025cruxeval]、CoRe [xie2025core]、GeoGramBench [luo2025geogrambench]、CodeGlance [wang2026codeglance] 与 Endless Terminals [gandhi2026endless] 进一步把这一范式扩展到多语言、多模态与持续交互的评估场景——运行时交互而非静态答案匹配成为主要评估接口。
2.3.4 可验证环境构造
一个较新的方向把可执行环境不仅视为评估智能体的基准,而且视为可以程序化合成、扩展并验证的框架产物。这对长周期智能体尤为重要——框架不仅要提供任务提示,还要提供可运行的状态、转移动态、反馈通道与验证 oracle。SWE-smith [yang2025swesmithscalingdatasoftware] 通过从现有代码库构造仓库级任务与执行环境,扩展软件工程智能体数据——把软件仓库转化为可复现的程序世界,用于智能体训练与评估。EnvScaler [song2026envscalerscalingtoolinteractiveenvironments] 把这一思想从软件工程扩展开来——程序化地合成工具交互环境,连同场景与基于规则的轨迹验证器。从框架视角看,这些方法把环境接口本身变成构造的对象:代码不仅规定智能体编辑或执行什么,还规定决定交互成功与否的状态转移、工具 affordance 与验证器。
3 框架机制:规划、记忆、工具使用、控制与优化
框架机制是让代码化智能体在超越单步生成的尺度上保持可靠的核心系统层。一旦代码进入智能体循环,软件生成就不再仅仅是”从提示中产出正确程序”的问题,而成为模型、可变任务状态与人工设计的框架基础设施之间的交互。模型负责判断:它分解目标、选择行动、解读反馈,并决定何时修订。可变状态记录仓库证据、工作上下文、执行轨迹、验证结果、记忆与对任务的中间信念。框架基础设施暴露工具与执行基质,持久化并压缩状态,通过策略与权限层级约束行动,路由反馈,并核验每次状态转移是否可接受。从这个视角看,框架机制不是孤立的附加模块,而是协调的控制面——把模型决策转化为在可执行环境中”有界、可观察、可修订”的变化。在基本形式中,代码让智能体可以调用既有的可执行接口。进一步地,智能体可以动态撰写任务专属的可执行接口。这些智能体撰写的产物让框架更具自适应性——因为执行环境能围绕当前任务重新塑形。但动态撰写的代码并不取代更广泛的人工设计框架基础设施。可靠性仍依赖于模型侧的判断,与人工设计的策略、沙盒边界、权限层级、验证 oracle、审计日志与人审关卡相结合。代码因此作为框架内部的可执行媒介,而框架仍是更大的、由策略治理的系统——决定哪些代码可以被执行、信任、持久化、复用或晋升为未来工作流。
本节综述代码智能体的五类相互作用的框架机制。规划(§3.1)通过把目标外化为分解、结构化约束、搜索轨迹或工作流编排来组织长周期任务执行。记忆与上下文工程(§3.2)在长交互中管理可变状态——保存工作上下文、检索仓库证据、存储可复用经验、支持共享历史,并把状态卸载到当前上下文窗口之外。工具使用(§3.3)把智能体连接到受治的可执行接口,包括 API、仓库、终端、沙盒、验证工具与工作流编排器。基于”计划-执行-验证”(Plan-Execute-Verify, PEV)循环的框架控制(§3.4)把反馈引导的调试重新框定为更广义的控制过程:计划构成对预期变更的契约,执行在沙盒化和权限化的环境中应用变更,验证用确定性传感器与人审关卡决定状态应被接受、修订、上升或回滚。最后,智能体式框架工程(§3.5)研究框架本身如何通过深度遥测、演化智能体、基于回放的评估与受治的框架变更来度量并改进。
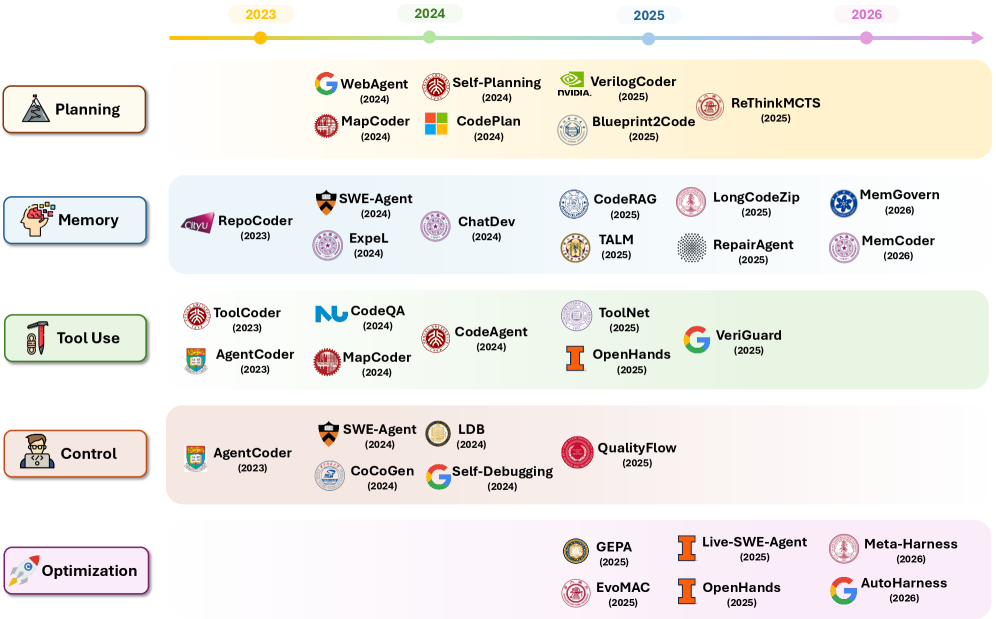
图 4:智能体框架机制的路线图概览。
3.1 面向智能体框架的规划
规划在智能体框架中起核心作用,因为现实软件工程任务很少能从自然语言意图一步映射到正确实现。从框架视角看,规划不仅是 LLM 的内部推理能力,更是一种框架控制形式——它构造智能体如何把意图外化为可执行步骤,调度与代码产物和工具的交互,并随时间规范推理、执行与修订的轨迹。除了生成代码 token 之外,一个有效的智能体框架还必须把长周期问题求解组织为连贯的行动方案——决定追求哪些中间目标、以何种顺序执行它们、检查或修改哪些产物,以及当执行反馈揭示错误、缺失依赖或被违反约束时如何修订轨迹。这一需求在仓库级编辑、Web 交互、竞赛编程与硬件设计中尤为突出——智能体必须在大型行动空间、稀疏反馈与深度耦合的子问题上运作。在这些场景中,目标任务的复杂性与无约束智能体执行的有限可靠性之间存在根本张力:若无显式的规划机制作为框架控制,智能体可能过早承诺于脆弱的求解路径、忽视隐含依赖,或无法把推理、检索、执行与修订协调为稳定的工作流。
早期面向规划的系统主要把规划视为线性分解步骤——模型先产出自然语言解题大纲,再翻译为代码。但随着代码智能体应用于更复杂的环境,规划逐渐从简单的预生成支架演化为更丰富的框架层控制机制。它可以 grounded 在仓库结构或外部知识上以约束智能体的行动空间;可以通过对多条候选轨迹的显式搜索而扩展以提高鲁棒性;或者可以分布到专门化的智能体角色与反馈循环中,以在系统层级协调执行。根据框架控制的主要落点,我们把代码智能体中的现有规划方法归为四类:线性分解规划、结构 grounded 规划、基于搜索的规划与基于编排的规划。
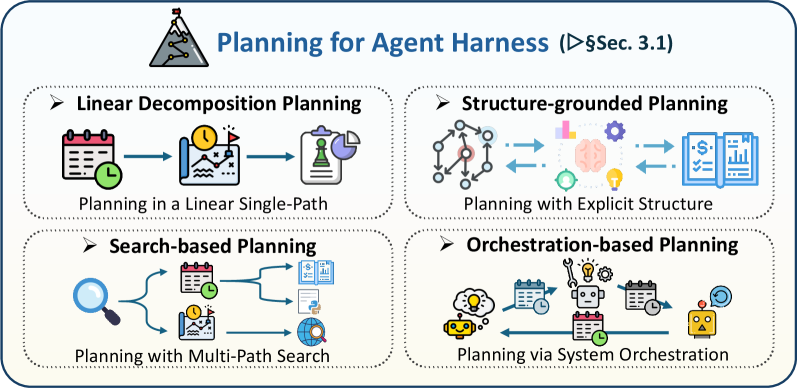
图 5:面向智能体框架的规划机制概览。
3.1.1 线性分解规划
在这一规划范式中,智能体先产出一个显式的可执行步骤序列,然后按照该分解执行生成 [huang2024knowledge, jiang2024selfplanning, gur2023webagent, linearplan1, zhang2025linearplan2]。该模式的轻量级前身是 ReAct [yao2023reactsynergizingreasoningacting]——智能体在串行轨迹中交错思考、行动与观察。在该框架中,每个推理步骤外化当前子目标并约束下一行动,使轨迹本身成为分步的控制框架。这一模式最直接的实例是 Self-Planning [jiang2024selfplanning]:模型先把意图分解为简洁、高层、带编号的步骤,再在该计划的指导下逐步生成代码。Plan-And-Act [erdogan2025plan] 把这一框架进一步显式化——分离出一个规划者(产出结构化的高层计划):规划者随新观察到来反复刷新线性脚手架,使规划策略在保持任务级控制的同时适应环境反馈。WebAgent [gur2023webagent] 把这一思想扩展到 Web 自动化:它把用户指令分解为相继的子指令,基于当前子目标对任务相关的 HTML 进行摘要,然后从该线性子指令序列合成可执行的 Python 行动。KareCoder [huang2024knowledge] 在知识增强场景中遵循类似模板——模型先从外部知识库构造一个知识感知的分步提示,然后用该提示生成代码,使规划成为问题理解与实现之间的结构化中间层。近期工业实践表明,这种线性脚手架可以从短暂的提示产物提升为持久的框架对象。在长周期编码工作流中,PLAN.md、Implement.md 与状态日志等文件记录里程碑、验收标准、验证命令与恢复规则,使智能体能够跨上下文重置或多会话执行重新加载、更新、验证并记录进度 [openai2025execplans, openai2026codexlonghorizon]。从这一视角看,规划不再仅是内部推理痕迹,而是文件系统支撑的控制对象:它可以被人类审阅、与 Git 一同版本化、由子智能体消费、并作为实现的可信来源。其主要局限在于:这些方法通常承诺于单一分解轨迹——当初始计划不完整或对齐失败时,框架可以提升持久性与可审计性,但在选定路径之外的探索仍然有限。
3.1.2 结构 grounded 规划
在这一脉络的工作中,智能体不仅从自由形式的自然语言提示导出行动序列,而且把规划 grounded 到任务环境的显式结构化表示上,例如依赖图、仓库图、电路图或知识图。这些结构充当天然的框架脚手架:暴露相关实体、编码依赖关系,并引导子任务被生成、修订或验证的顺序。例如,CodePlan [bairi2024codeplan] 在编辑义务上构造计划图,并通过依赖分析与变更影响传播导出新步骤。仓库理解方法 [luo2025rpg, chen2025locagent, tao2025cgm, luo2025rpg] 把代码库转换为异构图或富文本的代码图,然后用图集成推理来定位相关实体,并把下游生成条件化于结构性依赖而非扁平文本上下文。GraphCodeAgent [li2025graphcodeagent] 用双图框架扩展这一思路——需求图捕捉自然语言需求间的关系,结构-语义代码图捕捉仓库依赖。同样原理也出现在近期智能体原生仓库实践中。架构笔记、API 规范与测试指南等文件,把项目知识转化为持久、可检查、版本控制的产物,智能体在行动前可以参考 [agentsmd2025, openai2026agentsmd, anthropic2025claudememory]。这使结构 grounded 规划超越图构造:相关结构决定了显式规则、构建命令、目录边界、编码约定与设计约束,从而在程序上促进一致而稳定的框架控制。专门领域遵循同样模式 [wang2026domagent, ho2025verilogcoder]。VerilogCoder [ho2025verilogcoder] 把子任务规划 grounded 到任务与电路关系图上,使每个子任务都富有信号、转移与示例;DomAgent [wang2026domagent] 用知识图将自顶向下的结构化知识与自底向上的示例结合,用于领域特定代码生成。总体上,这些工作表明,结构 grounded 规划通过把项目或领域知识转化为显式可检查的框架对象,提升一致性、依赖感知与长周期一致性,从而引导智能体随时间的行为。
3.1.3 基于搜索的规划
基于搜索的规划分配推理时计算,系统地探索、评估并在多条候选解题路径之间选择。这一思路不再让智能体承诺于单一计划,而是扩展决策空间并用反馈控制哪些选项应被追求、修订或舍弃。第一组方法 [wang2024planning, li2025rethinkmcts] 在思想空间中实例化该框架。它们不直接写代码,而是先在高层观察、策略或推理轨迹上分支,目标是在实现之前提升概念多样性。从这一视角看,更好的规划来自覆盖更广的思想空间并用反馈精炼推理本身,而非仅修复最终代码。第二组 [li2025codetree, ni2024treeofcode, dainese2024codegenerating, aggarwal2025dars] 在编码行动的轨迹空间中执行搜索:把编码建模为在策略选择、实现、调试与修订上的分支过程,并依据执行信号或学习的批评者决定哪些节点应被扩展。因此,长周期编码质量随智能体能从次优决策回溯并比较部分轨迹而提升。另一类工作(如 ReLoc [lyu2025reloc] 与 SFS [light2025sfs])把规划视作在代码空间中的搜索。这些方法在验证反馈或细粒度评分信号指导下,通过变异、修订或局部优化迭代探索邻近程序。除上述方法外,近期系统越来越把候选计划、补丁、日志、测试与执行轨迹视为持久产物而非短暂生成。SWE-Search [sweSearch2024] 把蒙特卡洛树搜索与软件工程智能体结合,探索替代修复轨迹;CodeTree [li2025codetree] 在统一树中组织策略探索、解生成与精炼。更广义地,Meta-Harness [lee2026metaharness] 把这一思想推进到框架层面本身:通过让智能体经由文件系统访问先前的源代码、分数与执行轨迹,在框架代码上进行搜索。这些进展表明,基于搜索的规划不仅是模型侧的采样策略,也是框架层的状态管理问题:运行时必须保留候选项、暴露证据、运行验证器,并决定哪个分支值得进一步计算。
表 4:代码智能体的代表性规划模块。
| 方法 | 类别 | 核心机制 | 接口 | 反馈 |
|---|---|---|---|---|
| Self-Planning [jiang2024selfplanning] | 线性分解 | 分步分解 | 共享提示 | 无 |
| WebAgent [gur2023webagent] | 线性分解 | 子指令排序 | API | 运行时异常 |
| CodePlan [bairi2024codeplan] | 结构 grounded | 计划图 | 仓库图 | 批评 |
| VerilogCoder [ho2025verilogcoder] | 结构 grounded | 任务-电路关系图 | 仓库图 | 测试通过/失败 |
| Tree-of-Code [ni2024treeofcode] | 基于搜索 | 轨迹树搜索 | 执行环境 | 测试通过/失败 |
| ReThinkMCTS [li2025rethinkmcts] | 基于搜索 | 推理路径 MCTS | 执行环境 | 批评、测试 |
| MapCoder [islam2024mapcoder] | 基于编排 | 角色编排 | API | 批评、测试 |
| Blueprint2Code [mao2025blueprint2code] | 基于编排 | 蓝图到代码 | 仓库接口 | 批评 |
3.1.4 基于编排的规划
基于编排的规划指核心规划功能通过系统级协调的框架设计实现的范式。在该范式中,框架治理智能体或模块如何专门化角色、执行阶段、路由反馈并触发验证循环,从而决定长周期代码生成工作流中下一步应采取的行动。第一种常见模式 [huang2023agentcoder, ukai2024adacoder, Nunez2024AutoSafeCoder] 是反馈中心的编排——系统把编码、测试、分析与修复分发到不同模块,使进度由反复的执行 grounded 反馈与自适应升级驱动。在这组中,规划不是预先产物,而是从失败如何被检测、解读并路由回后续行动中涌现的属性。第二种模式 [islam2024mapcoder, Pan2025CodeCoR, mao2025blueprint2code] 是分阶段工作流编排,把代码生成铸造为结构化的软件过程流水线——例如理解、检索或预览、规划或蓝图、编码、调试与修复。该组的主要优势在于把复杂生成分解为可解释的阶段,带有显式的交接规则,实际的规划力量来自跨阶段控制、候选剪枝与迭代式精炼。第三种模式 [khan2025macog, doualgoforge, zhang2026sgagent, lu2025requirements] 是控制器中心的编排——规划嵌入到中间产物的变换与路由基质本身中。这里,系统通过形式化规范流水线、定位与修复之间的建议阶段、有类型的中间表示、共享黑板或专门的规划者-编码者协调等机制组织决策——下一步计划由脚手架的控制逻辑而非单一文本提示决定。
近期框架系统让这一编排视角尤为显式。Anthropic 的长时运行框架把规划、生成与评估分离为不同角色,通过结构化产物与独立评估在长会话中保持进度 [anthropic2025longrunning, anthropic2026longrunningapps]。Cursor 的大规模自主编码实验同样强调规划者-工人协调——作为从聚焦的单智能体任务扩展到许多并行智能体共同工作于一个项目的方式 [cursor2026scalingagents]。最一般化的表述出现在自然语言智能体框架中——高层框架逻辑(如角色、阶段、契约、适配器、状态约定与失败分类法)以可编辑的自然语言书写,并由”智能框架运行时”(Intelligent Harness Runtime, IHR)执行 [pan2026nlah]。IHR 在运行时解释这些高层自然语言指令,把它们转化为显式契约、预算、工具接口与环境状态下的受约束执行步骤。这把基于编排的规划重新框定为运行时解释问题:计划不仅是文档,而是一种可执行的框架规范——在模型输出、文件系统状态、工具、验证器与多智能体委派之间充当中介。
**小结:**代码生成的规划可以理解为智能体框架的核心形式——一个控制层,组织 LLM 智能体如何分解任务、把决策 grounded 到程序结构、在推理时探索替代方案、并协调多阶段软件工程工作流。从这一视角看,规划是围绕一个本质问题展开的一组框架机制:如何决定智能体接下来应该做什么,以及如何在长周期编码任务中保持该决策过程受约束、可检查、连贯。值得注意的是,代码生成中的规划无法与评估问题清晰分离。许多关于规划益处的当前结论严重依赖于周围执行条件——包括执行环境、反馈质量、工具访问、轨迹预算,以及基准是否真正考验长程依赖管理而非局部补丁生成。若执行信号弱、修订预算不现实,或基准未能暴露多步协调错误,那么报告的规划收益可能并未反映智能体级问题求解的真实改进。因此,规划不仅是方法设计问题,也是智能体与环境之间的框架问题。展望未来,核心挑战不仅是构建更大的规划者或更长的推理轨迹,而是设计更可靠的规划智能体框架:自适应承诺机制(决定何时跟随、修订或放弃计划)、结构上有意义的规划状态(暴露依赖与进度)、高效的探索-修订策略(在不过度计算的前提下使用反馈),以及严格的长周期评估范式(能在最终通过率之外忠实度量规划质量)。
3.2 面向智能体框架的记忆与上下文工程
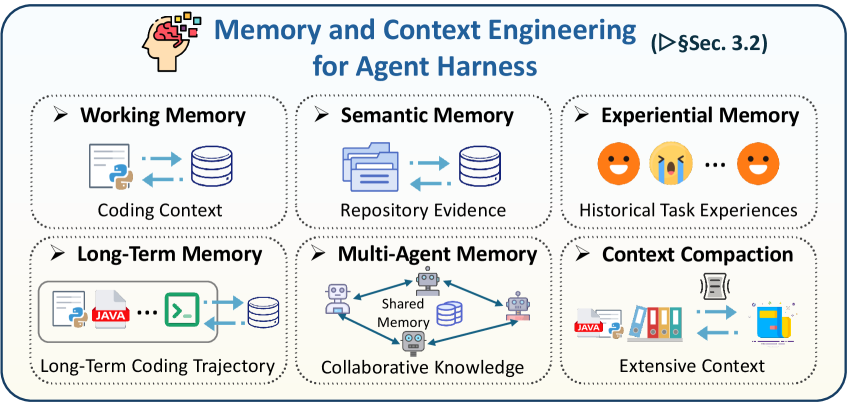
图 6:面向智能体框架的记忆与上下文工程机制概览。
记忆已成为代码智能体的核心基础设施,主要因为现实软件工程任务本质上是长周期且状态密集的 [dong2025survey, huang2026rethinking]。与单轮代码补全不同,实际编码场景要求智能体跨多轮交互维持一系列相互依赖的步骤,例如需求理解、代码定位、证据检索、多文件编辑、测试执行、缺陷修复与回归验证 [xia2025demystifying, zhang2025survey]。这在模型有限的上下文窗口与持续扩张的任务中间状态之间造成根本张力。从框架视角看,记忆不只是更大的上下文窗口或一个向量数据库。它是一个状态管理层,决定哪些信息应保留在活跃模型上下文中、哪些应压缩为摘要、哪些应卸载到持久外部存储 [zhou2026externalization]。若无有效的记忆机制与上下文管理,智能体在长程推理中容易丢失关键线索、重复已完成的搜索与分析,或在后续修改中破坏更早步骤中建立的局部一致性 [zhang2025ragsurvey, huang2026rethinking]。
早期系统主要依赖提示来保留历史信息,把记忆视为不过是会话历史或非结构化的草稿板。然而,随着仓库级修复等长周期编码任务的出现,人们越来越清楚地认识到:简单累积自然语言历史无法可靠地支撑复杂软件工程循环 [jiang2026survey]。结果是,记忆越来越多地外化为可检索、可治理、可追踪的系统组件。本节按记忆在软件工程循环中的主要功能角色对代码智能体的记忆进行分类。在此视角下,现有方法可大致分为五种类型:工作记忆、语义记忆、经验记忆、长期记忆与多智能体记忆。此外,我们将上下文压缩与状态卸载作为横切的上下文工程机制,讨论它们如何决定大型执行产物在活跃模型上下文与持久任务状态之间的移动。代表性工作见表 5。
3.2.1 工作记忆
工作记忆支撑沿当前编码任务轨迹的状态维护 [huang2025language]。其核心关切不在于保留多少历史,而在于在有限的上下文预算下哪些信息对下一行动最有用。在代码智能体中,工作记忆常表现为结构化的提示区段、状态摘要、失败测试记录、文件列表或关键栈信息。其目的在于缓解上下文爆炸、减少重复定位、并保持正在进行的修复或编辑轨迹的局部一致性 [yang2024swe, xia2025live, bouzenia2025repairagent, gaurav2025codemem]。从框架视角看,工作记忆是模型与代码环境之间的活跃控制面:它决定智能体在选择下一工具调用、编辑或验证步骤前观察到什么。SWE-agent [yang2024swe] 与 RepairAgent [bouzenia2025repairagent] 等代表性系统表明,即便底层模型相同,仓库级修复性能也可能因交互状态与执行反馈的组织方式而显著变化。CodeMem [gaurav2025codemem] 同样把上下文视为受管资源——通过预算化记忆槽稳定多步编辑。
3.2.2 语义记忆
语义记忆为当前编码过程提供任务相关的外部证据 [wu2025human, huang2026rethinking]。在代码智能体设置中,这种证据通常是仓库特定且程序结构化的——包括类定义、函数实现、调用关系、配置文件、文档、issue 描述、依赖元数据与历史实现模式。语义记忆因此把外部代码库转化为可查询的证据空间——框架可以从中检索并注入活跃上下文 [zhang2024autocoderover, zhang2024codeagent, biswal2026agentsm, zhang2025coderag, phan2025repohyper]。AutoCodeRover [zhang2024autocoderover] 与 RepoCoder [zhang2023repocoder] 等代表性工作表明,仓库级编码任务的收益不仅来自检索更多内容,更来自检索与程序结构对齐的证据。基于 AST 的结构化分块、迭代式查询重写、以当前定位线索为条件的检索策略等机制,可显著提升所检索上下文对下游生成的效用。从这一意义上说,语义记忆把代码库变为当前决策过程的结构化证据层。
表 5:代码智能体框架的代表性记忆与上下文管理机制。
| 方法 | 角色 | 管理状态 | 框架操作 | 主要用途 |
|---|---|---|---|---|
| SWE-agent [yang2024swe] | 工作记忆 | 修复轨迹;运行时状态 | 结构化状态跟踪 | 在文件、命令与测试上 grounded 仓库修复 |
| CodeMem [gaurav2025codemem] | 工作记忆 | 上下文槽;编辑状态 | 预算化槽管理 | 在上下文限制下稳定多步编辑 |
| RepairAgent [bouzenia2025repairagent] | 工作记忆 | 缺陷证据;工具输出 | 动态提示-状态更新 | 在自主循环中携带证据 |
| AutoCodeRover [zhang2024autocoderover] | 语义记忆 | 仓库结构;代码证据 | 结构感知检索 | 在仓库结构上 grounded 定位与修补 |
| RepoCoder [zhang2023repocoder] | 语义记忆 | 检索仓库上下文;片段 | 迭代式仓库检索 | 为上下文感知生成扩展证据 |
| CodeRAG [zhang2025coderag] | 语义记忆 | 仓库知识;代码路径 | 查询;多路径检索;重排 | 为长上下文补全选择仓库知识 |
| MemGovern [wang2026memgovern] | 经验记忆 | 轨迹;反思;批评 | 受治经验回放 | 复用高质量经验并过滤噪声 |
| ExpeL [zhao2024expel] | 经验记忆 | 反思轨迹;学到教训 | 反思回放 | 把反思作为任务求解策略复用 |
| MemCoder [deng2026your] | 长期记忆 | 提交;根本原因;已验证修复 | 结构化记忆;自我内化 | 学习仓库特定的意图到代码映射 |
| TALM [shen2025talm] | 长期记忆 | 任务历史;推理轨迹;已验证代码 | 向量检索;整合 | 为树状生成复用过去回合 |
| MIRIX [wang2025mirix] | 多智能体记忆 | 跨智能体状态;交互历史 | 跨智能体记忆路由 | 在专门角色间路由共享记忆 |
| ChatDev [qian2024chatdev] | 多智能体记忆 | 对话历史;软件产物 | 阶段级上下文传递 | 在基于角色的阶段间维持上下文 |
| LongCodeZip [shi2025longcodezip] | 上下文压缩 | 长代码上下文;仓库片段 | 粗粒度到细粒度压缩 | 在保留推理线索的同时压缩代码 |
| SWE-Pruner [wang2026swe] | 上下文压缩 | 交互上下文;周围代码 | 任务感知剪枝 | 在智能体决策前移除无关上下文 |
| SWEZZE [jia2026compressing] | 上下文压缩 | issue 上下文;修复要素 | 轻量级学习压缩 | 提炼紧凑、与修复相关的证据 |
3.2.3 经验记忆
随着代码智能体从单任务完成走向持续修复与跨项目泛化,经验记忆或情景记忆受到越来越多关注 [dong2025towards, huet2025episodic]。与维护当前轨迹的工作记忆,或检索仓库证据的语义记忆不同,经验记忆捕捉跨任务积累的可复用经验——例如修复轨迹、失败案例、调试记录与更高层的策略模式 [zhao2024expel, wei2025evo, liang2026generalizable]。其主要价值在于支持跨任务迁移。通过经验卡、反思缓冲与录制回放等机制,系统可以把过去成功或失败的调试过程转化为未来问题求解的可复用单元 [wei2025evo, wang2026memgovern, chu2024leveraging]。MemGovern [wang2026memgovern] 等工作进一步表明:存储经验的质量比规模更重要。未受治理的历史记录可能引入语义噪声、错误传播与错误检索,而经过整理和质量控制的经验记忆更有可能成为仓库级修复的有用资产。
3.2.4 长期记忆
当编码轨迹变长时,工作记忆与语义记忆已不足够——系统还必须应对记忆增长、压缩引起的证据失真与长期漂移。这使得长期检索规划与记忆控制成为越来越重要的研究方向 [maharana2024evaluating, wang2026memex, bei2026mem, zhao2026papermind, ning2026mcsearch]。关注点因此从记忆容量转移到记忆治理。MemGPT [packer2023memgpt] 与 MemoryOS [kang2025memory] 等代表性系统把讨论从”存什么”推进到”何时写、何时压缩、何时检索、如何避免污染”。最近的代码中心研究把这条线索 grounded 到软件工程工作流中。MemCoder [deng2026your] 利用结构化的历史提交与人工验证的解答作为持久记忆,使仓库特定经验随时间积累。TALM [shen2025talm] 把长期记忆纳入多智能体代码生成——检索先前的问题-解答轨迹并整合重叠记忆以控制冗余。这些工作表明:对代码智能体而言,长期记忆不应仅累积更多历史,而应以紧凑且可控的形式保留经过验证、可复用的经验。否则,记忆可能从长周期软件工程的资源变成放大噪声、陈旧与错误的负担。
3.2.5 多智能体记忆
多智能体记忆把状态管理从个体智能体扩展到共享框架。从系统视角看,代码生成中的记忆具有强烈的协作维度 [li2025swe, chen2023gamegpt]。在多智能体框架中,记忆不仅是个体状态的容器,也是跨专门角色的信息共享、意图传递与一致性维护的媒介 [zhang2025gmemory]。AgentCoder [huang2023agentcoder]、MapCoder [islam2024mapcoder]、MIRIX [wang2025mirix]、ChatDev [qian2024chatdev] 与 G-Memory [zhang2025gmemory] 等代表性工作展示了记忆如何支撑多智能体规划、测试、审查与轨迹协调。在这一场景中,核心挑战不再仅是检索相关内容,而是控制共享粒度、防止信息泛滥,并支持高层决策与细粒度执行轨迹之间的双向访问 [chen2023gamegpt]。因此,多智能体代码生成中的记忆越来越类似共享黑板或协作状态图,而非纯个体存储单元 [Ishibashi2024SelfOrganized, yuan2025graphs]。
3.2.6 上下文压缩与状态卸载
上下文压缩与状态卸载是代码智能体框架中记忆的横切上下文工程机制 [liu2026dive]。它们的目标不是定义另一种记忆类别,而是控制活跃模型上下文与持久任务状态之间的边界。长周期软件工程工作流持续生成大量产物,例如构建日志、执行轨迹、仓库差异、测试输出与中间计划。直接把这些产物放入提示会迅速过载上下文窗口、放大噪声并掩盖与决策相关的证据。因此,框架必须决定哪些观测应保留在活跃上下文中,哪些应压缩为简洁摘要,哪些应卸载到带可检索句柄的外部存储 [zhou2026externalization]。上下文压缩把长交互历史与海量工具输出压缩为结构化、保留出处的摘要。例如,失败测试报告可以被简化为失败测试名、关键栈帧、可疑文件与到完整日志的链接 [jia2026compressing, sun2025scaling, shi2025longcodezip, wang2026swe]。状态卸载通过把全保真度产物保留在活跃窗口之外来补充这一过程,例如保存到文件、数据库、轨迹存储或协议风格的资源接口(如 MCP 风格服务器)。智能体随后接收紧凑摘要与资源标识符,而非原始日志或轨迹。通过分离决策相关上下文与持久证据,上下文压缩与状态卸载使记忆更具可扩展性、可审计性,并与执行时验证兼容。
**小结:**代码即智能体框架系统中的记忆可以理解为统一的状态管理层——连接上下文管理、仓库证据检索、经验迁移、长期控制与多智能体同步。记忆不是单一数据结构、扩大的上下文窗口或简单的向量数据库,而是协调任务相关状态应驻留何处、以及如何在长周期软件工程工作流中复用的机制。工作记忆把下一行动 grounded 到位;语义记忆暴露仓库证据;经验记忆支持跨任务迁移;长期记忆保留经验证的知识;多智能体记忆在角色间同步共享状态。上下文压缩与状态卸载进一步把这一层扩展开——分离决策相关的活跃上下文与持久全保真度产物,使记忆更具可扩展性、可审计性,并与执行时验证兼容。重要的是,代码智能体中的记忆研究不能与评估可靠性分离。许多关于记忆收益的结论依赖于评估流水线的质量 [jimenez2024swebench, feng2026longcli]:若测试不充分、日志解析有缺陷,或基准受到记忆与污染影响,那么报告的改进可能并未反映稳健的长周期行为。展望未来,核心挑战不仅是扩大记忆容量,更是构建更高质量的写入门、结构对齐的检索键、保留出处的压缩机制、可靠的状态卸载协议,以及严格的评估范式——能够度量记忆是否真正帮助智能体在长轨迹上保持 grounded、一致与可验证。
3.3 面向智能体框架的工具使用
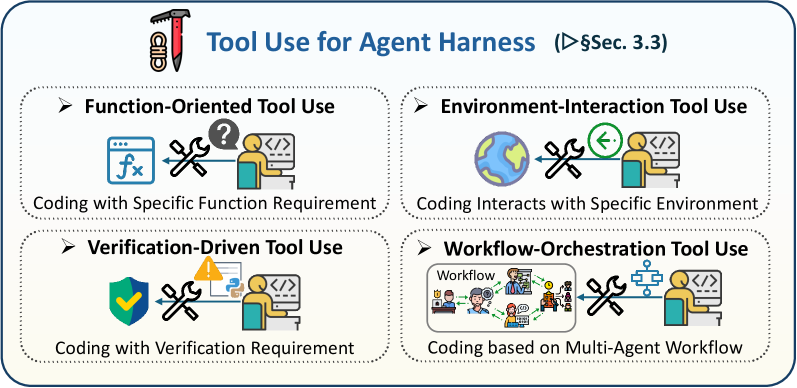
图 7:面向智能体框架的工具使用机制概览。
工具使用是代码智能体框架的行动与观察层。一旦代码进入智能体循环,模型不仅必须生成文本,还必须搜索仓库、编辑代码、执行测试、调用 API、查询文档并验证中间结果 [watanabe2025use, sapkota2025vibe]。工具因此扩展智能体的行动空间,同时暴露外部反馈信号,使框架变得可执行且可检查。从代码即智能体框架的视角看,工具使用不仅是代码生成的辅助能力,而是模型意图与外部系统之间的受治接口。可靠的框架必须决定哪些工具可用、它们的模式如何暴露、每个工具获得何种权限、执行发生在哪里、结果如何被净化或压缩,以及何时危险行动需要人审。近期智能体 SDK 与软件智能体平台明确这一转变——把工具、会话、护栏、交接、工作区与执行环境打包为可复用的框架组件 [wang2024openhands, meng2026agent, xi2025agentgym]。与此同时,沙盒化执行环境(包括容器或基于 microVM 的工作区)将智能体行动与宿主系统隔离,使代码执行更可复现、更可审计 [cheng2026llm, wang2024executable, wang2025ui]。这一框架层视角也凸显了工具生命周期控制的重要性。在工具执行前,框架可以应用权限检查、策略规则、参数验证或人在环路关卡。执行后,框架可以净化输出、摘要大日志、把轨迹卸载到持久存储、更新记忆或触发验证工具。生命周期钩子使这些控制点显式化。它们把工具使用从原始的模型选择行动转化为智能体执行循环中的受监控转移。
代码智能体的现有工具使用工作可按工具所服务的主要框架功能组织:(1) 功能导向的工具使用,(2) 环境交互的工具使用,(3) 验证驱动的工具使用,(4) 工作流编排的工具使用。功能导向工具把智能体 grounded 到 API、库与外部文档。环境交互工具让智能体在仓库、终端、IDE、浏览器与沙盒内行动。验证驱动工具通过测试、Linter、类型检查器、静态分析器与运行时错误提供确定性反馈。工作流编排工具把多种工具、角色、记忆更新与生命周期策略协调为可靠的长周期执行过程。代表性工作见表 6。
表 6:代码智能体框架的代表性工具使用机制。
| 方法 | 角色 | 工具边界 | 框架操作 | 主要用途 |
|---|---|---|---|---|
| ToolCoder [zhang2023toolcoder] | 功能导向 | API 搜索工具 | 通过触发预测选择 API | 把生成 grounded 到检索的 API |
| CodeQA [ahmed2024codeqa] | 功能导向 | API/文档查询工具 | 工具增强的 API QA | 为编码检索 API 证据 |
| RAG-for-Code [zhao2025rag] | 功能导向 | 仓库、文档、API | 检索增强上下文 | 长尾库的知识 |
| CodeAgent [zhang2024codeagent] | 环境交互 | 仓库文件、测试 | 仓库导航、编辑、验证 | 通过环境交互进行仓库级编码 |
| SWE-agent [yang2024swe] | 环境交互 | Shell、编辑器、仓库、测试 | 智能体-计算机接口循环 | 通过 shell 命令解决 GitHub issue |
| AgentCoder [huang2023agentcoder] | 验证驱动 | 测试生成 | 程序员-测试者-执行者循环 | 通过生成的测试精炼代码 |
| VeriGuard [miculicich2025veriguard] | 验证驱动 | 执行、测试、验证器 | 验证器引导的工具循环 | 通过验证门控并修复代码 |
| ToolNet [liu2024toolnet] | 工作流编排 | API、工具、执行 | 学习的多工具策略路由 | 跨工作流路由工具调用 |
| MapCoder [islam2024mapcoder] | 工作流编排 | 编码智能体 | 多智能体工具支持工作流 | 协调规划、生成、调试 |
| OpenHands [wang2024openhands] | 工作流编排 | 工作区、终端、浏览器、文件、运行时 | 统一软件智能体工作区 | 通过可复用接口完成长周期任务 |
3.3.1 功能导向的工具使用
这一脉络的工作主要用工具来填补模型的编程知识缺口,尤其是 API、库、文档与外部编码实用程序 [zhang2023toolcoder, ahmed2024codeqa, zhao2025rag, li2025survey, yuan2025easytool, zou2025autotool]。例如,ToolCoder [zhang2023toolcoder] 从一个清晰的瓶颈出发:代码模型常常幻想 API、选择不合适的函数,或在训练覆盖稀疏的公共与私有库上失败。为处理这一问题,它把 API 搜索工具集成到代码生成过程中,并训练模型决定何时查询工具以及如何从检索结果中选择 API。关键贡献因此不仅是更好的语法生成,而是更好的知识获取与 API grounding。更广义上,检索导向的方法减少对参数化记忆的依赖,使代码生成更能适应长尾 API、私有库与持续演化的软件生态 [zhao2025rag, zhou2023devil]。它们在主要瓶颈是模型缺乏关于应使用哪个函数、API 或库构造的可靠知识时最为有效。因此,核心设计挑战在于查询构造、结果选择、证据压缩,以及将检索到的知识稳健地注入下游生成。这些智能体方法特别适合 API 导向生成、库迁移与私有 SDK 使用,但当任务需要跨文件理解与推理、运行时调试或仓库范围依赖分析时,仅靠检索往往不足。
3.3.2 环境交互的工具使用
与功能导向工具不同,环境交互方法把工具视为智能体在软件工程环境中行动的接口 [li2026environment, chen2026grounded, song2026envscaler, gao2026teaching]。其核心问题不再仅是获取缺失函数,而是在仓库、开发产物与执行环境上有效运作。CodeAgent [zhang2024codeagent] 表明,现实仓库级代码生成不仅是从提示中补全单个函数。模型必须定位相关文件、理解依赖、检视文档、实现修改并通过测试验证结果。为支撑这一过程,CodeAgent 集成了编程工具与智能体策略,用于在真实仓库上进行信息检索、代码符号导航、代码实现与测试交互。SWE-agent [yang2024swe] 进一步推进这一思想——形式化智能体-计算机接口,其中 shell 命令、文件编辑与测试执行成为主要交互通道。RepairAgent [bouzenia2025repairagent] 类似地为智能体装备修复专用工具,用于读取代码、搜索修复要素、应用补丁与运行测试。这些方法共同定义了环境交互工具使用的核心轨迹——尤其适合仓库级生成、issue 解决与开放式软件工程任务。
3.3.3 验证驱动的工具使用
第三条工作线主要把工具用于生成后验证与迭代式改进。验证驱动的工具使用把外部工具视为框架的确定性传感器。与功能导向和环境交互工具相比,这些方法不一定强调外部检索或广泛的仓库导航,而是把测试、执行结果、编译器错误、运行时轨迹、类型检查器、静态分析器与验证器反馈作为提升代码质量的主要信号 [miculicich2025veriguard, liu2026agents4plc, liu2026llm, jin2025reveal]。例如,AgentCoder [huang2023agentcoder] 用一个程序员智能体、一个测试设计者智能体与一个测试执行者智能体形成代码生成、测试构造、执行与精炼的闭环。在这一范式中,工具的核心角色是验证而非检索。从代码即智能体框架视角看,验证工具让智能体进展可检查:测试失败、栈轨迹、覆盖率间隙、类型错误与静态分析告警都成为更新工作记忆并引导下一行动的结构化观测。关键设计问题是如何把这些观测路由回循环 [miculicich2025veriguard]。由于原始日志对活跃上下文可能过长或过噪,框架应解析、摘要并卸载验证轨迹,同时为审计和回放保留全保真度产物。
3.3.4 工作流编排的工具使用
工作流编排的工具使用关注多种工具、角色与控制策略如何被组织为连贯的智能体工作流 [xiong2025self, shi2025flowxpert, lumer2025tool, su2025toolorchestra]。在长周期软件任务中,智能体可能需要检索证据、定位缺陷、修改文件、运行测试、检视失败、更新记忆、请求审批,并重复这一循环若干次。挑战不仅是加更多工具,而是决定每个工具何时被调用、以何种权限、在何种上下文中,以及其结果应如何更新框架状态 [liu2024toolnet]。近期智能体 SDK 与软件智能体平台明确化这一编排层——把有类型的工具模式、会话状态、工作区、护栏、交接、追踪与人审机制打包为可复用的框架组件。生命周期钩子进一步细化这一边界:使用前钩子可以验证参数、强制权限策略或阻止危险命令,使用后钩子可以净化输出、压缩日志、更新记忆或触发后续验证。MapCoder [islam2024mapcoder] 等代表性系统通过把智能体分派给示例回忆、规划、代码生成与调试来例示工作流编排——把困难的编码问题分解为协调的子问题。CodeAgent [zhang2024codeagent] 也研究工具调用应如何在仓库级工作流中被调度与结构化。这一类对长周期代码智能体尤为重要——现实软件任务在显式控制策略下需要需求分解、上下文选择、候选探索、基于执行的验证与最终修复 [liu2024toolnet, liu2024controlllm]。
**小结:**代码智能体中的工具使用已从孤立的 API 检索演化为面向行动、观察、验证与治理的完整框架机制。功能导向工具把实现选择 grounded 到外部知识;环境交互工具让智能体在仓库与执行环境上行动;验证驱动工具提供确定性反馈;工作流编排工具通过 SDK、沙盒、护栏与生命周期钩子协调这些能力。核心挑战不再是模型能否调用工具,而是框架能否让工具使用安全、可审计、并对长周期执行有用。未来代码智能体框架应支持有类型的工具模式、权限感知的调用、沙盒化执行、生命周期钩子、结果净化、上下文压缩、状态卸载与可复现轨迹。这些机制确保工具扩展智能体行动空间的同时不牺牲可靠性、安全性或可验证性。
3.4 通过”计划-执行-验证”循环的框架控制
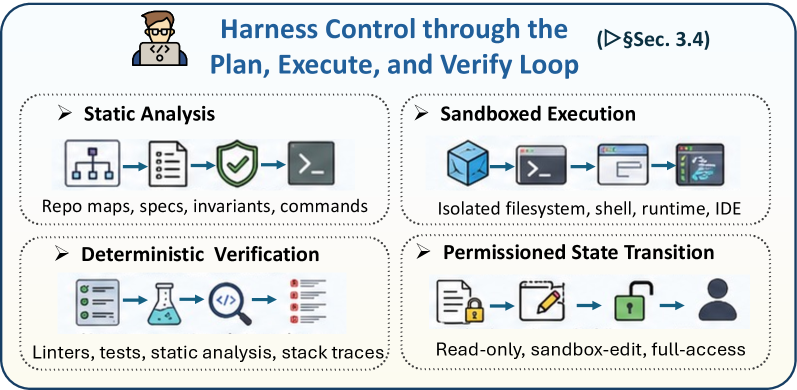
图 8:通过 PEV 循环的框架控制概览。
代码即框架的系统需要一个控制循环——把模型意图转化为有界、可观察、可修订的状态转移。本节把该循环框定为计划-执行-验证(Plan-Execute-Verify, PEV):框架先外化预期变更与其验证标准,然后在沙盒化与权限化的环境中执行该变更,最后通过确定性传感器与人审关卡验证产生的状态。这一框架把规划、执行、调试、验证与升级统一为单一框架级控制过程的组成部分。
3.4.1 从调试到框架级控制
前几个小节把规划描述为轨迹控制、把记忆描述为状态管理、把工具使用描述为受治的行动接口。反馈引导的调试把这些机制连成闭环:计划指明预期变更,记忆保留相关证据,工具执行并检查行动,验证信号决定智能体应继续、修订或停止。当代码中心智能体从单轮生成走向仓库级软件工作时,调试因此更适合理解为对可执行程序状态的控制,而不是事后修正阶段。生成的程序可能由于语法错误、运行时异常、不正确输出、不完整的边界情况处理、不安全操作或违反项目约定而失败,使得一次性生成不足够 [chen2023teaching]。近期系统通过来自编译器、运行时、测试、静态分析器、人类与辅助智能体的反馈修订代码 [shinn2023reflexion, zhong2024debug, bi2024iterative, dai2025feedbackeval]。从框架视角看,这一过程可被重新框定为计划-执行-验证(PEV)循环:智能体外化预期轨迹,在受控环境中执行有界行动,并在下一次转移前验证产生的状态。围绕智能体框架日益增长的工程生态强化了这一视角:近期精选资源把编排、工作状态、执行基质、评估框架、可观察性与治理区分为可分离的框架层——而非偶然的实现细节 [picrew2026awesomeagentharness, openaiharnessengineering2026, opencodexloop2026, langchainanatomyharness2026]。
在这一视角下,框架充当控制论调节器(cybernetic governor):一个控制层,观察智能体行动的效果并调节后续状态转移。框架不仅把错误消息转发给模型,而是通过确定性传感器观察仓库与执行环境——例如 Linter、解析器、编译器、类型检查器、单元测试、集成测试、静态分析器、模糊测试器、运行时监视器与 CI 流水线。这些传感器把编码轨迹转化为可检查的信号,包括通过/失败结果、诊断、失败轨迹、覆盖率间隙、安全告警、资源限制与策略违规。框架据此决定是否继续执行、修订补丁、请求更多上下文、把任务路由到另一模块、降低权限或上升到人审。表 7 概括了这一控制面;本小节的其余部分沿循环展开:从契约形成、经沙盒化状态转移,到确定性验证与证据 grounded 的修复。
表 7:PEV 循环框架控制的代表性方法与系统。
| 方法 | PEV 角色 | 核心机制 | 信号与关卡 |
|---|---|---|---|
| CodePlan [bairi2024codeplan] | 计划、结构性 | 依赖计划图 | 仓库链接、批评 |
| MapCoder [islam2024mapcoder] | 计划、编排 | Map-code-test 阶段 | 交接、测试、失败 |
| OpenHands [wang2025openhands] | 完整 PEV 框架 | 有状态编辑-执行工作区 | 差异、日志、测试、批准 |
| SWE-agent [yang2024swe] | 执行、CLI | 可回放的 shell 接口 | 命令、补丁、测试 |
| Daytona [daytona2026] | 执行、云沙盒 | 隔离的开发工作区 | 文件、限制、快照 |
| E2B [e2b2026] | 执行、代码-浏览器沙盒 | 云代码-浏览器沙盒 | 标准输出、限制、UI 状态 |
| Self-Debugging [chen2023teaching] | 验证、自调试 | 解释引导的修复 | 错误、测试 |
| Reflexion [shinn2023reflexion] | 验证、反思记忆 | 言语反馈记忆 | 结果、批评 |
| Debug Like a Human [zhong2024debug] | 验证、分步调试 | 运行时分步检查 | 轨迹、变量、断言 |
| Iterative Refinement [bi2024iterative] | 计划-验证反馈 | 项目上下文修复 | 编译器诊断 |
| QualityFlow [Hu2025QualityFlow] | 验证、质量门 | 质量反馈路由 | 测试、成功、停止 |
| AgentCoder [huang2023agentcoder] | 验证、多智能体修复 | 编码者-测试者-执行者循环 | 测试、失败、批评 |
| AutoSafeCoder [Nunez2024AutoSafeCoder] | 验证、安全传感器 | 静态检查、模糊测试 | 告警、轨迹、测试 |
| VeriGuard [miculicich2025veriguard] | 验证、验证生成 | 验证器守卫层 | 证明、测试、告警 |
| LiteLLM [litellm2026] | 权限网关 | 代理策略路由 | 批准、拒绝、成本日志 |
3.4.2 规划作为契约形成
规划阶段把用户请求转化为关于下一状态转移的显式契约。一个稳健的计划不仅把请求分解为实现步骤;它还识别相关文件、预期不变式、验证命令、回滚点与危险操作。这让规划成为框架产物,而不是未被观察的推理痕迹。在仓库级任务中,这种产物通过指定可读取的组件、可编辑的文件以及完成前必须满足的验证标准,约束后续行动空间 [jiang2024selfplanning, bairi2024codeplan, islam2024mapcoder]。仓库本地指令与工具协议强化了这一契约层:AGENTS.md 风格的指引、MCP 服务器注册表、有类型的工具模式、适配器与协议网关,使可用行动在执行前可检查,而非在执行中机会性地发现 [agentsmd2026, mcpservers2026, modelcontextprotocol2026, langchainmcpadapters2026, RayASO, hou2025model, li2025glue, contextforge2026]。PEV 框架也阐明了为什么规划与调试不应分离:失败的验证会更新计划,而计划决定哪些验证证据是有意义的。
3.4.3 沙盒化执行与权限化状态转移
执行阶段把计划实现为有界且可观察的状态转移。沙盒化环境是循环的操作基质:它提供隔离的文件系统、依赖状态、shell、语言运行时、浏览器或 IDE 接口与资源边界——智能体生成的行动可以在其中运行而不直接危及宿主系统 [vijayvargiya2025openagentsafety, cheng2026llm]。当代的执行基质工作最好按功能簇而非未分化的目录来阅读。编码沙盒暴露文件系统、Git 操作、shell、包管理器与代码执行后端 [daytona2026, e2b2026, alibabaopensandbox2026, judge02026, swerex2026, wang2025openhands];计算机使用基质增加浏览器、桌面、LSP 或 IDE 状态 [trycua2026, browserharness2026, e2bdesktop2026, agentinfrasandbox2026, agentscoperuntime2026];持久运行时强调 microVM 或 WASM 隔离、快照、热池、可恢复会话、基准环境与始终在线的操作上下文 [tensorlake2026, arrakis2025, capsule2026, kubernetesagentsandbox2026, sandboxedsh2026, terminalbenchenv2026, stakpakagent2026]。沙盒也提升可复现性——框架可在可比条件下回放同样的补丁、命令、种子、依赖锁文件或测试配置。若无这一稳定基质,验证信号难以解读,失败可能反映环境漂移而非程序缺陷 [wang2025openhands, feng2026longcli, anthropicinfranoise2026]。
执行还必须被权限化。多层级模型把低风险观察与高风险行动分离:只读层支持仓库浏览、检索、静态检视与日志分析;沙盒编辑层支持本地补丁、测试执行与在隔离工作区中临时安装依赖;完整访问层涵盖网络访问、凭证、部署命令、包发布、破坏性文件系统操作或 Git 历史变更。最后一层的行动应由强制的人在环路(HITL)关卡守护——因为后果可能扩展到沙盒之外。近期软件智能体系统与框架工程工作越来越通过显式工具、会话、策略、批准提示与审计日志暴露这些控制点 [sergeyuk2026human, wang2025openhands, lin2026agentic, zhou2026externalization, anthropicclaudecodeautomode2026, anthropicsandboxing2026]。网关与策略层则提供其生产对照面:模型路由、工具注册、代理层日志、集中护栏、安全自动化与可证伪的批准证据系统,把治理保持在提示之外 [litellm2026, kong2026, portkey2026, contextforge2026, agentgateway2026, openairealtimeagents2026, openaicsagentsdemo2026, tracecat2026, archestra2026, haft2026]。
3.4.4 通过确定性传感器进行验证
验证阶段通过把新状态与显式约束比较,关闭并在必要时重新打开循环。编译与静态分析反馈在完整执行之前提供低成本传感器,包括解析器诊断、类型错误、Lint 警告与安全告警 [bi2024iterative, adnan2025debugging, blyth2025static]。运行时信号暴露只在具体执行路径中出现的失败,例如异常、断言中断、无效 API 使用、资源耗尽与超时 [sun2024llm, huang2025mldebugging, zhong2024debug]。基于测试的反馈则评估观察到的行为是否满足预期规范——使用单元测试、集成测试、回归测试、模糊测试或基准专用评估器 [chen2023teaching, fakhoury2024llm, gu2024testart, shi2025from]。评估框架把这一思想从单一测试命令拓展到可重复的任务分布:它们编码评估器逻辑、仿真钩子、红队案例或 RL 风格环境,可在受控条件下比较框架变体 [promptfoo2026, deepeval2026, ragas2026, lmevaluationharness2026, langwatch2026, evalscope2026, harbor2026, tau2bench2026, nemogym2026, agentevaluation2026, inspectevals2026]。与自然语言批评相比,这些传感器是确定性的或至少足够可复现,可作控制信号。当失败证据稀疏时,人类或智能体批评仍然有用,但在受治的 PEV 循环中,它们应解读传感器输出而非取代它们 [shinn2023reflexion, ross2023programmer, wu2024autogen]。
验证还提供修复、反思与终止的证据,因此这些活动被视为验证阶段的后果,而非独立阶段。当检查失败时,同样的传感器证据可决定框架是请求模型诊断失败、检索缺失上下文、重新生成局部补丁、把任务路由给测试或安全智能体,还是放弃当前分支。自我反思机制有助于把原始诊断转化为可操作的假设,例如失败是否来自不正确的控制流、缺失的边界情况、误解的 API 或不充分的测试 [Wu2025IterPrefFP, Pan2025CodeCoR]。然而,反思只有在 grounded 到可执行证据时才可靠。AgentCoder、AutoSafeCoder 与 QualityFlow 等系统通过把智能体批评与独立执行、静态分析、模糊测试或测试质量门相结合,例示了这一原则 [huang2023agentcoder, Nunez2024AutoSafeCoder, Hu2025QualityFlow]。终止同样应由验证而非模型置信度治理:当所需检查通过时、当额外尝试不再改进状态时、当风险层级改变时,或当需要人审时,循环都可以停止。
**小结:**把迭代式调试重新表述为 PEV 循环,强调可靠性来自受治的状态转移,而不仅来自更好的修复提示。计划外化预期变更与风险假设;执行在沙盒化与权限化环境中应用变更;验证用确定性传感器决定状态是否可接受;HITL 关卡在行动空间跨越安全边界时保留问责。这一框架把静态分析、运行时错误、测试、批评、自我反思与人审统一为控制论框架的组成部分——调节智能体在可执行程序状态上的轨迹。
3.5 面向自适应框架优化的智能体式框架工程
智能体式框架工程(Agentic Harness Engineering, AHE)指明一个框架层的设计问题:如何度量并修订把语言模型转化为编码智能体的软件基质。提示工程改变指令,上下文工程改变呈现给模型的证据,而 AHE 把运行环境本身视为分析对象——包括工具模式、规划产物、记忆策略、检索策略、沙盒配置、验证传感器、权限层级、路由规则、多智能体工作流与人审关卡 [lin2026agentic, zhou2026externalization]。这一视角有用,因为代码智能体的许多观察到的失败源于缺失的仓库上下文、脆弱的工具接口、薄弱的验证器、过高的 token 成本、不当的重试策略或不匹配的权限边界——而非模型生成。
现有工作可读作三条互补线索。AutoHarness 研究代码框架的自动合成 [lou2026autoharness];Meta-Harness 把框架设计表述为面向模型可见基础设施的优化问题 [lee2026metaharness];可观察性驱动的 AHE 强调遥测丰富的诊断——定位智能体循环在何处失败以及哪个框架组件应改变 [lin2026agentic]。相关的反思式提示演化、自演化工作流与实时软件工程智能体工作支持同样的系统视角:改变围绕模型的支架可改变智能体行为而无需重训基础模型 [agrawal2025gepa, Liu2025SEW, xia2025live]。OpenAI、Anthropic 与 LangChain 的工程指引汇聚于同一实践教训:可靠的智能体需要显式的框架循环、工具契约、轨迹回放、评估套件、上下文预算与受控的执行边界 [openaiharnessengineering2026, opencodexloop2026, anthropicmanagedagents2026, anthropicmcpexecution2026, langchaindeepagentsharness2026]。
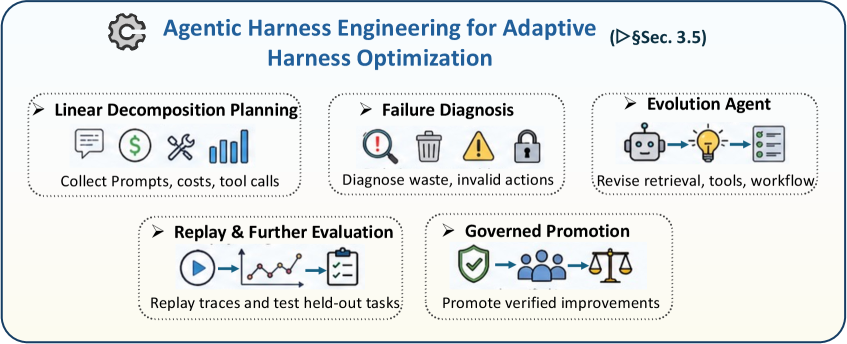
图 9:面向自适应框架优化的框架工程概览。
3.5.1 作为优化基质的深度遥测
AHE 的核心基质是深度遥测:把模型决策、框架行动、环境状态与结果连接起来的结构化轨迹。浅层日志可能只记录最终答案或通过/失败结果。深度遥测以更高细节记录决策过程:提示与检索的上下文、token 用量与成本、模型/工具延迟、工具参数、权限请求、被编辑的文件、沙盒快照、命令输出、测试结果、栈轨迹、Lint 警告、分支决策、被拒绝的替代方案、人类干预与最终任务结果。在代码中心场景中,这些轨迹特别有价值——因为程序执行已经通过日志、测试、差异与运行时行为暴露状态转移 [ding2024semcoder, armengol2025cannot, copet2025cwm]。在生产系统中,这一角色越来越由可观察性与可靠性栈承担——记录轨迹、指标、提示、模型流量、评估结果与成本信号 [langfuse2026, mlflow2026, opik2026, ragaaicatalyst2026, tensorzero2026, arizephoenix2026, openllmetry2026, helicone2026, agentops2026, latitude2026, laminar2026, openinference2026, futureagi2026]。评估、可观察性与治理系统因此提供互补的遥测通道:评估器暴露任务级回归,追踪栈暴露轨迹级原因,策略网关暴露边界违规——演化智能体可将其转化为框架修订。
遥测把框架修订从轶事式调试转化为比较式诊断。Token 成本轨迹揭示检索或反思阶段何时消耗预算却未改进验证结果。决策树轨迹显示智能体在何处反复选择无效工具、编辑无关文件或在失败策略间循环。失败轨迹聚类出常见模式,例如缺失依赖、薄弱测试、被幻想的 API、不稳定的沙盒、过宽的工具调用或过早终止。由于这些信号与具体产物挂钩,它们可以在框架版本之间被回放与比较,从而评估某次变更是否真正提升可靠性,而非仅改变表面行为 [jimenez2024swebench, feng2026longcli]。
3.5.2 演化智能体
演化智能体(Evolution Agent)是元级智能体,利用深度遥测来提议、评估并晋升对框架组件的修订。与编辑目标仓库的任务智能体不同,演化智能体编辑后续任务智能体所工作的运行条件。它的输入是轨迹语料;输出可能是修订的提示模板、检索策略、更精确的工具模式、新增的验证器、改变的权限规则、工作流拓扑调整或新的回归测试。这一角色与自演化多智能体系统密切相关——专门化的智能体检视执行日志,把失败归因到工作流组件,并更新协作结构 [Hu2025EvoMAC, zou2025latentmas]。在框架场景中,同样的思想从多智能体拓扑被推广到智能体运行时的控制面。
典型的演化智能体循环包含五个阶段。第一,它观察——从 PEV 执行中收集遥测来观察轨迹。第二,它诊断——把成本、延迟、无效行动、测试失败或权限拒绝归因到具体框架组件。第三,它提议候选修订——例如重写工具描述、改变上下文打包规则、增加 Linter、修改重试上限,或在危险命令前插入 HITL 关卡。第四,它评估——用确定性传感器与回归测试在保留任务或回放轨迹上评估修订后的框架。最后,它只晋升那些在不让先前已解决案例回归的前提下改进可靠性、成本或安全性的变更。这把 AHE 保持在与 PEV 循环相同的工程纪律中:提议的变更在被采纳前必须被执行、被验证并可审计。
表 8:智能体式框架工程的代表性方法与遥测驱动的修订目标。
| 方法 | 类别 | 遥测 | 修订目标 |
|---|---|---|---|
| AutoHarness [lou2026autoharness] | 框架合成 | 失败、夹具、断言 | 框架代码与测试 |
| Meta-Harness [lee2026metaharness] | 框架搜索 | 代码、分数、轨迹 | 提示、工具、脚本 |
| AHE [lin2026agentic] | 遥测驱动优化 | 成本、决策、延迟、失败 | 上下文、工具、验证器 |
| GEPA [agrawal2025gepa] | 反思式提示演化 | 分数、反馈、批评 | 提示与指令 |
| EvoMAC [Hu2025EvoMAC] | 工作流拓扑演化 | 交接、空闲角色、循环 | 智能体角色与图 |
| SEW [Liu2025SEW] | 自演化工作流 | 工作流分数、失败 | 阶段顺序与角色 |
| Live-SWE [xia2025live] | 在线智能体演化 | 实时 issue 轨迹 | 策略、工具、记忆 |
| GroundedTTA [chen2026grounded] | 测试时适应 | 状态-行动证据 | 适应规则 |
| RLEF [gehring2024rlef] | 执行反馈学习 | 执行奖励、失败 | 反馈奖励信号 |
| DeepEval [deepeval2026] | 评估框架 | 场景与指标轨迹 | 回归套件、关卡 |
| FeedbackEval [dai2025feedbackeval] | 修复评估基准 | 反馈-任务分数 | 失败分类法与评估集 |
| Langfuse [langfuse2026] | 可观察性平台 | 跨度、成本、延迟、评估 | 仪表板与回放 |
| OpenLLMetry [openllmetry2026] | 轨迹仪表 | OpenTelemetry 跨度、调用 | 框架仪表 |
| Promptfoo [promptfoo2026] | 评估框架 | 分数、回归、失败 | 评估关卡与红队测试 |
| LiteLLM [litellm2026] | 网关治理 | 路由、预算、失败 | 预算、回退、层级 |
3.5.3 受治的框架变更
AHE 不应与无约束的自我修改混为一谈。由于演化智能体改变控制后续任务智能体的框架,其行动比普通代码修复需要更强的治理。候选框架变更应在沙盒中评估、与固定的回归套件比较,并附带可审计的理由。改变权限边界、网络访问、凭证处理、部署行为或人审要求的变更,应在激活前要求 HITL 批准。从这一意义上说,演化智能体本身受 PEV 循环约束:它规划一次框架变更、在隔离评估环境中执行、通过遥测与回归测试验证结果,并把高风险变更上升给人类。
**小结:**智能体式框架工程把代码即框架的视角从操作智能体扩展到分析操作智能体的基础设施。深度遥测为跨提示、工具、记忆、沙盒、验证器、权限与工作流的失败定位提供证据。演化智能体利用这些证据提议并评估框架变更,把框架设计变成由验证与人类批准治理的迭代式、可度量工程过程。
4 框架扩展:基于代码的多智能体编排
当 AI 系统处理日益复杂的问题——从函数级代码合成到仓库级系统工程——单智能体的根本局限显现:(1) 上下文窗口约束使单一智能体无法把整个代码库、长交互历史与执行轨迹同时保留在工作记忆中;(2) 专门化要求使得用一个通用智能体同时进行规划、合成、测试、审查与调试效率低下;(3) 缺乏独立的协调与验证通道,使智能体无法在长周期执行中可靠地检测并纠正自身错误。多智能体系统引入一个有力的原则:一旦这些职责被分布到专门化角色,智能体框架本身就变得更模块化、更可检查、更可适应。ChatDev [Qian2023ChatDev]、MetaGPT [Hong2023MetaGPT] 与 AgentCoder [huang2023agentcoder] 等早期系统通过把软件开发职责分给不同智能体(如架构师、程序员、测试员、审阅者与执行者)展示了这一转变。借助结构化通信协议与共享代码产物协调,这些角色专门化的智能体把代码从单纯的输出目标转变为整体框架据以规划、行动、验证并自我改进的共享基质。
本节系统综述用 MAS 扩展编码框架的快速增长方向,并提出关于为 AI 智能体构建共享代码中心框架基质的新立场。
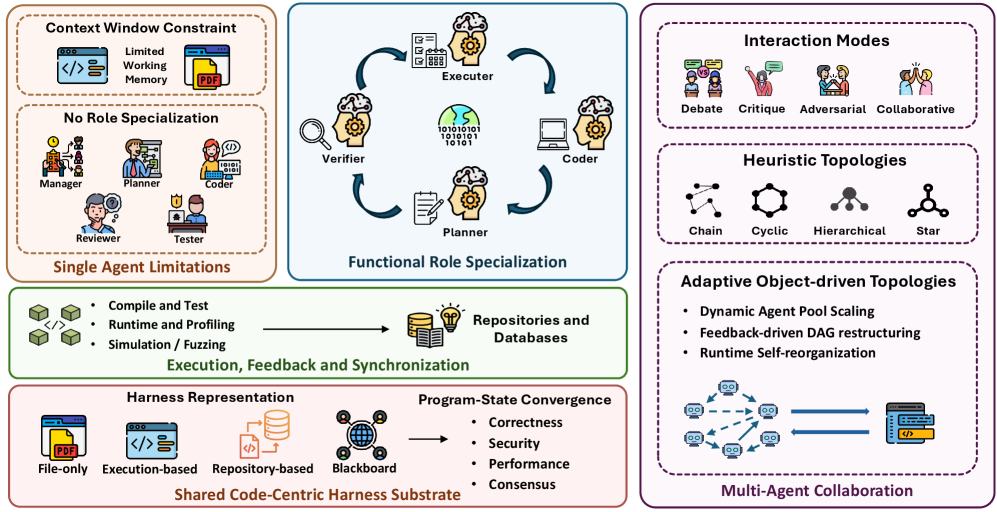
图 10:通过基于代码的多智能体编排扩展智能体框架的概览。该图说明了角色专门化的智能体、共享代码中心基质、执行反馈与自适应协作拓扑如何应对单智能体在上下文、专门化与自我纠正方面的局限。
图 11:为多智能体编排扩展代码框架的路线图,按工作流协作、共享仓库状态、执行验证与自适应协调组织。
4.1 通过多智能体协作改进编码支持
多智能体系统最直接的贡献,是通过把框架分解为专门化但协调的组件来改进编码支持。这些系统不再把规划、合成、执行与验证集成到单一智能体循环中,而是把责任分布到通过共享代码产物与反馈信号交互的角色之间。这种分工使整体框架更能处理复杂软件任务,同时让其内部工作流更可检查、更可控。在实践中,这种改进通过三个紧密相关的设计维度实现:角色如何被专门化、智能体如何在共享程序产物上交互,以及工作流拓扑如何组织它们的协作。
表 9:按角色专门化与交互结构组织的代表性 MAS 协作设计。
| 系统 | 框架基质 | 智能体角色 | 交互模式 | 拓扑 |
|---|---|---|---|---|
| Self-Collaboration [Dong2024SelfCollaboration] | 黑板、隐式 | 计划、合成、验证(仿真) | 批评-修复 | 预定义循环 |
| CodePori [Rasheed2024Codepori] | 隐式 | 计划、合成、验证 | 协作合成、批评-修复 | 预定义链、循环 |
| MAGIS [Tao2024Magis] | 仓库、演化记忆 | 计划、理解、合成、验证 | 批评-修复、辩论、委派 | 层级、循环、动态池 |
| HyperAgent [Phan2024HyperAgent] | 仓库、执行 | 计划、理解、合成、执行 | 批评-修复 | 预定义层级、循环 |
| PairCoder [Zhang2024PairProgramming] | 执行 | 计划-理解、合成-执行 | 协作合成、批评-修复 | 预定义循环加条件分支 |
| FlowGen [Lin2025Soen101] | 执行、隐式 | 计划、理解、合成、验证 | 批评-修复、辩论 | 预定义链、循环(Scrum) |
| Trae Agent [gao2025traeagent] | 仓库、执行 | 生成、剪枝、选择 | 协作合成、搜索(选择) | 预定义搜索流水线 |
| BOAD [xu2025boad] | 仓库、执行 | 编排、定位、编辑、验证 | 委派、自适应选择 | 自适应层级 |
| FlowReasoner [gao2025flowreasoner] | 执行、隐式 | 元设计、求解 | 运行时工作流生成 | 目标驱动自适应 |
| ChatDev [Qian2023ChatDev] | 隐式、边缘执行 | 计划、合成、验证、执行 | 批评-修复、辩论 | 预定义链(瀑布) |
| MetaGPT [Hong2023MetaGPT] | 隐式、部分黑板 | 计划 \times 3、合成、验证 | 批评-修复、发布-订阅调度 | 预定义链(瀑布) |
| GameGPT [chen2023gamegpt] | 黑板(双协作) | 计划、合成、验证 | 批评-修复、协作 | 预定义 |
4.1.1 功能角色专门化与人引导的规划
在人类软件开发中,不同角色专门于开发过程的不同方面。许多 MAS 自然地通过把不同的功能角色分给不同智能体来镜像这种分工。这种专门化让每个智能体聚焦于共享代码框架的特定切片,利用其独特的能力与视角贡献于整体任务。下面阐述综述文献中识别出的最常见功能角色——注意许多系统实现多个角色且它们之间的界线可能流动。
程序合成智能体
程序合成智能体负责生成或转换代码。它们消费规范、计划或反馈信号,并产出或修订代码产物。这是综述系统中最常见的角色。代表实例包括 Self-Collaboration [Dong2024SelfCollaboration] 中的 Coder、AgentCoder [huang2023agentcoder] 中的 Programmer、MetaGPT [Hong2023MetaGPT] 中的 Engineer、ChatDev [Qian2023ChatDev] 中的 Developer 以及 MAGE [Zhao2024MAGE] 中的 RTL Generation Agent。
程序理解智能体
程序理解智能体分析现有代码或规范以产出更高层的表示。它们负责解释代码意思是什么,而非做什么。这一类别包括 MAGIS [Tao2024Magis] 中的 Repository Custodian、HyperAgent [Phan2024HyperAgent] 中的 Navigator、Lingma SWE-GPT [Ma2024Lingma] 中的 RepoUer 以及 CleanAgent [Qi2024CleanAgent] 中的 Column-type Annotator。
验证智能体
验证智能体评估代码质量,通常通过生成测试用例、运行静态分析或仿真执行。AgentCoder [huang2023agentcoder] 中的 Test Designer 独立于代码生成测试用例以避免循环推理——这一设计原则针对模式坍缩问题:智能体的偏置测试通过自己的有缺陷代码。QualityFlow [Hu2025QualityFlow] 中的 Test Quality Checker 在元层级处理这一问题——在合成测试被用作反馈前过滤它们。AutoSafeCoder [Nunez2024AutoSafeCoder] 中的 Static Analyzer 与 Fuzzing Agent 通过静态 CWE 分析与动态崩溃检测分别提供安全导向的验证。CANDOR [Xu2025Hallucination] 中的 Panelists 独立地针对自然语言规范而非代码本身审计 oracle 正确性,有意避免被有缺陷的实现污染。
执行智能体
执行智能体直接与程序运行时接口。关键的是,AgentCoder [huang2023agentcoder] 中的 Test Executor 是确定性的 Python 脚本(而非 LLM),这干净地把推理与执行分离,并把反馈信号 grounded 到客观程序行为。HyperAgent [Phan2024HyperAgent] 中的 Executor 通过交互式 bash shell 运行单元与集成测试。MAGE [Zhao2024MAGE] 中的 Judge Agent 与 RTL 仿真工具接口,产生每时钟边缘的波形快照。
规划智能体
规划智能体把整体软件开发任务分解为子任务并分配给合成智能体。MetaGPT [Hong2023MetaGPT] 中的 Architect 与 Project Manager、MAGIS [Tao2024Magis] 中的 Manager、FlowGen [Lin2025Soen101] 中的 Scrum Master、SoA [Ishibashi2024SelfOrganized] 中的 Mother agents 都执行任务分解。SoA [Ishibashi2024SelfOrganized] 中的 Mother agents 尤为值得注意:它们在运行时根据每个子函数的推断复杂度动态生成 Child agents——这使规划与智能体初始化相互依赖。
EvoMAC [Hu2025EvoMAC] 的独特之处在于引入了两个其他综述系统中没有的新元角色:Gradient Agent(读取执行日志以识别哪些智能体导致失败)与 Updating Agent(相应地修订智能体提示并重构工作流 DAG)。这些角色在 MAS 本身的层级运作,而非程序的层级——使系统能根据执行反馈适应自身结构。
4.1.2 grounded 于共享程序状态的多样交互模式
与一般 MAS 中智能体交互主要是消息传递不同,代码中心交互的特征是产物中介通信:智能体观察并修改共享代码产物,它们的交互 grounded 到这些产物及其执行结果暴露的客观状态。这些协调通道比仅源代码更广:智能体通过 API、文件、差异、测试、日志、模式、黑板与显式工作流状态进行通信。在大多数系统中,这些通道是人工设计框架的一部分,而智能体动态写入或修改在其中流通的产物。我们识别出四种交互模式。
协作合成
协作合成发生在两个智能体共同构造一个程序组件时,类似于结对编程 [zou2026recursivemas]。PairCoder [Zhang2024PairProgramming] 中的 Navigator-Driver 配对是最直接的实例:Navigator 生成并选择解题计划,而 Driver 实现它们,信息流双向。CodePori [Rasheed2024Codepori] 在 Dev_01 与 Dev_02 之间实现协作合成——他们在三轮中交换代码草稿。这一模式在综述系统中相对少见——大多数系统更偏好顺序交接而非真正的共同构造。
批评与修复
批评与修复是综述文献中占主导地位的交互模式。一个验证或评估智能体检查代码产物并产生结构化反馈;一个合成智能体随后据此修订产物。这一模式以某种形式出现在几乎每个综述系统中。其关键设计决策是:(a) 批评是 LLM 仿真的还是执行 grounded 的(Self-Collaboration [Dong2024SelfCollaboration] 使用仿真的 LLM 测试者,而 AgentCoder [huang2023agentcoder] 使用真实 Python 执行器);(b) 反馈信号的丰富度(从 SEW [Liu2025SEW] 中的二元通过/失败,到 EvoMAC [Hu2025EvoMAC] 中枚举满足需求、函数错误与未满足需求的结构化执行日志);(c) 回退前允许的修复迭代次数。
对抗式验证
对抗式验证是一种更主动的验证形式——一个智能体试图通过对抗输入破坏代码,而非被动审查它。AutoSafeCoder [Nunez2024AutoSafeCoder] 通过其 Fuzzing Agent 实现这一点:利用类型感知变异生成会触发崩溃的输入种子并执行代码以产生崩溃轨迹。这一模式具有与批评-修复根本不同的特性:模糊测试者不解释哪里错了,而是展示一个具体的执行失败——一个编码智能体必须处理的反例。MAGE [Zhao2024MAGE] 类似地把仿真不匹配作为对抗信号:Debug Agent 接收第一次时钟边缘失败前后的精确波形窗口,从而进行有针对的修复。
推理辩论
推理辩论涉及智能体对决策的正确性或规范的解释进行论辩,然后达成共识。ChatDev [Qian2023ChatDev] 引入通信式去幻觉——助手智能体在承诺响应前反转角色提出澄清问题。FlowGen [Lin2025Soen101] 中的 Scrum 冲刺会议在共享上下文缓冲区周围支持无序多智能体讨论,然后由 Scrum Master 综合决策。CANDOR [Xu2025Hallucination] 实现了最结构化的辩论机制:三位独立 Panelists 评估 oracle 正确性,Curator 通过多数投票聚合他们的裁决。MAGIS [Tao2024Magis] 中的启动会议涉及 Manager 与所有 Developer agents 间的循环发言——协商任务依赖并防止冲突。
4.1.3 用于智能体协调的优化工作流拓扑
智能体交互的拓扑——谁与谁通信、按什么顺序、多少次——是面向代码生成 MAS 中最具决定性的设计决策之一。我们沿两条主轴组织拓扑。
预定义启发式拓扑
大多数综述系统使用镜像既定软件开发生命周期(SDLC)模型的拓扑。这些拓扑在设计时固定,不会根据任务复杂度或系统性能改变。
链式(瀑布)拓扑以严格线性顺序排列智能体,产物从规划单向流向合成,再流向验证。ChatDev [Qian2023ChatDev] 与 MetaGPT [Hong2023MetaGPT] 是典型例子——显式建模瀑布 SDLC:设计 \rightarrow 编码 \rightarrow 测试。FlowGen [Lin2025Soen101] 把三个 SDLC 模型实例化为不同拓扑:FlowWater(严格瀑布链)、FlowTDD(需求 \rightarrow 设计 \rightarrow 测试 \rightarrow 实现 \rightarrow 修复,一个测试驱动的重排)与 FlowScrum(循环迭代冲刺)。该论文在直接比较不同 SDLC 镜像拓扑对代码质量的影响方面独树一帜。L2MAC [Holt2023L2MAC] 也遵循链式拓扑但有一个新颖的转折:指令计划中的每一步都由全新上下文的智能体执行,使链变为只共享外部文件存储的独立 LLM 调用序列。
循环式(敏捷/迭代)拓扑引入反向边,允许代码根据验证反馈被修订。AgentCoder [huang2023agentcoder] 实现程序员 \rightarrow 测试执行者 \rightarrow(若失败)\rightarrow 程序员循环,限定 5 次迭代。Self-Collaboration [Dong2024SelfCollaboration] 在其瀑布链中嵌入编码者 \leftrightarrow 测试者反向边,最多 4 次迭代。PairCoder [Zhang2024PairProgramming] 通过多计划探索增强循环模式:预先通过 k-means++ 聚类生成 n 个解题计划池以求多样,并在通过基于历史的循环分析检测到死胡同时切换到下一候选计划。MAGE [Zhao2024MAGE] 把线性初始化链与循环 debug-judge 循环组合,并引入高温度候选采样以同时探索多个程序变体。
层级拓扑把一个或多个经理智能体置于工人智能体池之上,支撑分解-委派模式。MAGIS [Tao2024Magis] 有一个 Manager,在运行时为每个候选文件动态实例化一个 Developer——每个 Developer 编辑被分配的文件并向 manager-review 层汇报。HyperAgent [Phan2024HyperAgent] 把一个规划者置于多个仓库导航与编辑工人之上——把自顶向下的分解与自底向上的仓库证据结合。SoA [Ishibashi2024SelfOrganized] 把这一层级进一步推进——允许 Mother agents 根据推断的子任务复杂度递归生成 Child agents。这些系统把框架编排本身视为资源分配问题。
星形拓扑围绕一个集线器智能体协调多个并行工人。CANDOR [Xu2025Hallucination] 第 3 阶段的小组是例证:Requirement Engineer 扇出到三个独立的 Panelist+Interpreter 流水线,Curator 聚合它们的输出。MetaGPT [Hong2023MetaGPT] 的发布-订阅消息池形成了事实上的星形拓扑——共享池充当集线器。
目标驱动与自适应拓扑
一类较小但增长迅速的系统把拓扑本身视为可朝向代码质量信号优化的设计变量。FlowReasoner [gao2025flowreasoner] 与 BOAD [xu2025boad] 等近期系统通过把多智能体组织本身视为可按任务生成、搜索或优化的自适应对象,进一步强化这一趋势。
动态智能体池扩展是最简单的自适应形式:智能体数量随任务复杂度扩展,但拓扑类型固定。SoA [Ishibashi2024SelfOrganized] 通过 Mother 与 Child 智能体的层级树实现这一点——Mother 在运行时决定要分解多少子函数并生成相应的 Child。关键洞察是每个智能体的上下文窗口保持有界,复杂度由增长智能体池而非扩大单个上下文窗口来处理。MAGIS [Tao2024Magis] 类似地基于仓库分析期间识别的候选文件数量动态实例化 Developer。BOAD [xu2025boad] 把这一思路从动态扩展扩展到层级发现:不再人工固定专门化子智能体结构,而是把面向定位、编辑与验证的子智能体选择形式化为多臂赌博机优化问题——表明自动发现的层级化团队可以胜过手工设计的团队。
反馈驱动的 DAG 重构最好由 EvoMAC [Hu2025EvoMAC] 代表。其工作流是 DAG——节点对应智能体,边定义信息流。每次迭代后,Gradient Agent 读取执行日志把失败归因到智能体,Updating Agent 相应地修改提示与图结构。这是综述中唯一一个根据执行反馈结构性修改框架拓扑的系统。
运行时自重组是 SEW [Liu2025SEW] 的方法:系统使用 Direct Evolution(DE)与 Hyper Evolution(HE)算子,在结构化格式(BPMN、CoRE、Python、YAML)的 LLM 生成工作流描述上生成并变异完整工作流规范。SEW [Liu2025SEW] 优化工作流结构(包括智能体调用序列、路由逻辑与反馈路径)而非智能体参数。它发现的两种典型拓扑(线性链与反馈循环)从优化中涌现,而非手工设计。FlowReasoner [gao2025flowreasoner] 把这一自适应视角进一步推进——训练一个查询级元智能体,在外部执行反馈下为每个输入问题生成定制的多智能体系统——使拓扑选择本身成为审慎推理过程的一部分,而非固定的系统设计。
4.2 执行反馈与共享框架同步
本节讨论一组智能体如何利用代码的可执行性,以及它们如何对程序状态保持一致的共享视图。这一维度是代码中心 MAS 的决定性维度:共享框架独特地可执行,并产生客观的 oracle 信号。我们处理两个子问题:使用何种类型的执行反馈,以及共享状态如何在智能体间同步。
表 10:代表性的 MAS 执行反馈与收敛设计。
| 系统 | 框架基质 | 拓扑 | 执行反馈 | 收敛 |
|---|---|---|---|---|
| 预定义拓扑 | ||||
| AgentCoder [huang2023agentcoder] | 执行 | 循环 | 测试通过/失败 | 正确性(测试门控) |
| MAGE [Zhao2024MAGE] | 执行(波形) | 链-循环 | 检查点波形 | 基于分数的正确性 |
| MapCoder [islam2024mapcoder] | 执行、隐式 | 循环 | 测试通过/失败 | 正确性 |
| AutoSafeCoder [Nunez2024AutoSafeCoder] | 执行(静态、模糊) | 循环 | CWE 告警、崩溃 | 安全收敛 |
| QualityFlow [Hu2025QualityFlow] | 执行(真实、想象) | 门控循环 | 通过/失败、想象执行 | 正确性(质量门控) |
| CodeCoR [Pan2025CodeCoR] | 执行、隐式 | 循环 | 语法、测试通过/失败 | 基于分数的软正确性 |
| MARCO [Rahman2025MACRO] | 执行(性能) | 2 节点循环 | 时间、内存、FLOPS | 性能、正确性 |
| 自适应拓扑 | ||||
| SoA [Ishibashi2024SelfOrganized] | 执行、隐式间隙 | 层级树 | 测试通过/失败 | 正确性(隐式回退) |
| SEW [Liu2025SEW] | 隐式 | 演化 | 测试通过/失败 | 隐式 |
| EvoMAC [Hu2025EvoMAC] | 执行 | 文本 DAG | 编译器、执行日志 | 正确性(固定迭代) |
| FlowReasoner [gao2025flowreasoner] | 执行、隐式 | 查询工作流 | 执行反馈 | 目标驱动自适应 |
| Trae Agent [gao2025traeagent] | 仓库、执行 | 搜索流水线 | 测试、剪枝信号 | 基于分数/选择 |
4.2.1 执行反馈集成
编译器与语法反馈
编译器与语法反馈在运行时之前捕获结构错误,被许多系统使用。ChatDev [Qian2023ChatDev] 把测试阶段的编译器错误反馈给程序员,尽管仅作为单一阶段内的一次性更正。L2MAC [Holt2023L2MAC] 在每次文件写入后通过其评估器模块 E(D) 运行语法检查,把它们视为阻止指令流水线推进的阻塞条件。
测试通过/失败信号
测试通过/失败信号是最常用的执行反馈类型。AgentCoder [huang2023agentcoder] 把整个循环聚焦于独立生成的测试用例是否通过;迭代在完全通过或 5 次迭代预算时终止。QualityFlow [Hu2025QualityFlow] 引入了一个值得注意的变体:Imagined Execution——LLM 逐步仿真 Python 解释器并预测测试结果而无需实际运行代码,在 MBPP 上达到 98%+ 的精度与召回,同时避免可见测试用例的标签泄漏。Self-Collaboration [Dong2024SelfCollaboration] 中仿真 LLM 测试者与其真实编译器消融的近似性能引出一个发人深省的实证问题:何时实际执行是必要的,何时执行的语言学仿真就足够?
模糊测试崩溃轨迹
模糊测试崩溃轨迹代表了一种质量上不同的反馈:不是通过/失败结果,而是一个具体的失败输入。AutoSafeCoder [Nunez2024AutoSafeCoder] 用类型感知变异生成会触发崩溃的输入种子,并把崩溃输入加上退出码传递给 Coding Agent。这种对抗性反馈比一般失败信号更具信息——它把缺陷定位到一个特定输入类别。
静态分析警告
静态分析警告提供关于代码结构与安全属性的反馈而无需执行。AutoSafeCoder [Nunez2024AutoSafeCoder] 针对 MITRE 漏洞数据库使用 CWE 映射的静态分析,使 Static Analyzer Agent 能针对特定漏洞类提出补救策略。
性能剖析结果
性能剖析结果被 MACRO [Rahman2025MACRO] 独特地利用——它把代码优化视为主要任务而非正确性。Performance Evaluator Agent 测量执行时间、内存使用与 FLOPS,MACRO [Rahman2025MACRO] 独特地用实时网络搜索增强这一点——从研究文献中检索相关优化技术。
细粒度仿真反馈
MAGE [Zhao2024MAGE] 的独特贡献是综述文献中最细粒度的执行反馈。状态检查点机制不是仅报告测试台是否通过或失败,而是记录每个时钟边缘的信号值,并向 Debug Agent 提供围绕第一个失败时钟周期的波形窗口。这使得能在子测试粒度进行有针对的修复。
4.2.2 共享框架同步
顺序交接是最常见的同步机制:每个智能体接收其前驱的输出,并把自身输出传递给后继。程序状态仅以流水线中最新产物的形式存在。这对简单线性流水线是足够的,但在多智能体场景中会造成不可见的状态发散——其中多个智能体并行或迭代地修改代码库。这也是代码中介协调的局限变得清晰的地方。即便智能体共享可执行产物,框架仍施加信息论约束:通道有有限带宽,摘要引入压缩损失,日志变得嘈杂,缓存视图变陈旧,并行分支引起关于权威与一致性的未解决问题。代码提供更丰富的协调基质,但并不消除这些分布式系统约束。
共享黑板
共享黑板提供所有智能体可读取并更新的全局可访问程序状态。L2MAC [Holt2023L2MAC] 最干净地实现了这一点:文件存储 D 是一个外部、持久结构,从不被覆盖而是被扩展与修订。Control Unit 管理所有读写——确保每次智能体调用接收一个精确控制的上下文窗口。MAGIS [Tao2024Magis] 的仓库演化记忆 M 是一个持久键值存储——把文件版本映射到 LLM 生成的摘要,通过专门的黑板增量更新以支撑仓库级推理。Self-Collaboration [Dong2024SelfCollaboration] 是最早显式命名并调用黑板架构的系统之一,确立了一个所有三个角色都从中读写的共享记忆。
并行分支与合并
并行分支与合并出现在多个智能体同时修改独立组件、其变更在后续阶段集成时。MAGIS [Tao2024Magis] 为每个候选文件实例化一个 Developer——每个独立修改其分配的文件,所有变更被合并到最终仓库差异中。HyperAgent [Phan2024HyperAgent] 通过 Redis 队列并行运行多个 Navigator 与 Editor 实例,结果在 Planner 层级合并。
结构化上下文调度
结构化上下文调度是对每个智能体看到什么以及何时看到的显式管理。它是 L2MAC [Holt2023L2MAC] 的主要创新。Control Unit 在指令步骤之间重置上下文窗口,为每次新调用提供前期进度的有针对摘要 (M_{rs}) 而非完整对话历史。当上下文窗口接近容量时,Control Unit 把部分结果存储到 D 并用压缩视图重新初始化,显式指示 LLM 在剩余上下文余量下读取或跳过哪些文件。这一机制不通过扩大窗口而通过仔细控制其内容来解决上下文窗口问题。MetaGPT [Hong2023MetaGPT] 通过发布-订阅消息池实现一种轻量的上下文调度——每个智能体只订阅与其角色相关的文档类型,接收共享状态的过滤视图。
层级化记忆
层级化记忆把短期工作上下文与较长期累积的知识结合。ChatDev [Qian2023ChatDev] 明确分离短期记忆(阶段内的完整对话)与长期记忆(跨阶段携带的提取解)。Cogito [Li2025Cogito] 实现层级化记忆,借鉴神经生物学架构:短期记忆用于即时任务状态、长期知识库用于累积专业知识、增长单元用于随时间改善的演化抽象。HyperAgent [Phan2024HyperAgent] 使用轻量级 LLaMA-3.1-8B 摘要器在把执行日志存储到层级化记忆前压缩它们——防止上下文膨胀。
智能体池扩展
智能体池扩展正交地处理上下文管理问题:不是管理单一智能体看到什么,而是把上下文负载分布到更多智能体。SoA [Ishibashi2024SelfOrganized] 是典型例子:通过随任务复杂度增长而生成更多智能体,每个智能体的上下文保持有界。这是对框架状态问题的结构性解决方案:不构建所有智能体都能查询的共享表示,而是把任务状态划分到智能体之间,每个持有有界切片。其局限在于全局一致性被牺牲——智能体不能对完整程序推理,只能对其分配的子函数推理。
其他
QualityFlow [Hu2025QualityFlow] 的回滚机制代表一种同步模式:初始代码产物从不被覆盖,使系统能在调试轨迹质量下降时回滚到先前的共享框架状态。这是综述系统中唯一一个显式管理状态历史而非始终向前推进的工作。
4.3 立场:共享代码中心的框架基质
我们为下一代多智能体智能提出一个新立场:共享代码中心的框架基质。这一立场由文献中识别出的中心缺口推动:缺乏智能体可以跨迭代查询并更新的共享代码状态的正式、持久表示。我们论证构建这样的框架基质既可行又对实现稳健、可扩展的多智能体智能必要。
表 11:以共享程序状态表示与同步为中心的代表性 MAS 设计。
| 系统 | 框架基质 | 智能体角色 | 执行反馈 | 收敛/同步 |
|---|---|---|---|---|
| L2MAC [Holt2023L2MAC] | 黑板、仓库、执行 | 计划、合成、验证(评估器) | 语法、测试通过/失败 | 每指令步骤的正确性 |
| Cogito [Li2025Cogito] | 黑板(3 层记忆) | 神经生物学模型 | NA | 层级化记忆同步 |
| CleanAgent [Qi2024CleanAgent] | 执行(弱)、隐式 | 计划、理解、合成、执行 | 运行时错误 | 通过执行成功实现正确性 |
| Lingma SWE-GPT [Ma2024Lingma] | 仓库、执行 | 理解、合成-验证 | 语法、git apply、测试 | 固定限度的隐式收敛 |
| SyncMind [Guo2025SyncMind] | 仓库、执行(形式化 S_{k}/B_{k}) | 合成-理解、oracle 理解 | 测试通过/失败、运行时错误 | 正确性、资源约束同步 |
| BOAD [xu2025boad] | 仓库、执行 | 带专门化子智能体的 Orchestrator | 测试通过/失败、验证奖励 | 层级发现、协调 |
| CANDOR [Xu2025Hallucination] | 执行(Java、JaCoCo) | 计划、合成、验证、理解、辩论 | 编译器、覆盖率、测试 | 正确性、覆盖率、共识 |
4.3.1 共享框架表示
任何 MAS 的基础问题是:这些智能体所栖居的基质是什么?在代码即智能体框架中,自然的答案是共享程序环境——智能体共同作用并随智能体产出、修订与评估代码而演化的产物、执行上下文与质量信号的集合。我们称之为共享框架基质,并区分现有系统据以表示它的四个形式化层级。
隐式 / 仅文件表示
最常见也最不形式化的类别把共享框架视为简单的当前代码文件或文件集。智能体接收最新代码产物作为输入上下文的一部分,并产出修改或评估过的版本。没有持久、可查询的表示:共享状态在每次智能体调用时从对话历史中隐式重构。这一类别包含许多基础系统:ChatDev [Qian2023ChatDev]、MetaGPT [Hong2023MetaGPT]、FlowGen [Lin2025Soen101]、MapCoder [islam2024mapcoder]、CodeCoR [Pan2025CodeCoR]、SEW [Liu2025SEW] 与 CodePori [Rasheed2024Codepori]。虽然这一表示实现起来简单,但带有根本局限:智能体除了通过其最新上下文窗口的窄镜头之外,无法对共享基质推理。状态发散 [Guo2025SyncMind]——智能体关于代码状态的内部信念与真实状态分离——对系统不可见,无法被检测或纠正。
基于仓库的表示
一类更丰富的系统把共享框架表示为可导航的仓库:具有目录结构、文件间依赖图、调用层次与版本历史的文件系统。这一表示支持智能体推理:代码库中哪里需要变更、哪些其他组件依赖于变更的函数,以及代码库随时间如何演化。MAGIS [Tao2024Magis] 引入仓库演化记忆,缓存文件级摘要并通过 git diff 在文件随 issue 解决回合改变时增量更新。HyperAgent [Phan2024HyperAgent] 为智能体提供仓库导航工具(get_tree_structure、go_to_definition、code_search、get_all_references),把仓库视为结构化知识库。Lingma SWE-GPT [Ma2024Lingma] 通过抽象语法树(AST)骨架压缩仓库视图,保留函数签名与类定义以支持高效导航。SyncMind [Guo2025SyncMind] 是唯一形式化定义仓库基质为真实状态 S_{k} 并测量 S_{k} 与智能体信念态 B_{k} 之间发散的工作。
基于执行的表示
基于执行的表示是代码生成最具特色的类别。它在一般 MAS 中没有直接对应——通过执行行为来表示共享基质。状态不是代码看起来如何,而是代码做什么:它是否编译、通过哪些测试、模糊测试者发现什么漏洞、运行多快、运行时行为是否匹配规范。这一基于执行的表示提供客观 oracle 信号——一个不受影响纯语言学智能体评估的幻觉或偏见的真实基线。利用这一表示的系统包括 AgentCoder [huang2023agentcoder]、AutoSafeCoder [Nunez2024AutoSafeCoder]、QualityFlow [Hu2025QualityFlow]、MACRO [Rahman2025MACRO]、EvoMAC [Hu2025EvoMAC]、CANDOR [Xu2025Hallucination] 与 MAGE [Zhao2024MAGE]。值得注意的是,MAGE [Zhao2024MAGE] 通过状态检查点波形快照,实现文献中最细粒度的执行反馈——在时钟边缘粒度上运作。
黑板 / 共享状态表示
第四类引入显式的、全局可访问的数据结构,所有智能体都能读取并写入(类似于 AI 中的经典黑板架构 [erman1980hearsay])。这一共享状态是文献中对正式框架基质最接近的近似:它跨智能体调用持续存在、可被查询与更新,并向所有智能体提供程序状态的一致视图。Self-Collaboration [Dong2024SelfCollaboration] 是最早显式调用黑板隐喻的系统之一——确立了所有三个角色(Analyst、Coder、Tester)都从中读写的共享记忆。L2MAC [Holt2023L2MAC] 实现了文献中最有原则的黑板:一个有语义意义路径的持久文件存储 D,通过显式管理每次智能体调用看到哪个状态切片的 Control Unit 访问。GameGPT [chen2023gamegpt] 使用共享上下文缓冲区在多轮游戏开发中减少冗余信息重传。Cogito [Li2025Cogito] 借鉴神经生物学架构实现三层记忆:短期工作状态、长期知识库与用于演化抽象的增长单元,作为结构化框架表示。
核心缺口
这四个类别在系统间的分布揭示了一个显著模式:大多数文献位于隐式/仅文件类别——缺乏共享框架基质的任何形式化模型。这是激发代码即智能体框架表述的核心缺口。程序作为多智能体领域中独特地可执行的产物,产生客观的、非语言学的信号,原则上可以锚定一个正式的共享基质。然而,大多数系统在架构层级未能利用这一属性,而是依赖智能体仅通过自然语言对代码质量推理。
4.3.2 框架状态收敛
收敛决定多智能体编码框架何时应停止迭代并接受当前程序状态为满意结果。在许多现有 MAS 中,收敛仍隐式定义——通过智能体间共识或外部迭代预算。然而,代码即智能体框架有一个独特优势:由于共享基质可执行,收敛可以 grounded 到客观行为信号上,而不仅仅是对话一致。我们识别六种收敛模式,从广泛使用的测试门控与隐式收敛,到较少见的安全、性能与共识标准。
正确性收敛
正确性收敛(测试门控)是最有原则也最广泛使用的客观标准:当所有测试用例通过时系统成功终止。AgentCoder [huang2023agentcoder]、L2MAC [Holt2023L2MAC]、SyncMind [Guo2025SyncMind] 与 CANDOR [Xu2025Hallucination] 实现测试门控收敛。PairCoder [Zhang2024PairProgramming] 用死胡同检测增强这一点:若同一有缺陷代码或反馈出现在迭代历史中,系统切换到下一候选计划而非循环。FlowGen [Lin2025Soen101] 使用测试门控收敛但基于 LLM 生成的测试而非真实测试——引入潜在质量隐患:系统可以收敛到通过其自身偏置测试但在外部评估中失败的代码。
安全收敛
安全收敛由 AutoSafeCoder [Nunez2024AutoSafeCoder] 独特地实现:当静态分析未标记任何 CWE 漏洞且模糊测试者未引发崩溃时系统成功终止。这种多标准收敛是基于执行的框架表述的有力论据——两个收敛标准都 grounded 到客观程序行为,而非智能体意见。
性能收敛
性能收敛是 MACRO [Rahman2025MACRO] 的焦点:优化循环在用户定义的运行时与内存阈值被满足时终止,由 Performance Evaluator 针对实际执行基准测量。这是唯一把性能而非正确性作为主要收敛标准的系统。
基于分数的收敛
基于分数的收敛使用智能体评估中间输出计算的定量质量分数决定何时停止。MAGE [Zhao2024MAGE] 通过仿真不匹配分数 s(r)=1-m(r)/tc(r) 对候选程序排序,并继续迭代直到最大分数达到 1.0。CodeCoR [Pan2025CodeCoR] 使用四标准二元分数(清晰度、相关性、简洁性、上下文)在每个智能体阶段剪枝中间输出,并在其 Ranked Code Set 中选择排名最高的代码作为最终输出。它设置软正确性收敛——提交最佳可用结果而非等待完美解。Trae Agent [gao2025traeagent] 引入与之密切相关的搜索-选择视角(在仓库尺度上):它把 issue 解决表述为最优解搜索问题,并使用模块化生成、剪枝与选择智能体在候选补丁的大集合空间中导航。在这一设置中,收敛不仅是反复修复的问题,也是在仓库感知证据下对竞争解进行排名、过滤与选择的问题。
共识收敛
共识收敛聚合来自多个审阅智能体的判断。CANDOR [Xu2025Hallucination] 在三个 Panelists 之间对 oracle 正确性实施多数投票。MAGIS [Tao2024Magis] 使用 QA Engineer 的 LLM 判断作为接受信号,尽管这是单智能体共识而非多智能体投票。QualityFlow [Hu2025QualityFlow] 使用其 Code Quality Checker 作为单一门控信号。这是一种高效设计——质量检查器同时充当收敛 oracle 与系统控制器,支持早期退出(75–84% 的问题在第一次生成器调用后收敛)。
隐式收敛
在固定阶段或迭代数后没有客观质量标准地流水线终止,是文献中最普遍的收敛模式,也代表该领域最显著的缺口。ChatDev [Qian2023ChatDev] 在固定阶段数后终止,或当连续两轮产生相同代码时,或在 10 轮后——这些都不是客观质量信号。MetaGPT [Hong2023MetaGPT] 在完成固定 SOP 阶段后终止。Self-Collaboration [Dong2024SelfCollaboration] 在 n=4 次迭代后若测试者从未批准则回退到隐式收敛。EvoMAC [Hu2025EvoMAC] 运行固定 K 次的文本反向传播循环。隐式收敛的普遍存在是缺乏正式共享基质的直接后果:没有程序状态的客观表示,系统就没有有原则的收敛标准。
4.4 模式与趋势
在系统间,角色专门化、共享状态表示、执行 grounded 与工作流拓扑的差异不是独立的工程选择;它们相互作用以决定一组智能体能多可靠地在长周期编码任务上保持连贯。本小节提炼综述系统中涌现的主要趋势,既凸显当前系统的常见结构瓶颈,又指出朝向更稳健共享框架的设计原则。
隐式框架状态约束
大多数综述系统(ChatDev [Qian2023ChatDev]、MetaGPT [Hong2023MetaGPT]、FlowGen [Lin2025Soen101]、CodePori [Rasheed2024Codepori]、SEW [Liu2025SEW]、MapCoder [islam2024mapcoder]、CodeCoR [Pan2025CodeCoR])在没有共享代码框架显式表示的情况下运作。这些系统依赖智能体在每次调用时从对话历史中隐式重构状态。这一设计选择对程序状态简单且不分散在智能体间的函数级任务有效。然而,这种隐式方法造成根本性脆弱:没有正式共享基质,智能体无法可靠地检测其内部理解何时与真实程序状态发散 [Guo2025SyncMind]。从代码即智能体框架视角看,对隐式状态表示的依赖是系统脆性的技术根源,而不是可扩展性便利。
代码中介通道不消除协调瓶颈
从自由形式对话向代码中介协调的转变是真正的架构进步,但不应被夸大。文件、API、差异、测试、日志、模式、黑板与工作流状态都是部分通道——任务状态通过它们被编码、传输并重构。每个通道在保真度、延迟与范围之间权衡:测试把语义压缩为通过/失败,摘要以细节为代价节省上下文,日志是 grounded 但嘈杂,共享黑板提升持久性但产生权威与一致性问题。因此核心设计问题不仅是代码是否存在,而是哪些产物是权威的、它们如何被压缩,以及跨通道冲突如何被解决。
执行反馈作为语言学与形式推理之间的桥梁
文献中最深的分歧在使用执行作为真实基线的系统与依赖语言学模型判断的系统之间。把共享状态 grounded 到执行的系统(AgentCoder [huang2023agentcoder]、AutoSafeCoder [Nunez2024AutoSafeCoder]、QualityFlow [Hu2025QualityFlow]、EvoMAC [Hu2025EvoMAC]、MAGE [Zhao2024MAGE])可访问客观 oracle 信号——不会幻觉的信号。然而一个令人惊讶的发现使这一图景复杂化:Self-Collaboration [Dong2024SelfCollaboration] 与 QualityFlow [Hu2025QualityFlow] 表明,LLM 仿真执行可以在不运行代码的情况下在预测实际结果上达到 98%+ 的精度与召回。这表明执行反馈的价值并非在所有失败模式上均匀分布。它在检测语言学仿真在结构上无法想象的边缘情况(运行时崩溃、资源耗尽、边界条件错误、性能回归)方面出色,但对许多可纠正缺陷,仿真推理可能就够了。成熟的框架将整合两者:用语言学推理作快速路径,只在需要时把验证 oracle 委派给执行——针对那些需要它的失败模式。
共享框架的两种互补表示
综述系统揭示两个概念上正交的视角:基于仓库的表示(结构:什么函数调用什么、数据如何流动、依赖是什么)与基于执行的表示(行为:代码运行时做什么、状态在运行时如何演化、在不同输入下出现什么涌现失败)。MAGIS [Tao2024Magis] 与 HyperAgent [Phan2024HyperAgent] 主要在仓库视角中运作——使智能体能推理代码库架构。AgentCoder [huang2023agentcoder] 与 MAGE [Zhao2024MAGE] 主要在执行视角中运作——把共享状态 grounded 到运行时信号。然而综述系统中没有一个完全把这两种视角统一到单一框架基质中——使智能体既能跨代码的静态结构又能跨其动态行为推理。最深的框架将整合这两种视角,回答如”哪些组件慢”(需要调用图与剖析数据)或”这次重构会破坏外部代码依赖的 API 吗”(需要静态分析与动态测试)这样的问题。
拓扑复杂度与框架状态形式化程度反相关
具有显式、形式化共享基质的系统使用更简单的拓扑,而缺乏正式共享状态的系统使用日益复杂的拓扑模式作为结构性变通。L2MAC [Holt2023L2MAC] 拥有最清晰的形式化框架基质(带显式上下文调度的持久文件存储),使用带复杂状态管理的简单顺序链。相反,隐式状态系统如 EvoMAC [Hu2025EvoMAC] 与 SEW [Liu2025SEW] 开发了复杂的自适应拓扑(动态 DAG、工作流变异、智能体池扩展),试图在缺乏有原则共享表示的情况下优化协作结构。这表明拓扑复杂度部分是症状:当基质被形式化表示并可查询时,智能体可以通过简单、透明的协议协调。当基质是隐式的,智能体需要更丰富的交互模式来补偿缺失的状态信息。
智能体专门化提高共享状态指标的重要性
随着智能体角色多样性增加——从基本编码者-测试者对到拥有架构师、经理、导航者、执行者与验证者角色的系统——对统一共享基质的需求变得紧迫。没有对代码状态的共享理解,规划智能体可能基于过时的代码库快照分解任务,执行智能体可能针对与合成智能体所意图不同的版本运行测试,验证智能体的反馈可能误火。EvoMAC [Hu2025EvoMAC] 通过其在 MAS 级显式监控失败归因的 Gradient 与 Updating 智能体处理这一点。SyncMind [Guo2025SyncMind] 把问题形式化为智能体信念发散 |B_{k}-S_{k}|——提出显式同步协议。智能体角色的增多因此不仅是工程选择。它是发展更成熟共享框架的推动力。拥有丰富角色库的多智能体系统若没有这些机制,无法稳健运作。
5 新兴领域与开放问题
在通过其接口、机制与编排模式刻画代码作为智能体框架后,我们现在考察这一范式如何在具体应用领域中实例化,以及它暴露了哪些开放问题。在编程助手、GUI/OS 智能体、科学发现、个性化与具身智能体中,代码不仅是模型输出,也是状态表示、行动执行、记忆、反馈与治理的操作基质。这些领域让代码中心智能体系统的承诺变得具体,同时揭示一组共同的未解挑战——围绕评估、验证、安全、协调、多模态 grounding 与框架演化。
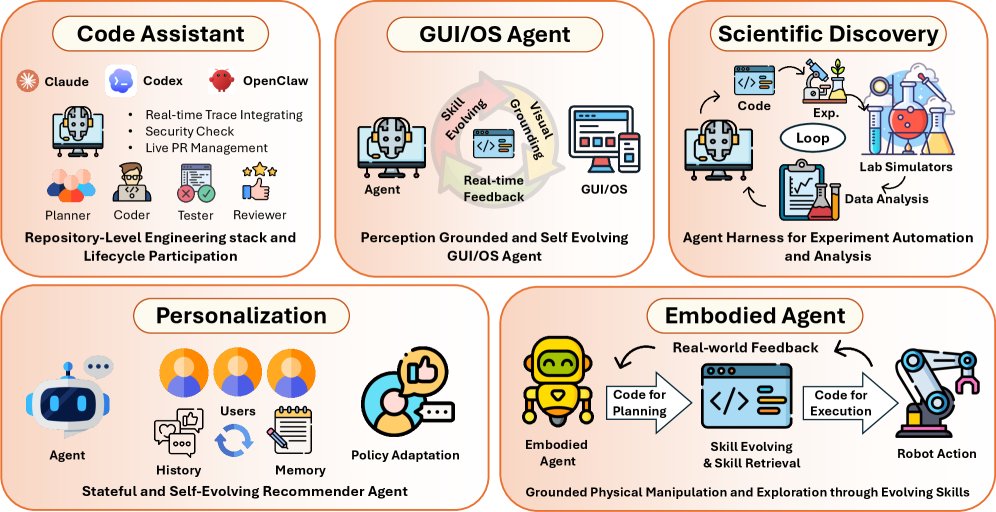
图 12:跨编程助手、GUI/OS 智能体、科学发现、个性化与具身智能体五个新兴领域的代码即智能体框架概览。
5.1 新兴领域与具体应用
本小节综述五个代码即框架系统尤为显著的应用领域。代码助手在仓库、测试、开发工具与协作工作流上运作;GUI 与 OS 智能体通过可执行行动与程序化检查器操作渲染的界面;科学智能体把假设、实验、分析与实验室协议组织为可执行流水线;个性化智能体通过结构化用户反馈与可编辑偏好状态适应推荐策略;具身智能体把高层意图 grounded 到受物理约束的可执行技能上。这些领域共同表明代码如何把模型输出连接到现实世界系统,以及围绕框架的设计如何塑造可靠性、可控性与长周期自主性。
5.1.1 代码助手
代码助手提供了代码中心智能体系统变得可操作的最清晰应用领域之一。早期系统主要支持局部补全或单轮代码生成。近期助手则跨仓库级工作流运作——编辑、工具使用、验证与拉取请求交互形成闭环的智能体过程。这一转变体现在 SWE-agent [yang2024swe] 与 OpenHands [wang2024openhands] 等研究系统,以及 Claude Code [claudecode2025]、Codex [codex2025]、GitHub Copilot coding agents [copilotagent2025] 与 DeepAgents [deepagents2025] 等生产导向平台。在这些系统中,助手不再是独立的代码生成器。它嵌入到开发环境中——仓库状态、工具、验证例程与协作工作流为行动与反馈提供操作上下文。
仓库中心的工作区
现代代码助手在仓库而非孤立代码片段上运作。源文件、测试、构建脚本、依赖元数据、issue、分支与拉取请求形成持久工作区——智能体可以跨多个步骤检查、修改与验证。这使仓库级辅助不再仅是把相关文件放入提示的问题,更是在大型且演化的代码库上构造任务专属工作视图的问题。RepoCoder [zhang2023repocoder]、CodexGraph [liu2024codexgraphbridginglargelanguage] 与 AutoCodeRover [zhang2024autocoderover] 等系统通过仓库索引、依赖感知检索、基于图的代码表示与编辑前的智能体定位处理这一问题。在这一意义上,仓库成为代码助手据以规划、行动并接收反馈的操作基质。
可执行开发框架
可执行开发框架正在成为代码助手的运行时与控制平面。最近的系统不再向模型暴露平铺的工具列表,而是把它包裹在受管开发循环中——控制仓库访问、文件编辑、命令执行、批准边界、上下文隔离、日志与验证。这一趋势在生产系统中可见:Claude Code 把本地终端/IDE/浏览器编码打包到一个工具中介循环中,带有编辑、命令执行、权限、钩子、记忆与子智能体;Codex 与 GitHub Copilot coding agents 把类似循环移到带沙盒、分支、批准与可审计拉取请求输出的受管云或 GitHub 原生工作区;DeepAgents 把规划、文件系统支持的状态、上下文管理、代码执行与子智能体委派暴露为可复用的框架组件 [claudecode2025, codex2025, deepagents2025, copilotagent2025]。这些循环越来越多地由 Model Context Protocol [anthropic2024mcp, hou2025model] 等开放协议中介——它们标准化框架如何向模型暴露工具、上下文与资源,并支持跨系统的工具复用。同时,近期研究把框架本身视为优化对象而非固定包装:AutoHarness [lou2026autoharness] 从环境反馈合成代码框架,Meta-Harness [lee2026metaharness] 用先前候选与执行轨迹在框架代码上搜索,Agentic Harness Engineering [lin2026agentic] 通过可观察性演化编码智能体框架,Natural-Language Agent Harnesses [pan2026natural] 把角色、契约、适配器与状态约定外化为可编辑的框架规范。这些进展共同表明,代码助手的实际进展越来越不仅由基础模型的改进塑造,也由周围的执行运行时——其沙盒、权限、上下文管道、遥测与验证钩子——塑造。
执行反馈作为 grounded 验证
代码助手的一个显著属性是机器可检查反馈的可用性:编译器诊断、测试结果、Linter 警告与运行时轨迹。Agentless [xia2024agentless] 表明,由测试执行引导的故障定位与补丁生成流水线在 SWE-bench [jimenez2024swebench] 上达到有竞争力的结果——无需精细的智能体控制。RepairAgent [bouzenia2025repairagent] 与 Live-SWE-agent [xia2025live] 把这一循环扩展为由测试结果驱动的自主程序修复,而 AlphaCodium [ridnik2024alphacodium] 表明测试驱动的流程工程相比单次提示显著改进竞赛编程性能。执行因此把每个候选编辑从一个文本假设转化为程序世界的可验证变换。
仓库级的记忆与上下文管理
仓库通常超出任何合理上下文窗口,迫使代码助手维护显式、结构化的记忆。检索增强补全 [zhang2023repocoder]、基于图的代码索引 [liu2024codexgraphbridginglargelanguage]、文档导向智能体如 RepoAgent [luo-etal-2024-repoagent] 与最近的上下文检索基准如 ContextBench [li2026contextbench] 实例化 §3.2 的记忆抽象,带有代码特有的转折:存储的项(如函数、测试、轨迹与检索到的 issue 上下文)本身可执行或与可执行状态直接相关,可以被重新运行、检查或定位,而不仅仅是被重读。近期记忆系统把可复用智能体过程或仓库经验存储为过程性与经验性记忆,进一步扩展这一视角 [gaurav2025codemem, wang2026memgovern]。这缩小了常规智能体架构中记忆与环境之间的差距,并使抽象管理变得尤为关键——助手必须为给定子任务呈现合适尺度的代码与经验。
开发者意图与项目约定作为潜在状态
除了显式仓库状态,实际的编码助手必须推理潜在的开发者意图与项目约定。有用的补丁不仅应通过可见测试,还应符合仓库架构、编码风格与内部 API 复用——近期工作把这些属性描述为生成代码的有机性(organicity)[li2026learning]。忽略这些约束的智能体可能产生技术上正确但维护者仍会拒绝的补丁 [li2026learning, thillen2026codetaste],而基准分析表明,一些看似已解的 SWE-bench issue 依赖于 issue 文本中的解泄漏,而非真正的意图推断 [aleithan2024swe]。编码辅助因此是一个部分可观测的程序世界问题:文件、测试与工具输出提供可观测状态,而设计理由、隐含约束与团队约定必须从 issue 线程、先前提交、代码评审与累积交互历史中推断。这把在 SyncMind 中研究的信念态发散从共享多智能体状态扩展到单智能体与用户的对齐 [Guo2025SyncMind]。建模这一潜在状态对从功能性代码生成走向可信赖的开发者协作至关重要。
从内联补全到自主 SWE 智能体
代码助手的演化可视为开发框架围绕模型的扩展。早期系统如基于 Codex 的补全 [chen2021evaluating] 与 Copilot [peng2023copilot] 等商业助手依赖轻量 IDE 框架:本地上下文被呈现、内联建议被生成、开发者仍是主要执行者、验证者与状态管理者。生产力 [peng2023copilot] 与可用性 [vaithilingam2022expectation, mozannar2022reading] 研究表明,即便这种轻量框架也很重要——因为建议的价值依赖于其与开发者演化的程序状态与意图的对齐。在自主端,SWE-agent、OpenHands、AutoCodeRover 与 Agentless 等系统在仓库级框架中运作——从孤立代码生成转向有状态的检查、编辑、执行与修订。
从补丁生成到软件生命周期参与
代码助手也在从孤立的补丁生成转向更广泛的软件生命周期参与。SWE-bench 把仓库级辅助框定为 issue-to-patch 任务 [jimenez2023swe],而新的基准 SWE-Lancer [miserendino2025swe] 与 SWE-Bench Pro [deng2025swe] 评估更长周期、经济上有意义的软件交付物——跨越多个文件并需要专业工程努力。Terminal-Bench [merrill2026terminal] 与 AppWorld [trivedi2024appworld] 等相关基准进一步反映同样的转变——向智能体必须通过命令、工具与可执行应用状态运作的交互式环境 [xie2024osworld, yao2025taubench]。在部署中,这一趋势表现为在持久工程工作流中工作的智能体——而非静态仓库快照——包括拉取请求评审、CI/CD 反馈与生产 issue 解决 [tang2024codeagent, Baqar_2025]。在生产规模上,LingmaAgent 报告:一个在阿里云自主部署的 issue 解决智能体完全自主地解决 16.9% 的内部 issue,在人工干预下解决 43.3% [ma2025alibaba, li2026advances]。这表明代码助手正在成为工作流参与者,而不仅是补丁生成器。
多智能体代码辅助与共享仓库
在谱系的高端,代码辅助越来越采用多智能体形式——规划者、编码者、测试者与审阅者角色在共享仓库上运作。ChatDev [Qian2023ChatDev]、MetaGPT [Hong2023MetaGPT]、CodeAgent [zhang2024codeagent] 与 METAL [li2025metal] 表明,角色专门化结合共享可执行产物如何能支持单智能体难以在长周期上维持的协调模式。仓库连同其测试与执行轨迹既是通信媒介也是收敛目标——直接实例化 §4 的共享程序世界。然而并发编辑可能悄然使其他智能体持有的假设无效,暴露同一节中讨论的世界状态同步挑战。
框架作为蒸馏面
2026 年一个决定性的发展是,生产框架不再仅是部署基础设施;它们正成为下一代代码助手模型的主要训练数据来源。Cursor 的 Composer 用真实 Cursor 使用轨迹的持续在线强化学习训练——收紧已部署智能体行为与模型更新之间的循环 [cursor2025composer, cursor2025rtrl]。OpenAI 的 codex-1(o3 衍生)[codex2025]、GPT-5-Codex [openai2025gpt5codexcard] 与 GPT-5.1-Codex-Max [openai2026codexmax] 在显式上以镜像 Codex 框架循环的长周期、多轮编码交互上训练,而 Anthropic 的内部 Claude Code 自食其狗食在其 teams-using-Claude-Code 白皮书中记录了类似的反馈通道 [anthropic2025teams]。同时,框架本身正成为显式优化对象:AutoHarness [lou2026autoharness] 用较小 LLM 合成框架代码以过滤非法行动,Agentic Harness Engineering [lin2026agentic] 关闭一个可观察性驱动的框架组件演化循环,Meta-Harness [lee2026metaharness] 形式化联合模型-框架优化,Live-SWE-agent [xia2025live] 在运行时编辑自身脚手架——共同表明”智能体”与”包裹智能体的框架”之间的边界正成为一个本身可学习的表面。
代码助手框架的开放挑战
生产框架的成熟揭示了若干编码特有的开放问题——补充下一小节讨论的跨域议程。第一,单元测试之外的验证仍大体未解决:PatchDiff [wang2025solved] 与 SWE-Bench++ [anonymous2025swebenchpp] 揭示的 oracle 充分性危机、Aardvark [openai2025aardvark] 与 Codex Security [openai2026codexsecurity] 处理的安全-正确性差距,以及功能性与被接受补丁之间的有机性差距 [li2026learning, thillen2026codetaste],都指向当前框架尚未充分规范的验证器表面。第二,长周期智能体循环中的失败归因仍不成熟:“Why do multi-agent systems fail?” [cemri2025whymas] 等实证研究、Who&When 归因数据集 [zhang2025whoandwhen]、AgenTracer [agentracer2025] 与 AgentDebug [zhu2025llm] 报告最佳步级归因准确率在 14–53% 范围内——表明生产框架缺乏有原则调试所需的结构化轨迹。第三,自主代码执行的安全治理需要基于能力的原语——这些在实践中仍罕见:Aethelgard 的学到的能力治理者 [anonymous2026aethelgard]、容错事务沙盒 [anonymous2025faultsandbox] 与 Microsoft 的 Agent Governance Toolkit [microsoft2026governance] 代表在并发智能体行动下强制最小特权的早期步骤。第四,生产规模的框架自演化——AutoHarness、AHE 与 Live-SWE-agent 仅在窄场景中展示——引出非自我修改框架中不存在的稳定性与回滚问题。第五,实时仓库上的多智能体状态同步把 SyncMind 信念态发散问题 [Guo2025SyncMind] 推广到人类、自主智能体与 CI 系统并发变更共享程序状态的场景。最后,结对编程用户体验中的信任校准仍是一个研究不足的人因问题——包括何时中断、何时检查点、何时委派、何时延后的决策——尽管它对框架驱动的自主性能否安全扩展到企业工作流至关重要。
代码助手因此是代码中心智能体系统最清晰的生产实例,也是横跨工业界与学术界正在涌现的框架工程学科最严苛的测试场。
5.1.2 GUI/OS 智能体作为程序世界
图形用户界面与操作系统也许比基础模型智能体的任何其他具体应用都更字面地构成程序世界:智能体接收的每个观测都是可执行代码的渲染输出(HTML、CSS、布局 XML、辅助功能 API、由窗口管理器驱动的帧缓冲),它采取的每个行动都是对另一段代码的调用(DOM 事件、adb shell 命令、被 OS 事件循环捕获的击键、Playwright 脚本)。因此,GUI/OS 智能体已成为核心论点——代码是统一基质,通过它感知、行动、环境动态与记忆都可被表示、执行与验证——的典型测试场。下面系统地展开这一视角。
GUI/OS 作为部分可观测程序世界
我们把 GUI/OS 环境建模为部分可观测马尔可夫决策过程 \langle\mathcal{S},\mathcal{A},\mathcal{O},T,R\rangle,其中潜在状态 s \in\mathcal{S} 是一个或多个进程的完整程序状态(浏览器的完整 DOM 与 JavaScript 堆、Android 模拟器的 Activity 栈与内容提供者、Linux VM 的文件系统与窗口树)。智能体永远不直接观察 s;它观察 o \in\mathcal{O},在现代系统中后者采用四种代码定义形式之一:(i) 序列化的 DOM 或 HTML 子树,如 WebArena 与 Mind2Web 所采用 [zhou2024webarenarealisticwebenvironment, deng2023mind2webgeneralistagentweb];(ii) Android UIAutomator 或 macOS/Windows 辅助功能 API 暴露的辅助功能树(AXTree),如 AndroidWorld 与 WindowsAgentArena 采用——例如 AgentOccam 使用 [rawles2025androidworlddynamicbenchmarkingenvironment, bonatti2024windowsagentarenaevaluating, yang2024agentoccam];(iii) 注释了边界框或 Set-of-Mark 坐标的截图——SeeAct、WebVoyager、OSWorld 与大多数近期原生模型采用的表示 [zheng2024gpt4visiongeneralistwebagent, he2024webvoyagerbuildingendtoendweb, xie2024osworldbenchmarkingmultimodalagents, yang2023setofmarkpromptingunleashesextraordinary];或 (iv) 混合表示——交错像素、辅助功能元数据与 HTML,如 WebArena 的 BrowserGym 观测空间与 CogAgent 的双分辨率编码器 [drouin2024workarenacapablewebagents, hong2024cogagentvisuallanguagemodel]。行动空间 \mathcal{A} 同样是代码:一个元组 \langle action\_type,target,value\rangle,既可编译为 DOM/辅助功能调用(element.click()、setText(node_id, ”…”)),也可编译为 OS 级键盘/鼠标原语(pyautogui.click(x,y)、xdotool key)。关键的是,转移函数 T 不是学习的,而是被执行的:浏览器引擎、Android 运行时或宿主 OS 确定性地产出下一观测。智能体通常被框定为类人计算机用户:它们感知视觉界面,对用户指令推理,并通过对人类可用的同一图形通道执行行动。智能体的策略 \pi(a|h) 因此最好视为程序合成器——给定历史 h,它发出下一段可执行代码;环境是解释器。
代码作为用户界面与 GUI 智能体之间的桥梁
近期工作把代码视为高层模型推理与低层 UI 执行之间的中间接口 [xie2024osworldbenchmarkingmultimodalagents, wang2025guiagentsfoundationmodels, xu2024androidlabtrainingsystematicbenchmarking]。这一接口提供两大优势:第一,它抽象掉嘈杂的视觉细节,在模型的语义规划与系统的可执行控制层之间创建自然边界。第二,它把感知、行动与评估融合到单一的代码即框架流水线中。
在行动侧,这是更广义 CodeAct 范式的 GUI 专门化 [wang2024executablecodeactionselicit]:智能体不发出 JSON 工具调用,而是发出组合原语的 Python 或 JavaScript 片段(如 click(x, y)、type(text)、scroll(dx, dy)、key(“Enter”)与任意库调用,如 requests、subprocess、selenium)。Cradle 通过让一个 LMM 输出驱动键盘与鼠标的可执行 Python(可用于任何应用,包括 AAA 游戏)显式实现这一点——通过技能整理与自我反思跨先前未见软件实现泛化,而非依赖任务特定 API [tan2024cradleempoweringfoundationagents]。WebArena、BrowserGym 与 TheAgentCompany 类似地暴露 Playwright 风格的代码行动——其执行是进度的真实基线 [zhou2024webarenarealisticwebenvironment, drouin2024workarenacapablewebagents, xu2025theagentcompanybenchmarkingllmagents]。
在感知侧,近期原生 GUI 模型如 SeeClick、CogAgent、Ferret-UI、OS-Atlas、ShowUI、Aria-UI、UGround、UI-TARS 与 GUI-Libra 把 grounding 视为从像素到可执行坐标的函数——训练大型视觉语言模型发出 (x,y) 或 bbox token,可直接送入行动 API [cheng2024seeclickharnessingguigrounding, hong2024cogagentvisuallanguagemodel, you2024ferretuigroundedmobileui, wu2024osatlasfoundationactionmodel, lin2024showuivisionlanguageactionmodelgui, yang2025ariauivisualgroundinggui, gou2025navigatingdigitalworldhumans, qin2025uitarspioneeringautomatedgui, yang2026guilibratrainingnativegui]。通过把 planner→grounder→executor 流水线折叠到单一 VLA 模型——其输出 token 流本身可运行的代码——这些系统消除了历史上把语言计划与 grounded 行动分离的脆弱字符串匹配层,正如 SeeAct 在 Mind2Web 上的分析所示:grounding 而非规划是主要瓶颈 [zheng2024gpt4visiongeneralistwebagent]。
在评估侧,代码定义的环境支持可执行反馈:成功不是由学习的奖励模型决定,而是通过对动作后系统状态运行评估器脚本来决定。WebArena 的 URL/字符串断言、OSWorld 对 OS 文件 I/O 与应用状态运作的每任务 Python 检查器、AndroidWorld 基于 adb 的状态检查与 Spider2-V 的企业工具检查都共享同一模式——评估器本身是一段代码,在智能体完成后查询程序世界 [zhou2024webarenarealisticwebenvironment, xie2024osworldbenchmarkingmultimodalagents, rawles2025androidworlddynamicbenchmarkingenvironment, cao2024spider2vfarmultimodalagents]。这关闭了循环:代码生成环境,代码是智能体的行动,代码裁定结果。
记忆作为持久程序化状态
对于代码 grounded 的 GUI 智能体,记忆最好理解为持久的程序化状态层:在当前 UI 状态之外存活,可在后续交互中被检索、组合或执行的结构化产物。近期工作探索了几条记忆思路:(i) UI 状态的工作记忆把当前观测压缩为任务相关的抽象:Synapse 的状态抽象模块把 HTML 过滤到几个任务相关元素——支持轨迹作示例的提示与按相似性检索先前轨迹的示例记忆 [zheng2024synapsetrajectoryasexemplarpromptingmemory]。(ii) 长期跨应用/会话记忆作为结构化文档与技能库实现:AppAgent 为每个应用编译一个探索文档——记录每个 UI 元素学到的功能,在后续任务中查询 [zhang2023appagentmultimodalagentssmartphone];Mobile-Agent-v2 引入专门的规划智能体,其记忆跨子任务跟踪长周期进度 [wang2024mobileagentv2mobiledeviceoperation];Cradle 维护显式的技能整理模块,把成功代码片段提升到可复用库 [tan2024cradleempoweringfoundationagents]。这些设计与宿主应用的 UI 本体紧密耦合,而 PlugMem 提出一个任务无关的插件记忆模块——把原始交互轨迹蒸馏为命题与规范性知识的紧凑、知识中心的记忆图,从 Web 智能体到长周期对话与多跳检索保持不变迁移 [yang2026plugmemtaskagnosticpluginmemory]。(iii) 自演化 GUI 智能体(已在本综述中作为 UI-Voyager [lin2026uivoyagerselfevolvingguiagent] 引用)与 AutoGLM 通过持续在线课程强化学习扩展这一思想,持续增长 grounded 行为库,而 OS-Genesis 与 UI-TARS 用数百台虚拟机上的反思式轨迹采集作为蒸馏记忆形式 [liu2024autoglmautonomousfoundationagents, sun2025osgenesisautomatingguiagent, qin2025uitarspioneeringautomatedgui]。在所有三种范式中,记忆本身是代码产物——例如 JSON 文档、Python 技能模块或代码格式化轨迹的向量索引——可直接执行或直接组合到智能体的下一行动中。
UI 模拟器与沙盒作为可执行动态
GUI/OS 智能体的模拟器栈也许是该领域中”环境动态即代码”的最清晰展示。早期基准如 MiniWoB++ 把每个任务定义为带程序化奖励函数的自包含 HTML/JavaScript 页面 [liu2018reinforcementlearningwebinterfaces];WebShop 把这扩展到 118 万真实 Amazon 商品的自托管购物站点 [yao2023webshopscalablerealworldweb]。Mind2Web 缓存真实世界轨迹用于离线评估,而 WebArena 与 VisualWebArena 把四个完整开源站点 fork 到带确定性重置与每任务功能检查器的 Docker 容器 [deng2023mind2webgeneralistagentweb, zhou2024webarenarealisticwebenvironment, koh2024visualwebarenaevaluatingmultimodalagents]。OSWorld 进一步把这推到 369 个真实 Ubuntu/Windows/macOS 任务——位于一次性 VM 中,初始状态、黄金行动与 Python 评估脚本都是版本控制产物 [xie2024osworldbenchmarkingmultimodalagents];WindowsAgentArena 把同一架构专门化到 Windows 11——支持 Azure 并行执行 [bonatti2024windowsagentarenaevaluating];Spider2-V 把 OSWorld 扩展到专业数据工程流水线——跨越 BigQuery、dbt 与 Airbyte [cao2024spider2vfarmultimodalagents]。在移动端,AndroidWorld 提供 116 个程序化任务——从自然语言模板动态参数化,奖励信号来自设备系统状态,而 AndroidArena 与 AndroidLab 提供互补的跨应用评估 [rawles2025androidworlddynamicbenchmarkingenvironment, xing2024understandingweaknesslargelanguage, xu2024androidlabtrainingsystematicbenchmarking]。BrowserGym 与 WorkArena 把许多这些统一在共同的 Gym 风格 API 下,并添加 23,150 个企业 ServiceNow 任务实例 [drouin2024workarenacapablewebagents];AgentBench 的 OS 与 Web 轨道,以及 OpenHands 驱动的 TheAgentCompany 基准,把 GUI 控制置于更广泛的知识工作仿真中 [liu2025agentbenchevaluatingllmsagents, xu2025theagentcompanybenchmarkingllmagents]。最近,Code2World 在模型层级明确化程序世界立场——训练一个视觉语言编码器预测下一 GUI 状态作为可渲染 HTML,把世界模型本身转化为可执行产物,并把渲染结果作为强化信号 [zheng2026code2worldguiworldmodel]。这些沙盒共同体现综述的论点:智能体系统中的环境动态越来越多地以代码编写——它们可分支、可比较、版本控制、可复现,这是任何学到的模拟器都无法媲美的。
从仿真到生产:可执行反馈循环
让模拟器易处理的代码即框架接口也使其从仿真到生产部署的转变异常迅速——因为智能体的输入/输出契约在两种场景中相同:截图进,代码(或坐标类型化函数调用)出。Anthropic 的 Claude Computer Use 暴露了公测 API——模型对沙盒桌面截图并把键盘/鼠标行动作为结构化工具调用发出 [anthropic2024computeruse]。OpenAI 的 Operator 与底层 Computer-Using Agent(CUA)紧随其后——把 GPT-4o 的视觉与强化学习推理结合到统一的点击/滚动/输入行动空间 [openai2025operator]。Google DeepMind 的 Project Mariner 推出一个由 Gemini 驱动的 Chrome 扩展——观察渲染的 DOM、规划并代表用户执行浏览器行动,并正被整合到 Search 的 AI 模式与 Gemini 应用中 [deepmind2025mariner]。字节跳动的 UI-TARS-1.5/2 与相关 UI-TARS-desktop 产品、智谱的 AutoGLM(Web 浏览器插件与 Android 应用)与腾讯的 AppAgent 系列表明同一架构可从实验室迁移到消费设备 [qin2025uitarspioneeringautomatedgui, liu2024autoglmautonomousfoundationagents, zhang2023appagentmultimodalagentssmartphone]。AutoWebGLM——CogAgent 的生产同源——通过”中间接口”把规划与 grounding 解耦,例示了从 arXiv 预印本到部署浏览器智能体的路径 [lai2024autowebglmlargelanguagemodelbased]。早期工业努力(如 Adept 的 ACT-1/ACT-2 与 Rabbit 的 Large Action Model)预示了这一轨迹,但出现在可执行反馈基础设施之前——后者后来才让循环可靠到足以部署。
展望未来,文献在三个前沿上汇聚——都以代码即框架术语表达。第一,把感知、规划、grounding 与行动内化到单一 VLA 模型的原生端到端智能体正在取代模块化的 planner+grounder 流水线。第二,可执行世界模型有望让智能体获得类人前瞻——通过把下一 UI 状态预测为可渲染代码而非像素或非结构化文本。第三,具身、指令跟随的 GUI 智能体把整个设备(例如终端、浏览器、原生应用与外设)视为统一的程序世界。共同线索是:代码是通用语;它定义观测、行动、评估、记忆,且越来越定义世界模型本身。
5.1.3 自主具身智能体
具身智能体在物理世界或其仿真中运作——通过视觉与力传感器的结构化输出感知环境,并通过受可达性、碰撞与动力学等物理约束的运动命令行动。
代码作为连接智能体与世界的控制边界
与纯推理智能体不同,具身智能体在违反时可能沉默失败的物理约束下运作:机器人可能试图抓取其工作空间之外的物体而不产生任何显式失败信号 [liang2023codepolicieslanguagemodel]。这把正确性的负担从运行时转移到行动生成时——智能体的输出必须已足够表达,能在到达执行器之前组合经过验证的操作意图。代码自然满足这些要求——既作为 grounding 接口,也作为安全边界。作为 grounding 接口,它通过原语技能调用 [ahn2022can, ren2023robots, zhai2026skillvla, zhang2023bootstrap]、合成的 Python 控制策略 [liang2023code, mu2024robocodex, xie2025robotic, wang2025llm, ji2026genswarm] 与结构化行为树程序 [zhang2025codebt] 把 LLM 的高层意图翻译为符合具身的命令。作为安全边界,它在执行时约束允许的行动 [guan2025normcode, szeider2025cp, miculicich2025veriguard]。
用于 grounded 且可验证的具身行动的层级化框架
具身智能体需要层级化框架——把语义推理与可执行、物理 grounded、人类治理的控制分离 [vemprala2024chatgpt]。基础模型处理具身智能的语义层:解释目标、分解任务、推断 affordance、选择技能、提出行动并在观察变化下重规划 [huang2022inner, wang2023voyager]。代码与经典机器人软件通过暴露有类型的机器人 API、参数化原语技能、调用几何库、调用运动规划器并支持检查、回放、版本化与验证来定义允许性边界 [xie2025robotic, liang2023code, huang2023voxposer, macenski2020nav2]。感知模型与状态估计器把原始传感器流转化为规划器与控制器可用的结构化状态 [driess2023palme, deepmind2025geminirobotics]。物理系统与低层控制器则强制具身特定的约束——例如运动学、动力学、避障、工作空间限制、接触力、时序与稳定性。
可复用技能作为具身记忆
代码把单个行动 grounded 到物理可行性,但在长周期上运作的具身智能体还必须跨任务积累经验。在这一范式中,代码承担第二个角色:让行动可验证的同一可执行形式也使其可存储、可复用。记忆因此自然地以技能库形式出现——一组代码产物的集合,它们记录过去行为并可在未来任务中作为行动调用。这种双重身份把具身记忆与 §3.2 中其他记忆抽象区分开来:技能不仅是智能体阅读的东西,也是智能体重新执行的东西。Voyager 用面向 Minecraft 开放式任务的增长技能库开创了这一范式 [wang2023voyager],其他工作沿多个方向扩展同一思想:桌面操作 [tziafas2024lifelong]、人类纠正 [meng2025growing]、视觉 grounded 重规划 [kagaya2025vireskill] 与持续学习 [wang2026lifelong]。这一原则甚至跨越到 GUI 领域 [lin2026uivoyagerselfevolvingguiagent]。在这些系统中,挑战已从生成技能转移到治理库:处理遗忘、抽象与 grounding 对齐。
协调且可审计的真实世界部署
从仿真到真实世界部署引入超越单智能体的挑战:多个机器人必须协调、行为必须可审计、技能必须跨具身迁移。代码自然扩展以处理这三者。对于协调,它为多机器人策略合成 [ji2026genswarm] 与机器人无关的协作架构 [ashley2026racas] 提供基质。对于可审计性,它支持工业安全 [guan2025normcode, liu2026agents4plc] 与经验证的闭环控制 [santos2026alrm] 的治理机制。对于跨具身迁移,同一基于代码的技能抽象支持双臂系统的组合式复用 [zhai2026skillvla]。在减少 sim-to-real 差距、扩展多智能体协调以及在环境演化时维持安全方面仍有开放挑战。
5.1.4 科学发现的智能体作为程序世界
科学研究是代码作为智能体框架最自然的试验场之一:科学方法本身就是”假设→设计→执行→观察→修订”的闭环,其中每个转移都由一种产物中介——这种产物越来越多地是一个程序。现代科学已经可以端到端数字化,例如,假设被编码为微分方程或生成模型,实验协议被写为 XDL 或 Opentrons 脚本,仪器通过 Python API 驱动,分析存在于其单元构成可验证推理轨迹的 Jupyter notebook 中。这使科学发现成为实例化代码三重角色的理想领域:代码作为推理的媒介(如符号推导、形式证明、假设作为程序)、代码作为行动的基质(如对湿实验机器人、模拟器、统计流水线的调用)、代码作为可执行环境本身(如分子动力学引擎、自主实验室、虚拟研究团队)。AI Scientist v1/v2 [lu2024aiscientistfullyautomated, yamada2025aiscientistv2workshoplevelautomated]、AI co-scientist [gottweis2025aicoscientist]、Virtual Lab [swanson2025virtual] 与 Biomni [huang2025biomni] 等近期系统通过把整个研究工作流提升到单一可执行程序图,把这一代码即框架表述具体化。
科学发现作为部分可观测程序世界
我们把研究项目视为部分可观测程序世界 \langle\mathcal{S},\mathcal{A},T,\mathcal{O},R\rangle。状态 \mathcal{S} 是包含当前最佳假设、累积文献、代码产物、中间数据集与实验观察的结构化程序记忆。行动 \mathcal{A} 是有类型的代码表达式:文献搜索查询、对符号或数值求解器的调用、新实验脚本的生成、对训练流水线的修改或机器人控制命令。转移函数 T 由 Python 解释器、Lean 内核、量子化学包、机器人合成器实现,或在 AI Scientist v2 [yamada2025aiscientistv2workshoplevelautomated] 等完全端到端系统中由编排所有这些的树搜索实验管理器实现。观测 \mathcal{O} 对应执行输出(数值结果、图表、错误消息、同行评审分数),潜在奖励 R 编码新颖性、可复现性与统计显著性等期望。关键的是,科学智能体的策略本身是程序:ChemCrow [bran2023chemcrowaugmentinglargelanguagemodels] 通过结构化工具调用组合 18 个专家设计的化学工具;Coscientist [boiko2023autonomous] 交错 Python 执行、网络搜索与机器人 API 行动;AlphaProof [hubert2025olympiad] 把每个”推理步骤”表达为 Lean 战术——证明助手在转移状态前验证它。这一视角把传统上非正式的类别(如假设、协议、声明)重新铸造为具体程序对象——其执行轨迹可被记录、回放与审计。
统一构思、实验、分析与传播
传统科学叙述把构思、实验设计、数据分析与传播分为不同工作流——使用不同工具。代码中心智能体把这些折叠到单一可执行流水线中。ResearchAgent [baek2025researchagentiterativeresearchidea] 与 SciAgents 风格系统通过遍历文献的实体图迭代式精炼假设——每个候选思想被物化为可传递给下游规划器的结构化对象。BioPlanner [odonoghue2023bioplannerautomaticevaluationllms] 把湿实验协议形式化为伪代码——其允许的函数可被类型检查、检索与组合——为生物学提供 XDL 为化学提供的同种组合式基质 [mehr2020universal]。Agent Laboratory [schmidgall2025agentlaboratoryusingllm] 及其预印本共享扩展 AgentRxiv [schmidgall2025agentrxivcollaborativeautonomousresearch] 显式地把研究分为三个程序级阶段:文献综述、实验、报告写作——由专门化的 PhD、博士后与工程师智能体编排,他们交换 Python 文件、LaTeX 与 arXiv 记录。AI Scientist [lu2024aiscientistfullyautomated, yamada2025aiscientistv2workshoplevelautomated] 走得更远——把整篇 ML 论文表示为单一可执行轨迹:系统用编码助手写实验代码、执行它、用视觉语言模型读图,并发出包含其生成的同样图表的 LaTeX 手稿。在所有这些系统中,过去是异质自然语言产物流水线的内容变为有类型代码对象的同质流——支持端到端优化与每阶段的自动验证 [ren2026scientificintelligencesurveyllmbased, wang2024executablecodeactionselicit]。
记忆作为持久程序状态
长周期研究依赖记忆:先前实验、失败尝试、引用图与隐性实验室经验。代码中心智能体把这一记忆外化为持久程序状态。在工作记忆层,智能体维护可执行草稿板——通常是 Jupyter 内核或 CodeAct 风格的 Python REPL [jiang2025aideaidrivenexplorationspace]——其活变量、数据框与图表形成推理的直接上下文。El Agente Q [Zou_2025] 与 Biomni [huang2025biomni] 例示层级化记忆:短期工具输出被缓存在情景缓冲区中,而结构化产物(质粒图、优化几何、拟合模型)被写入持久文件存储——后续智能体步骤可以重新加载。在长期层,PaperQA / PaperQA2 [lala2023paperqaretrievalaugmentedgenerativeagent] 与 Google 的 AI co-scientist [gottweis2025aicoscientist] 把科学文献本身视为索引知识库——通过工具调用访问以检索段落、扩展引用并检测矛盾;这支持针对数百万先前结果评估假设而不膨胀提示。AgentRxiv [schmidgall2025agentrxivcollaborativeautonomousresearch] 把这一思想再推进一步——为自主研究智能体提供共享预印本服务器:一次运行产生的假设、代码与发现作为持久程序产物上传——未来运行可在其上构建——把累积式科学进展实例化为全球共享、版本控制的程序状态。Biomni 的行动发现智能体 [huang2025biomni] 挖掘数万篇 bioRxiv 论文以填充跨 25 个生物医学子领域的统一工具注册表——使”记住如何克隆一个质粒”成为从持久存储导入一个验证过的代码级协议的具体行动。
模拟器作为可执行动态
科学智能体依赖物理与计算现实的模拟器,而代码即框架视角把这些统一视为可执行转移模型。在计算化学中,El Agente Q [Zou_2025] 把 DFT 引擎、几何优化器与热化学工具包装为 LLM 调用的可调函数——以推演替代反应轨迹;在六个大学级基准上,它超过 87% 的任务成功率,同时发出每个仿真的透明行动轨迹日志。ChemCrow [bran2023chemcrowaugmentinglargelanguagemodels] 类似地集成 RDKit、逆合成引擎与反应预测器——使智能体能在投入湿实验运行前”执行”候选合成。在结构与系统生物学中,Virtual Lab [swanson2025virtual] 把 ESM、AlphaFold-Multimer 与 Rosetta 组合到一个 Python 流水线——通过它一个 LLM 首席研究员智能体与其下属科学家智能体共同设计了 92 个 SARS-CoV-2 纳米抗体,其中两个对 JN.1 与 KP.3 变体显示了被验证的结合——所有这些都在仅数天的仿真会议中完成。对算法与数学科学,AlphaProof [hubert2025olympiad] 把 Lean 定理证明器用作可执行环境——在强化语言模型前形式化验证每个候选证明步骤;AlphaEvolve [novikov2025alphaevolvecodingagentscientific] 编排一个演化循环——其中 Gemini 生成的代码编辑由自动评估器执行并打分——产出新的矩阵乘法算法与数学构造。在每种情况下,模拟器都是世界:程序状态仅通过经过验证的执行演化——消除了困扰纯文本科学推理的大量幻觉 [ren2026scientificintelligencesurveyllmbased]。
从仿真到生产:自驾驶实验室作为可执行反馈循环
科学智能体的决定性测试是其闭环是否能跨越到物理现实。自驾驶实验室(SDL)是这一领域的生产系统:它们通过代码 API 暴露真实仪器——如液体处理器、XRD 扫描仪、光谱仪、机器人手臂——并接受智能体生成的程序作为主要输入。伯克利的 A-Lab [szymanski2023autonomous] 把机器学习合成配方与自主机器人结合——在 17 天连续运行中从 58 个目标列表合成 41 个新无机化合物;早期薄膜 SDL [macleod2020selfdrivinglaboratoryaccelerateddiscovery] 确立了贝叶斯优化循环可以包装为 Python 服务并无人值守运行。Coscientist [boiko2023autonomous] 把这一门槛跨到有机化学——从单个英语提示自主规划、执行并分析钯催化的 Suzuki 与 Sonogashira 偶联——在 Emerald Cloud Lab 与一个内部液体处理平台上。Cronin 小组的 Chemputer 与其 XDL 化学描述语言 [mehr2020universal] 形式化这一契约:文献中发表的任何合成可以被解析为硬件无关的 XDL 代码——它像化学的 LLVM IR 一样,编译到任何合规的机器人平台。在生物学中,Biomni [huang2025biomni] 生成端到端的分子克隆协议——人类评审认为其与一位资深 Stanford 博士后相当;Google 的 AI co-scientist 的药物再利用与抗微生物耐药假设在 Imperial College 与 Stanford 的合作湿实验室中得到实验验证 [gottweis2025aicoscientist]。MatPilot [ni2024matpilotllmenabledaimaterials] 显式地把假设生成认知模块与驱动物理合成机器人的自主实验验证模块耦合——为材料实例化完整的”生成-执行-反馈”循环。这些系统让综述的核心论点变得切实:在自驾驶实验室中,智能体的策略就是代码,实验室就是运行时,出版记录就是日志。
朝向智能体式与指令跟随式科学
代码即框架科学智能体的最后一个维度是可控性:在保留严格执行语义的同时,用高层科学意图引导它们。基准已迅速涌现以度量这一能力。MLAgentBench [huang2024mlagentbenchevaluatinglanguageagents] 在 13 个开放式 ML 研究任务上评估语言智能体——要求智能体读代码、运行实验并改善指标。MLE-bench [chan2025mlebenchevaluatingmachinelearning] 把这扩展到 75 个 Kaggle ML 工程比赛;发布时表现最好的脚手架(OpenAI o1-preview 加 Weco AIDE 树搜索智能体 [hu2025surveyscientificlargelanguage])在 16.9% 的比赛中达到 Kaggle 铜牌水平,AIDE 实现的奖牌率约为次高智能体的三倍。ScienceAgentBench [chen2025scienceagentbenchrigorousassessmentlanguage] 编译 102 个改编自同行评审出版物的任务——覆盖生物信息学、计算化学、GIS 与认知神经科学——把每个目标输出统一为自包含 Python 程序,这是对代码作为数据驱动科学通用接口的明确认可。DiscoveryBench [majumder2024discoverybenchdatadrivendiscoverylarge] 用 264 个多步假设搜索任务跨六个领域补充这一点——暴露当前智能体的失败模式(最佳系统分数 \sim 25%)。在可控性侧,指令跟随的进展在 AI co-scientist [gottweis2025aicoscientist](科学家通过自然语言研究目标与约束引导多智能体辩论)、Biomni [huang2025biomni](其图形界面接受自然语言查询并返回可审计代码执行)与 Virtual Lab [swanson2025virtual](人类 PI 指定高层目标,AI PI 动态配置专业特定的智能体团队)等系统中可见。AlphaEvolve [novikov2025alphaevolvecodingagentscientific] 与 AlphaProof [hubert2025olympiad] 代表目标条件化的极端:智能体只被给定一个目标函数或定理陈述,封闭代码执行循环搜索任何满足验证器的程序。在这些系统中,指令跟随通过把用户目标翻译为运行时可严格强制的有类型程序规范实现。
总体而言,科学发现智能体的近期工作例示了综述的核心转变:从静态预测走向交互式、有状态、可执行的决策。假设不再是漂浮的句子,而成为参数化程序;实验不再是实验室笔记本,而成为版本控制代码;分析不再是一次性脚本,而成为下游智能体可重新执行的可复现产物;实验室不再是不透明的物理场所,而成为可通过文档化 API 访问的生产运行时。结果是一个闭环的”生成-执行-反馈”循环——其中单一基质(即代码)承载科学推理、科学行动与科学环境本身——为像 AI Scientist [lu2024aiscientistfullyautomated, yamada2025aiscientistv2workshoplevelautomated]、AI co-scientist [gottweis2025aicoscientist]、Virtual Lab [swanson2025virtual]、Biomni [huang2025biomni]、Coscientist [boiko2023autonomous] 与 AlphaEvolve [novikov2025alphaevolvecodingagentscientific] 这样的智能体被比较、组合并渐进改进提供统一基础。正如 MLAgentBench [huang2024mlagentbenchevaluatinglanguageagents]、MLE-bench [chan2025mlebenchevaluatingmachinelearning]、ScienceAgentBench [chen2025scienceagentbenchrigorousassessmentlanguage] 与 DiscoveryBench [majumder2024discoverybenchdatadrivendiscoverylarge] 等基准所明确的,开放挑战不是代码即框架智能体能否模仿孤立的科学任务,而是它们能否被信任自主驱动完整循环——这是一个程序世界抽象既提供正确本体也提供正确实验框架的挑战。
5.1.5 智能体个性化
个性化与推荐系统为代码中心智能体系统提供了一个独特场景。与编码、GUI 控制或科学发现不同,这里的环境不仅是软件系统,也包括一个用户——其意图、满意度与长期目标仅部分可观测。当推荐从静态排名走向交互式智能体时,核心挑战变成如何通过反复交互维护、更新与治理用户模型。代码在此场景中有用,不只因为它执行推荐策略,更因为它为偏好表示、反馈处理、约束强制与策略适应提供可检查的基质。
从静态推荐到交互式个性化
传统推荐系统通常把个性化视为预测问题:给定历史交互,系统对候选项打分并返回排序列表 [he2020lightgcn, guo2017deepfm]。基于 LLM 的推荐器拓宽这一视角——支持对话式偏好引出、解释与多步精炼。早期基于提示的方法用用户历史查询 LLM 并要求其直接产出推荐 [hou2024large, dai2023uncovering]。更具智能体性的系统则把推荐分解为候选检索、过滤、重排、解释与反馈采集。新兴的智能体推荐 [liu2025recoworld, wang2024recmind, huang2025recommender] 通过让 LLM 借助工具调用与结构化中间状态协调推荐子任务来实例化这一方向。Agent4Rec [zhang2024generative] 与 iAgent [xu2025iagent] 进一步用合成用户仿真推荐会话——支持对交互策略的离线评估。这些系统标志着推荐从一次性打分到自适应过程的转变——每次交互都可能修订系统对用户的信念。
偏好状态作为可编辑产物
个性化智能体与其他智能体系统的关键差异在于最重要的状态并非完全可观测。用户偏好是潜在、上下文相关且常常不稳定的。用户可能出于方便而点击某项(而非真正兴趣)、由于时机而跳过某项(而非不喜欢),或跨会话改变目标。个性化智能体因此需要显式偏好状态——能吸收嘈杂行为信号同时保持可解释与可纠正。基于代码的表示为构造这一状态提供了实用方式。短期兴趣可存储为最近的交互日志、上下文摘要或会话级偏好向量。长期偏好可作为结构化记忆对象维护——记录稳定兴趣、约束与用户提供的纠正。AMem [xu2026mem] 与相关基于记忆的系统 [wei2025evo, chhikara2025mem0] 展示如何把长期用户信息维护为可编辑文档或结构化记录。MemRec [chen2026memrec] 进一步研究协同信号如何支撑面向个性化推荐的记忆管理。与不透明的纯嵌入记忆相比,结构化偏好记忆更易于检查、修订与复用。用户可以用自然语言纠正存储的偏好,系统可以在生成未来推荐前更新相应状态。
反馈作为策略适应
个性化智能体由反馈驱动,但反馈往往稀疏、延迟且模糊。点击、停留时间、评分、购买、跳过与对话纠正都提供关于用户满意度的部分证据。生产推荐系统已经依赖代码定义的反馈流水线——记录交互、计算指标、运行 A/B 测试并触发模型或策略更新。在智能体场景中,这些流水线成为个性化框架的一部分:它们决定记录哪些信号、如何解读它们,以及智能体何时应适应。用户模拟器 [zhang2025llm, wang2025user, liu2025recoworld] 提供研究这种适应的离线方式。它们允许在真实部署前在受控行为假设下测试推荐策略。近期基于 LLM 的模拟器通过生成更丰富的合成用户画像与交互轨迹扩展这一思想。然而核心困难仍在于仿真反馈可能与真实用户行为不匹配——尤其当推荐本身影响未来偏好时。
可控与指令跟随的个性化
智能体个性化的一个重要机遇是超越优化隐式参与信号——走向跟随显式用户指令。用户可能希望推荐满足某些约束——例如避免特定来源、限制重复类别、平衡探索与熟悉度,或在长期目标与短期参与之间优先长期目标。这些要求难以通过单一学习的分数表达,但可作为结构化约束、过滤器或奖励函数表示。基于 LLM 的对话式推荐器可以用自然语言引出这些偏好并把它们翻译为策略规范 [hou2024large]。基于约束的推荐进一步表明如何在服务时强制公平性、多样性与曝光要求——而非隐藏在模型参数中 [lei2020conversational]。基于解释的系统提供了另一条朝向可控性的路径:若系统解释为何推荐某项,用户可纠正其理由,纠正后的解释可更新偏好状态。这让个性化更具交互性与可审计性——因为用户不仅可以塑造输出,也可以塑造产生未来输出的逻辑。
个性化框架的开放挑战
个性化提出几个比其他领域更尖锐的挑战。第一,偏好 grounding 仍未解决。与可以依赖测试的代码助手或可以检查界面状态的 GUI 智能体不同,个性化智能体缺乏对真实用户满意度的可靠 oracle。点击与参与等代理指标在被过度激进地优化时可能误导甚至有害。第二,偏好记忆引入隐私与治理风险。长期用户模型可能包含敏感行为模式——因此框架必须规定存储什么、存储在哪、如何更新,以及用户如何检查或删除。第三,个性化本质上是多利益相关者的。平台可能优化参与度,创作者可能寻求曝光,用户可能重视福祉或自主性。把这些目标简化为单一奖励函数可能掩盖利益冲突。
5.2 开放问题
代码即框架系统把智能体 AI 的核心挑战从孤立的模型生成转移到完整执行循环的可靠性。一旦智能体通过工具、记忆、代码执行、共享状态与环境反馈行动,失败可能源于薄弱的验证器、陈旧的上下文、不安全的工具访问、不一致的多智能体状态、不充分的多模态 grounding 或治理不善的自我改进。这些问题不能仅通过最终任务成功诊断。本节概述当框架被视为一等系统组件时涌现的关键开放问题——目标是构建可执行、可检查、有状态、可验证、且在长周期现实环境中受治理的智能体系统。
5.2.1 框架级评估与 oracle 充分性
一旦 LLM 嵌入代码智能体框架,评估就变得困难。在这一场景中,性能不再仅由基础模型决定,也由周围运行时决定:检索哪些仓库文件、暴露哪些工具、允许多少次重试、智能体能否执行测试、失败如何被摘要、由哪个验证器决定成功。然而,大多数现有评估度量端任务成功:生成的解是否通过测试、解决 issue 或完成交互式任务。这种指标把基础模型能力、框架质量、工具可靠性、反馈信息量与环境难度混淆在一起。这在仓库级软件工程中尤其明显——智能体可能通过可见测试,却利用薄弱或不完整的测试套件;在 GUI/OS 任务中,脚本化检查器可能错过不安全或不可取的中间行动;在科学或具身场景中,模拟器中的成功执行可能并不意味着结果在科学上有效或在物理上安全 [jimenez2024swebench, deng2025swe, miserendino2025swe, merrill2026terminal, jain2024livecodebench, chen2025scienceagentbenchrigorousassessmentlanguage]。
一个关键开放问题因此是定义评估操作基质本身的框架级指标。这些指标应在最终任务准确率之外补充执行可靠性、反馈质量、上下文可持续性、安全性、协调与可复现性的度量。有用维度包括:(i) 轨迹效率——如工具调用、token、编辑、执行与挂钟时间的数量;(ii) 验证强度——如测试覆盖率、oracle 多样性与误接受率;(iii) 恢复能力——如智能体能否在无效行动后诊断并修复失败;(iv) 状态一致性——如记忆、仓库状态、执行轨迹与智能体信念是否保持同步;(v) 安全合规——如权限、沙盒与人审关卡是否被尊重;(vi) 可回放性——如完整轨迹能否从日志与产物重构并审计 [anthropic2026agentevals]。这一议程的核心瓶颈是oracle 充分性:评估器是否捕获了预期任务而非仅一个窄的可执行代理。开放问题不仅是构建更难的基准,而是把代码智能体框架作为可执行运行时系统进行评估。
5.2.2 超越可执行反馈的语义验证
oracle 充分性变得尤其具挑战性,因为执行反馈——尽管对代码中心智能体至关重要——可能产生正确性的虚假感:代码可以运行、轨迹可以检查、测试可以校验、失败可以反馈到修订。然而,执行的可靠性只与附在其上的 oracle 一样。单元测试可能不完整,静态分析器可能过近似,GUI 检查器可能错过不可接受的中间行动,科学脚本可能编码无效假设,机器人模拟器可能隐藏物理风险。结果是,框架可能恰恰因为有可执行反馈而过度自信:智能体看到绿色测试,但绿色测试不是完整规范。
核心缺失的抽象是一个具有显式范围的验证栈。未来框架不应把通过/失败视为单一终止信号,而应组合多种验证产物:单元测试、集成测试、属性测试、模糊测试器、静态分析器、类型检查器、安全扫描器、运行时监视器、覆盖率报告、形式规范、模型批评与人审。每种产物应声明它验证什么、不能验证什么以及提供何种置信度。这对自我修复与自演化框架尤其重要:若验证器薄弱,智能体将学会针对错误信号优化。一个有用的方向是让每个被接受的行动都携带一个证据束——包含运行的检查、保留的假设、未测试的区域与剩余风险。从这一视角看,验证不是最终关卡;它是智能体、框架与环境之间的演化、可检查契约。
其他有前景的方向包括反馈校准、独立验证、变形测试、差分测试、属性测试生成、执行轨迹摘要与不确定性感知批评者 [ni2023lever, jung-etal-2025-code, tang2026execverify]。可靠的反馈也应根据其类型被不同路由:编译器错误可触发局部语法修复,测试失败可触发行为诊断,覆盖率间隙可触发测试生成,不一致的审阅者评论可触发仲裁。更广义的目标是构建不仅反应式而且认知感知的反馈循环:框架应知道信号何时足够强可据以行动、何时弱、何时需要额外证据。
5.2.3 无回归的自演化框架
大多数当前框架是人工设计的:开发者选择规划循环、记忆格式、工具集、权限规则、调试过程与智能体拓扑。然而,随着任务变得更长更多样,固定框架可能次优。适合竞赛编程的框架在仓库修复上可能失败;调优用于 GUI 导航的框架可能对科学工作流低效;在一种任务分布上成功的多智能体拓扑在另一种上可能浪费计算。这表明未来系统应把框架本身视为可适应新环境的可编程组件——而非围绕基础模型的固定包装。
自动框架演化已在进行中。AutoHarness 合成约束无效行动的代码框架 [lou2026autoharness],MetaHarness 在框架代码上搜索 [lee2026metaharness],Agentic Harness Engineering 从可观察性信号演化框架组件 [lin2026agentic],相关方法通过反思、搜索或执行反馈优化提示、上下文与工作流 [agrawal2025gepa, Liu2025SEW, zhang2025agentic]。这些系统指向一种更广泛的范式——一个总体优化过程分析运行时反馈(如计算成本、决策路径、工具使用轨迹、记忆压力与特定失败案例)并提议对框架本身的修改。这些修改可能重组子智能体间的通信、调整记忆分配、修订检索或验证策略,或改变执行反馈如何路由通过系统。因此,“自动框架演化”本身不是开放问题。更难的问题是:框架能否在不过拟合、不削弱安全、不增加成本、不隐藏失败或不在罕见但重要任务上回归的前提下改进自身。
核心洞察是,框架变异应像对安全关键运行时的代码变更一样对待。每个提议的编辑都应携带一份变更契约:修改了哪个组件、针对哪种失败模式、预测什么改进、必须保留哪些不变式、哪些评估能证伪它,以及如何回滚。这尤其重要,因为框架变更影响智能体未来行为的分布。新的检索策略可能提升基准准确率,同时增加幻觉证据;新的工具模式可能减少 token 成本,同时削弱权限边界;新的验证器可能通过接受规范不足的解来改善通过率。未来工作应发展证据携带的框架演化、保留的回归套件、安全不变式、金丝雀部署、回滚语义,以及说明为何某次框架编辑有效的因果证据。目标不是经常改变的框架,而是只在能证明该变更时才改变的框架。一个实际研究议程包括:为框架组件定义变异算子;构建遥测标准;在多样任务上评估演化的框架;在演化期间强制安全不变式;以及把框架的改进与基础模型的改进分离开来。
5.2.4 事务性共享程序状态与语义冲突解决
从单智能体扩展到多智能体系统把代码库变为共享框架基质。规划者、编码者、测试者、审阅者、安全智能体与人类可能都读取并修改重叠的产物。先前章节表明许多系统仍依赖顺序交接、共享日志或仅文件状态,而较新系统引入黑板、仓库记忆、执行反馈与显式信念态同步 [Qian2023ChatDev, Hong2023MetaGPT, huang2023agentcoder, wang2025openhands, Guo2025SyncMind]。开放问题是,仅同步本身并未提供事务语义或假设级一致性:这些机制常常同步产物但不同步假设。一个智能体可能基于旧仓库快照规划,另一个可能测试更新的补丁,第三个可能记住已过时的不变式,而人类审阅者可能引入未被传播到系统其余部分的新约束。
缺失的抽象是事务性共享程序状态。智能体不应仅向公共日志追加消息;每个行动都应声明其读集、写集、假设、版本依赖、验证器义务与冲突策略。冲突不应仅在文件差异层面检测,也应在计划、测试、检索证据、权限、记忆条目与潜在用户需求的层面检测。未来框架需要语义而非纯文本的冲突解决机制——包括语义合并、回滚、依赖感知锁定、信念态调和、冲突解释与合并后再验证。经典版本控制、数据库、CRDT 与构建系统提供有用类比,但智能体系统添加了常规工具看不到的冲突:不兼容的计划、陈旧的记忆、重复的子任务、不一致的工具权威与对用户目标的不同解释。一个关键研究挑战是确定冲突何时可自动解决、何时需外部判断。这些机制还要求超越合并正确性的指标——包括合并成功率、语义回归率、回滚频率、冲突复发率与人工干预成本。
5.2.5 人在环路的安全与问责作为框架状态
当代码即智能体框架系统被用于日益重要的场景时,安全不能被委托给基础模型,也不能仅作为自然语言指令编码。在软件部署、网络安全、金融、医疗、科学实验、企业自动化与具身控制等关键领域,智能体行动可能影响生产系统、私有数据、外部用户、物理设备或机构合规。框架因此需要不仅充当上下文管理器或工具执行者,还充当模型意图与现实后果之间的安全治理者。它应按风险对提议行动分类、强制权限层级、拒绝违反硬约束的行动,并要求对不可逆或外部后果的转移进行人审。例如,当智能体请求凭证、修改安全关键代码、访问用户数据、部署服务、发出金融或医疗建议或控制物理设备时,框架应能覆盖基础模型并暂停自主性直到人类决定 [Nunez2024AutoSafeCoder, vijayvargiya2025openagentsafety, guan2025normcode]。
未来框架需要在模型意图与环境行动之间中介的显式治理机制。一种有用的设计模式是多层权限模型。在最低层,智能体可能读取文件、检视日志并运行静态分析。在更高层,它们可能编辑本地文件、执行沙盒化代码、访问网络、调用外部 API、修改共享仓库或影响生产系统。每一层应规定其允许的行动、约束、审计日志、回滚机制与高风险操作的人在环路关卡。此类治理还必须是上下文敏感的。同一命令在一次性沙盒中可能安全,但在生产仓库中不安全;同一网络请求在文档检索期间可能无害,但在传输本地状态时危险。因此,权限不仅应取决于工具身份,还应取决于参数、环境状态、数据敏感性与预期副作用。开放问题包括策略规范、副作用预测、沙盒逃逸预防、密钥处理、安全工具模式、可逆执行,以及衡量自主性与安全性之间的权衡。
这一安全角色也改变人类反馈应如何表示。人在环路控制不应仅作为偶发的提示中断出现;它应成为持久的框架状态。每次批准、拒绝、策略例外或审阅者纠正都应更新框架的权限规则、升级策略、验证标准与未来记忆检索。同样,高风险批准应是可审计的状态转移:什么行动被提议、展示了什么证据、暴露了什么风险、谁批准或拒绝它,以及之后责任边界如何变化。开放问题是设计能决定何时自主性合适、何时人类判断强制的框架。从这一视角看,可靠的代码即智能体框架系统不仅需要可执行代码与可验证反馈,还需要可执行的问责制:一个在智能体行动到达现实世界之前对其过滤、否决、上升与记录的安全层。
5.2.6 多模态代码框架系统
大多数代码智能体框架仍围绕文本状态设计:提示、文件、日志、工具输出、测试与执行轨迹。然而,许多新兴智能体系统在关键状态是多模态的环境中运作。GUI 智能体观察截图、辅助功能树与渲染的界面状态;具身智能体依赖自我中心图像、深度、力、触觉信号、对象姿态以及模拟器或机器人状态;科学智能体检视图表、显微镜图像、分子结构与实验读数。在这些场景中,框架不能再把感知视为模型的被动输入。它必须把多模态观测作为持久、可查询、可验证的状态来管理。
一个核心挑战是多模态上下文压缩。视觉观测庞大、冗余,常常只部分与任务相关。GUI 截图可能包含数百个元素,而只有一个按钮重要;具身轨迹可能包含数千帧,而只有几帧揭示任务关键的对象关系、接触事件或失败原因。未来框架需要保留任务相关视觉证据的压缩机制——而不仅是减少 token 成本。这表明一种多层记忆设计:原始图像或帧作为不可变证据存储;对象、区域、元素与姿态级注释提供结构化的中间状态;紧凑的文本或符号摘要仅暴露技能检索与规划所需的信息。开放问题是决定何种多模态信息应被保留、抽象、遗忘或晋升到长期记忆——尤其当后续失败揭示更早的视觉或物理细节重要时。
视觉 grounding 引入第二个挑战:把观测与行动对齐。在文本中心框架中,行动通常可以针对文件、命令或测试结果检查。在视觉环境中,智能体必须把语言目标映射到图像区域、界面元素、对象、坐标、姿态与可执行行动。GUI 智能体必须知道计划点击对应于正确渲染的按钮;具身智能体必须知道抓取命令针对当前相机视角与物理配置下的预期对象。这要求框架级的 grounding 契约——连接感知、行动与验证。每个行动应不仅携带自然语言理由,还携带其依赖证据的 grounded 引用——例如边界框、对象标识符、UI 元素、帧索引、区域特征、对象位置或方向。执行后,框架应核验预期的 grounded 状态是否如期变化——而非仅依赖模型的自报告。
在多模态场景中,可靠反馈也更难。文本错误消息或单元测试失败提供显式信号,但视觉与物理反馈常常是隐式、延迟或模糊的。按钮可能看起来被点击但未触发正确状态转移;机器人可能看起来抓住物体但抓握不稳;图表可能看起来支持某个结论但其坐标轴尺度改变了解释。未来框架因此需要多模态验证栈——结合视觉状态检查、对象跟踪、OCR 或 UI 树检视、模拟器状态、物理传感器、触觉反馈与任务专属验证器。更重要的是,每个反馈信号都应暴露其范围与不确定性。例如,边界框检测器验证定位但不验证任务完成;模拟器状态验证对象位置但不验证物理鲁棒性;OCR 结果验证可见文本但不验证语义正确性。这也要求世界建模与行动建模之间更紧密的集成:框架应预测行动后视觉或物理世界预期如何变化,把该预测与观察到的结果比较,并用不匹配诊断失败。在具身与机器人场景中,这种预测误差信号对恢复尤为重要——因为失败可能源于遮挡、滑动、碰撞、不可达姿态或被违反的前提条件,而非显式错误消息。把多模态反馈视为校准证据(而非二元成功信号)对安全的长周期自主性至关重要。
多模态记忆也应支持技能演化。在 GUI 控制与具身操作等视觉中心领域中,可复用技能不能仅作为文本或代码片段表示。一个有用技能常常耦合多模态前提条件、可执行行动模式与预期后置条件:智能体行动前应看到或感知什么、应执行什么程序、UI 命令或运动原语,以及应有什么视觉、物理或状态变化随之。例如,GUI 技能可能编码如何从截图定位设置菜单、点击正确区域,并核验新面板出现。具身技能可能编码如何识别可抓取物体、选择接近姿态、执行原语控制器,并通过视觉、力或触觉反馈确认物体已移入抓爪。这些技能应从成功轨迹、失败尝试与人类纠正中演化——同时保留其 grounding 证据。框架因此必须决定视觉-行动模式何时可复用、应以何种抽象级别存储,以及如何跨布局、视角、具身、传感器或任务适配。
5.2.7 朝向框架工程学
总体而言,这些开放问题表明代码即框架研究正朝向更广义的框架工程学前进。研究的核心对象不再仅是模型或生成的程序,而是完整的闭环系统:上下文、记忆、工具、执行、反馈、安全、协调与评估。进展将需要暴露长周期失败的基准、让轨迹可审计的遥测、分离框架组件的指标,以及让智能体在持久程序世界中安全运作的设计原则。
最重要的未来系统可能是组合四项属性的系统。第一,它们将是*可执行的*——把决策 grounded 到代码、工具、测试与环境。第二,它们将是*可检查的*——暴露计划、状态、出处与失败原因。第三,它们将是*有状态的*——跨长轨迹与多个智能体保留任务相关信息。第四,它们将是*受治理的*——确保自主性受权限、验证与问责约束。这些属性定义了可靠、长周期智能体 AI 的下一个前沿。
相关笔记
- 解剖智能体Harness:从 harness 内部结构拆解智能体的工作机制
- Harness 工程:在智能体优先的世界里驾驭 Codex:Codex 视角下的 harness 工程实战
- Harness 工程:智能体时代真正的护城河:harness 为何是智能体系统的核心壁垒
- Agent Hooks:智能体工作流的确定性控制:在框架层加入确定性钩子的实践方式
- 扩展托管智能体:将大脑与双手分离:Managed Agents 在 harness 扩展上的取舍
- 长时间运行智能体的高效编排框架:长周期执行的编排框架设计
- 智能体记忆系统详解:记忆机制如何作为 harness 的核心组件
- AI代理的上下文工程:构建Manus的经验教训:Manus 的上下文工程经验
- 不碰模型与提示词,让编程智能体更聪明:harness 工程优于模型/提示工程的视角