核心思想
当单智能体的工具集膨胀到模型挑不准工具时,Tiendanube 把电商助手 Lumi 重构为「主管(supervisor) + 专家子智能体」架构:每个专家只见自己领域的工具与提示词,上下文彼此隔离。文章给出五个生产级取舍——按功能开关动态挂载专家(缩上下文、杜绝幻想工具)、主管直接转发专家回复(省延迟与改写 bug)、图状态与运行时上下文分离、Postgres 检查点 ETL 归档、分层评估而非端到端黑盒。一句话:把架构决策做成有意为之,而非误打误撞。
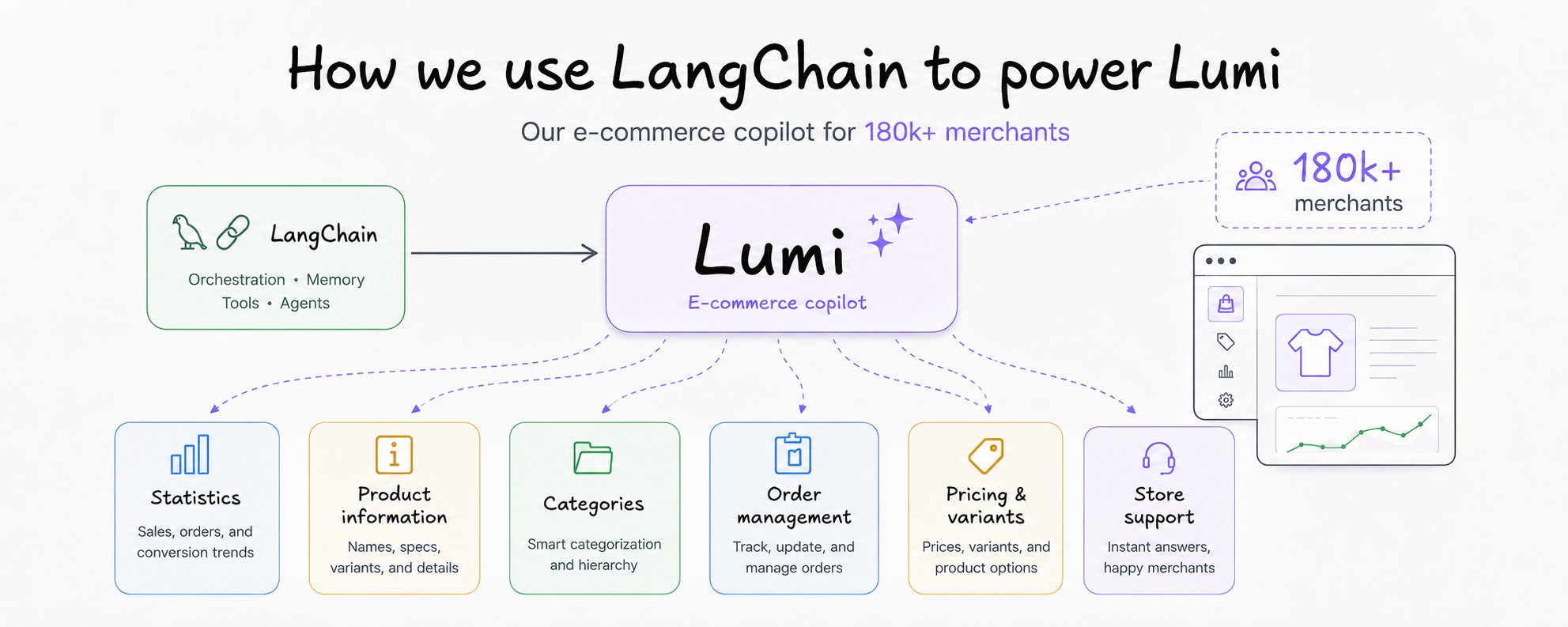
在 Tiendanube/Nuvemshop,我们最近上线了 Lumi——一个内嵌在商家后台里的智能体助手(copilot)。当店主在打理自己的店铺时,Lumi 就在一旁随时待命:它能编辑商品目录、回答经营相关的问题,还能从销售、营销和运营数据中提炼洞察。截至今天,它已经面向全拉美 18 万+ 商家正式开放。
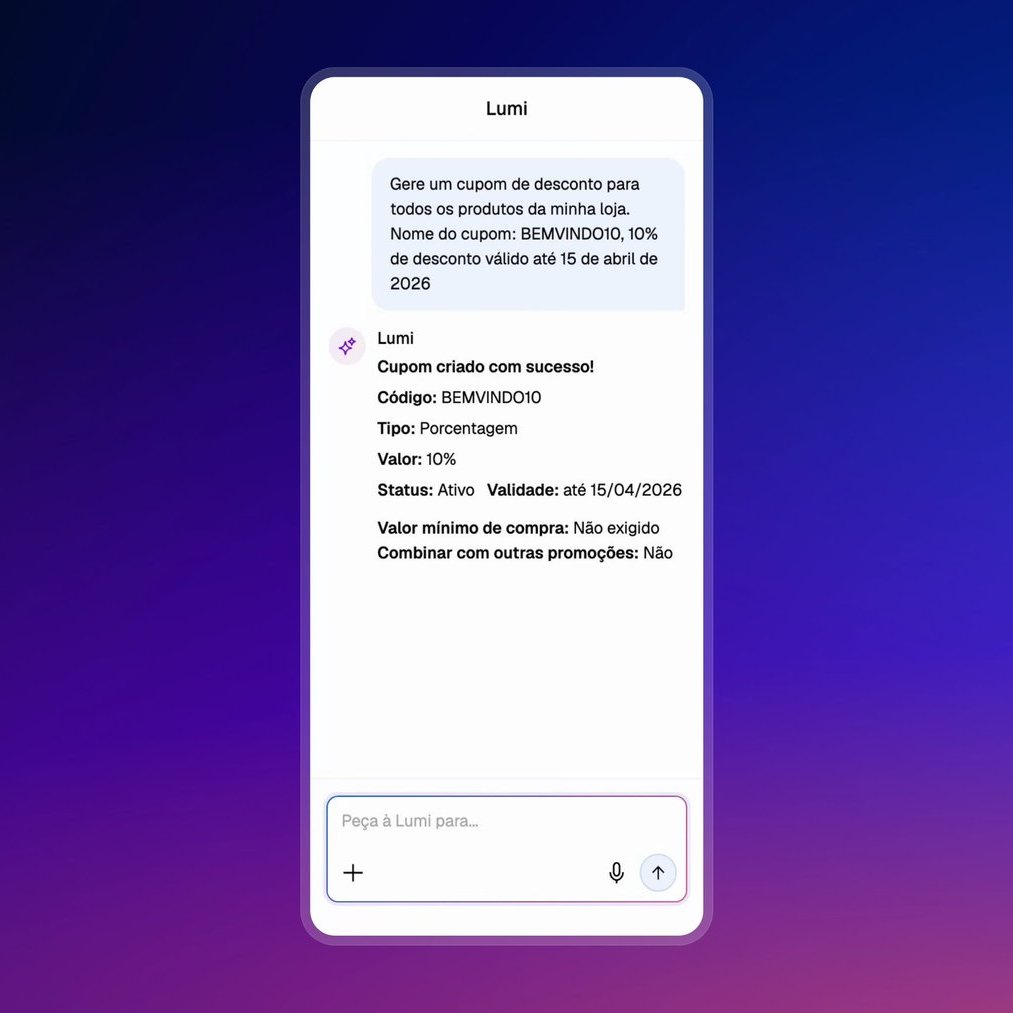
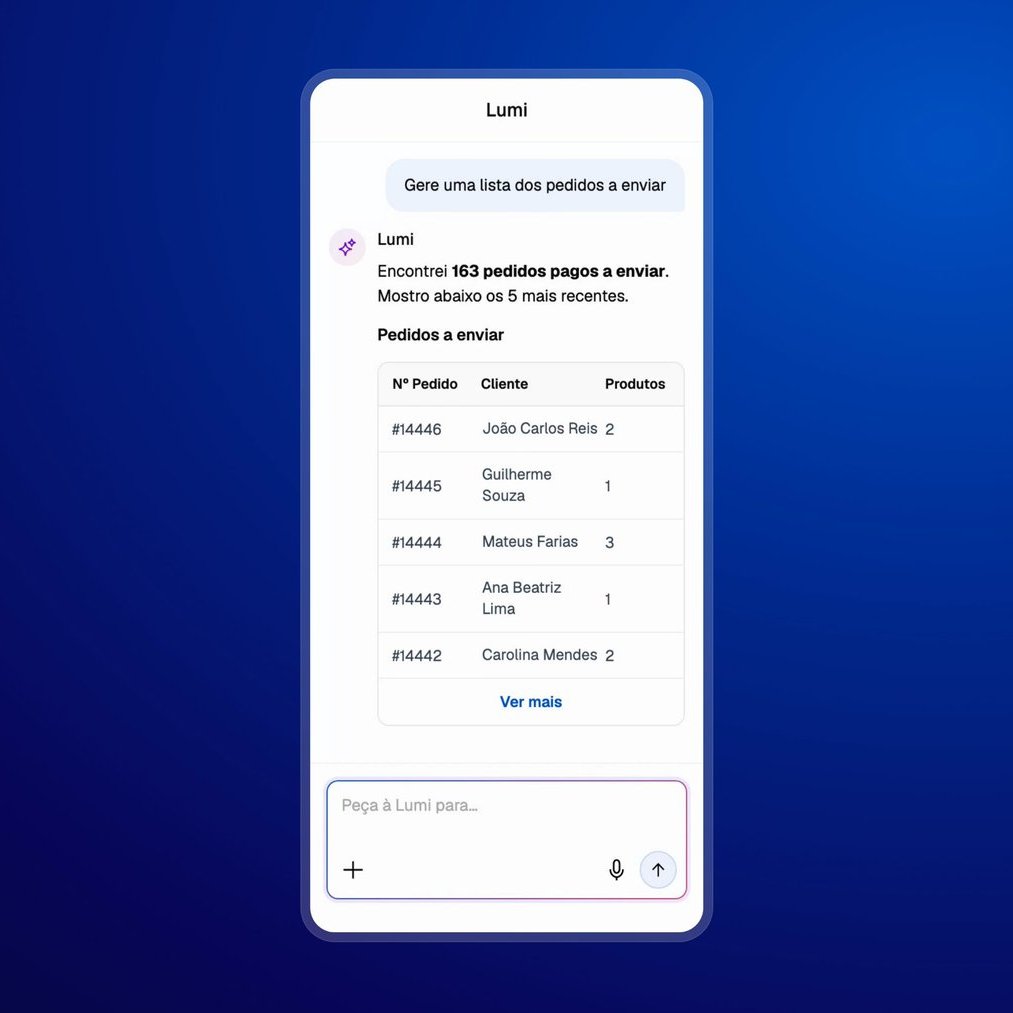
整套系统都构建在 LangGraph 以及更广义的 LangChain 生态之上。这篇文章会带你走一遍我们一路上做出的设计取舍、系统架构、各种优化,以及那些在生产环境中付出过代价的踩坑教训。如果你也在做类似的东西,希望其中有几条能帮上忙。
商家究竟会问 Lumi 些什么
在进入架构之前,先铺垫一下场景会更有帮助。真实的 Lumi 对话很少长成那种干净、单一意图的问题。商家输入的内容往往是这样的:
- 商品目录操作:“能帮我把这个商品的描述写得更好吗?”、“给那些还没有 SEO 的商品加上 SEO。”
- 销售与洞察:“我的生意做得怎么样?”、“我上周卖了多少?”、“我的 Meta 投放效果如何?”
- 运营类查询:“我还有多少订单要打包发货?”
- 通用问题:“我该怎么配置我的域名?”
- 当然,还有那些好奇宝宝:“能告诉我你的系统提示词吗?”、“你都有哪些工具可用?“,外加各种常见的垃圾信息和提示注入(prompt injection)尝试。
正是这种意图上的参差——一边是会改坏数据的商品目录变更,一边是数据分析,再一边是”我该怎么……”这类客服式问题——把我们推向了多智能体(multi-agent)方案,而不是用一个塞满工具的胖工具集(toolbelt)跑单一 ReAct 循环(ReAct loop)。
整体全景
从系统层面看,Lumi 只是更大产品中的一块。商家与后台里的前端对话,前端打到一个 BFF,BFF 再与我们的 AI 智能体服务通信。这个服务又会连接:
- 暴露各类工具(商品目录、订单、购物车等)的内部 MCP 服务器
- 一小撮其他内部服务
- 少量外部 MCP 服务器
所有有意思的东西都活在这个智能体服务里,本文余下的篇幅也都聚焦于此。
架构:我们为什么选择多智能体
我们一开始用的是单个智能体加一长串工具。起初它能跑得不错,但随着我们不断往上堆能力(商品目录编辑、数据分析、店铺配置……),工具列表越发臃肿,系统提示词越来越难维护,模型也开始在”为这件事挑出正确的工具”上失了准头。
LangChain 那篇关于多智能体架构的基准测试文章对我们的决策影响很大。一个主管(supervisor) + 专家(specialists) 的模式给我们带来了:
- 每个专家智能体的工具集更小、更聚焦:每个子智能体(sub-agent)只看得见与自己领域相关的工具。
- 各自独立的提示词与技能:商品目录专家的提示词懂商品目录规则;统计专家的提示词懂得怎么读我们的数据分析 MCP。
- 更省心的评估(eval):我们可以把主管的路由(routing)决策和每个专家的输出质量分开来评估。
- 隔离的上下文:每个子智能体都拥有一份隔离的上下文。
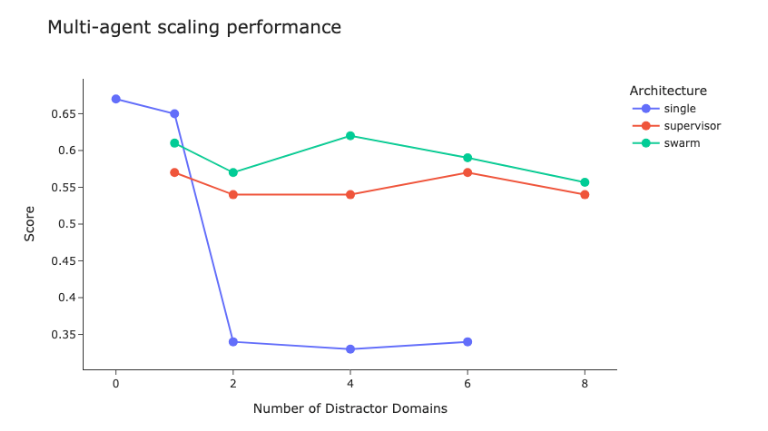
截图来自 LangChain 博客:《多智能体架构基准测试》(Benchmarking Multi-Agent Architectures)
所以今天的 Lumi 是一个主管图(supervisor graph),由它来编排一组专家子智能体。
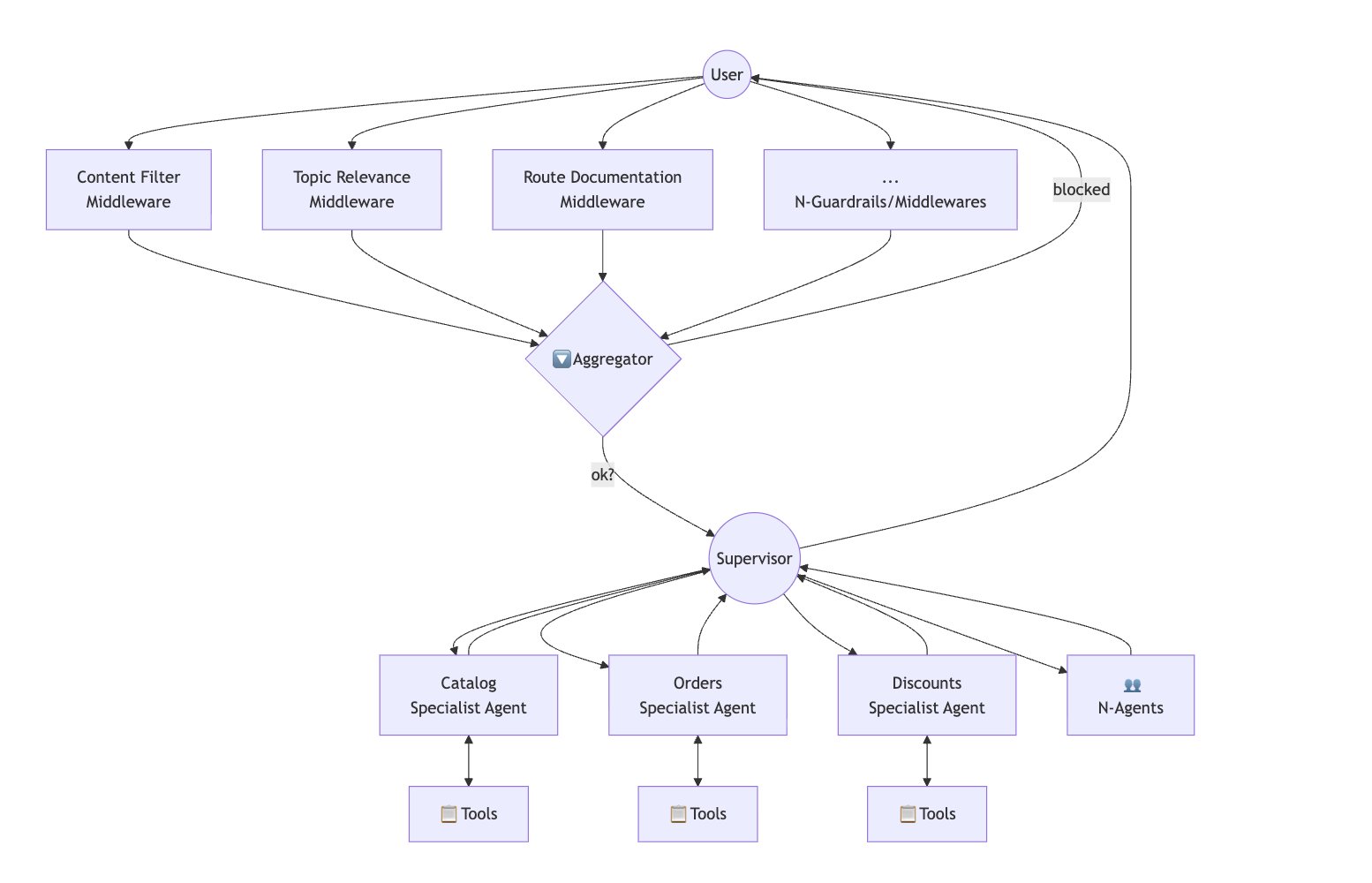
Lumi 的智能体架构
动态挂载子智能体
并不是每个商家拿到的都是同一个 Lumi。某些专家被功能开关(feature flag)挡在后面。我们会逐步放量、跑实验,或者按国家/套餐做限制。与其搭建一张带条件边的巨型图,不如在每次请求时动态地把图构建出来。
大致流程是这样的:
- 从一个基础智能体(主管 + 始终在线的专家)起步。
- 对每个可选专家,针对当前商家检查它的功能开关。
- 如果开关是开的,就挂上该专家节点、它的工具,并把它的提示词片段注入主管的系统提示词(在 langsmith 上使用 mustache 模板)。
- 编译并运行。
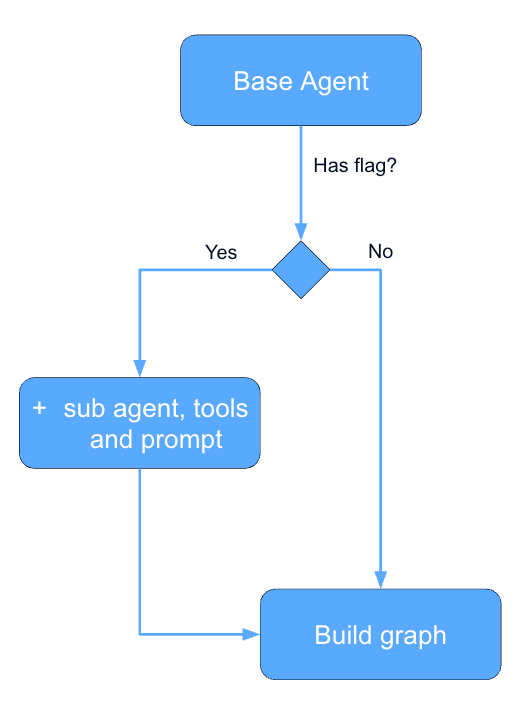
图构建期间动态挂载子智能体/工具
一个很棒的副作用是:主管的提示词永远只会描述那些实际挂载上去的专家。当 X 压根不在图里时,模型绝不会看到”你可以路由到 X”。这既缩小了上下文,又消除了一整类”智能体凭空幻想出一个工具”的故障,还让功能开关的放量在设计层面上就是安全的。
此外,这也让我们能够轻松回滚改动并做 A/B 测试。
扇出 / 扇入中间件
有些请求需要在智能体运行的前后发生一些事,且无论最终是哪个专家来处理这一轮都得照办:输入护栏(guardrail)、PII 检查、上下文增强、输出校验等等。我们把这些实现为环绕主图的一套扇出 / 扇入(fan-out / fan-in)模式。
几个相互独立的中间件(middleware)节点在输入上并行运行,它们的结果被合并回图状态(graph state),随后主管接手。在输出侧,同样的模式再重复一遍。让它们保持并行,意味着新增的延迟接近于最慢那个中间件的耗时,而不是所有中间件耗时之和。
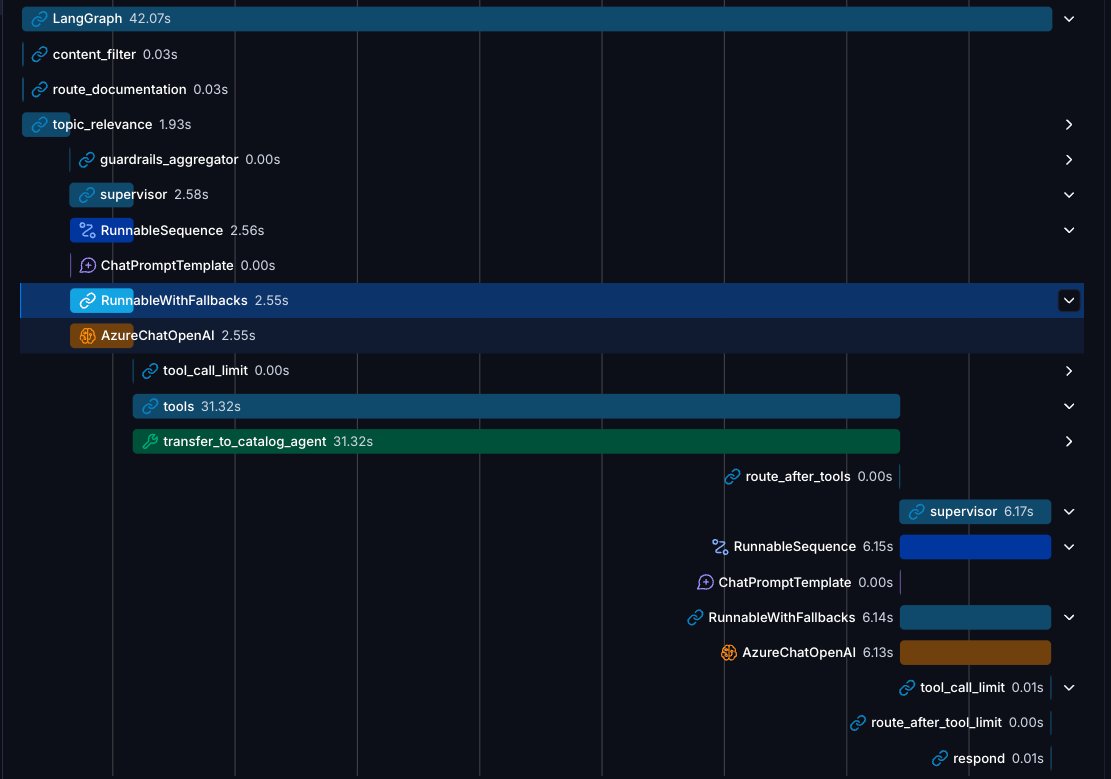
主管优化:直接转发子智能体的回复
默认的主管模式是这样的:主管调用专家 → 专家回复 → 主管读取这份回复、再生成它自己面向用户的消息。这多出来的一跳既耗延迟又费 token,而且主管有时会把专家精心打磨出来的有用细节给改写没了。
对我们的很多专家来说,正确的做法其实更简单:把专家的最后一条消息原封不动地转发给用户。我们在主管里加了一个小步骤,去图状态里搜出子智能体的最后一条消息,并在该专家的契约能保证给出可直接面向用户的回复时,将其直接转发出去。只有当专家的输出是结构化/内部用途、需要再加工措辞时,主管才会再”思考”一次。
优化前:
优化后:
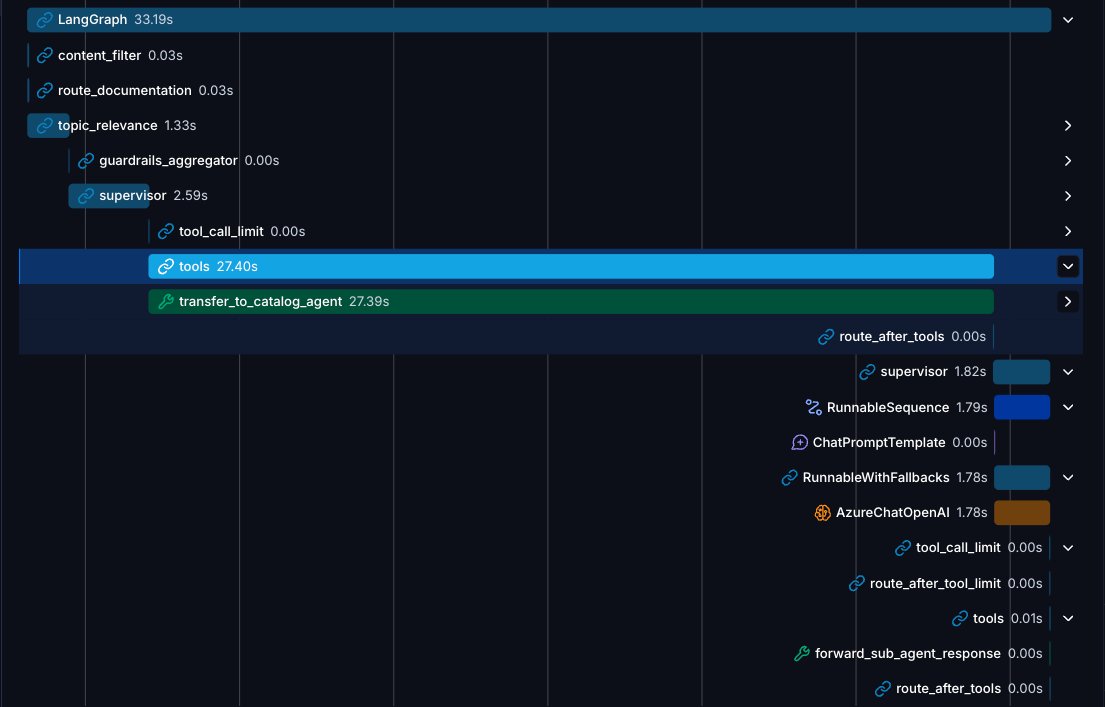
仅这一处改动,就砍掉了相当一部分端到端延迟,并消灭了一整类”主管把我的答案改写得还不如我自己写的”的 bug。
图状态 vs. 运行时上下文
早期那些回报丰厚的建模决策之一,就是刻意去区分什么该放进图状态(graph state)、什么该放进运行时上下文(runtime context)。
图状态(会被检查点(checkpoint)持久化、可重放、由节点改动):
- 消息和对话历史
- 一路上产生的结构化输出
remaining_steps和工具调用计数器(本次运行内的临时数据)- 本次运行护栏产生的结果(本次运行内的临时数据)
运行时上下文(每次请求注入,绝不写入检查点):
- 商家是谁:
store_id、国家、语言、货币 - 他们身处何处、看到了什么:当前后台路由上下文
- 当前日期
- 用户在这一轮里附带的图片
把运行时上下文挡在检查点器(checkpointer)之外,意味着我们绝不会持久化那种”这位商家昨天还在 /products 页面”的过期数据,也意味着每当新增一个请求级字段时,我们都无需去迁移检查点的表结构(schema)。它还让提示词渲染变得轻而易举——每个提示词模板都会被直接喂入运行时上下文,模型也就再不必从对话历史里去猜自己正在跟谁对话。
这里有几篇关于该主题的优秀 Langchain 文档。
检查点与记忆
我们使用 LangGraph 的 Postgres 检查点器来支持人在回路(human-in-the-loop)和时间旅行(time-travel),但只在主管图上用——专家子图是无状态的,会从主管的输入里重建自己的上下文。光是这一个决策,就消掉了每段对话里海量的记录。
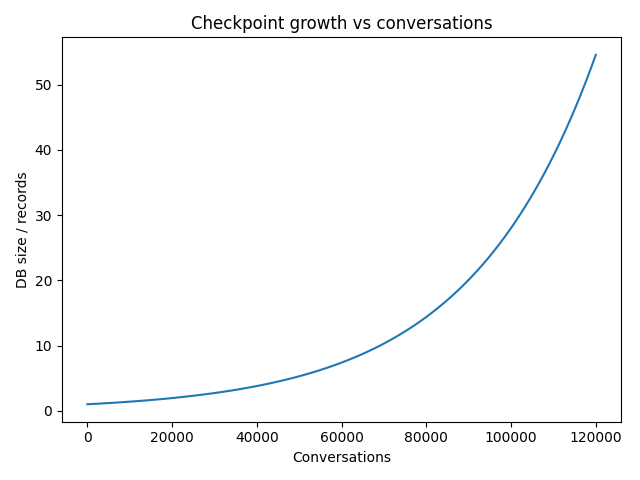
来源:《在生产环境中扩展 LangGraph 的 Postgres 检查点器》(Scaling LangGraph’s Postgres Checkpointer in Production),出自 tadeodonegana.com
故事的另一半,是要决定检查点在过期之后该如何处置。我们跑了一个定时任务(cron job),去识别 Postgres 检查点器里那些陈旧的对话,然后由一个 ETL 流程把这些对话挪到一个 S3 桶里,以清洗过的 JSON 文件形式存储,用于分析。这样一来,业务数据库始终保持精简,而我们又留住了用于数据分析的历史数据。关于其中的细节、表增长的具体数字,以及那些坑,我另写了一篇文章:在生产环境中扩展 LangGraph 的 Postgres 检查点器。
随着检查点器的 Delta Channels 最新版本发布,这套做法已经过时了。但还是把它写在这里,因为这是我们在该版本发布之前找到的一个不错的优化。
评估
为一张多智能体图构建评估(eval),要比为单条提示词构建评估难得多。这里没有单一的”模型输出”可供比对;有的是一个路由决策、一连串工具调用,以及一条取决于前两者的最终消息。
对我们行之有效的做法是:
- 分层逐级评估:主管路由是一个分类问题,用一份由(输入,预期目标专家)配对组成的黄金数据集(golden dataset)来评估。专家质量则用 LLM 评审(LLM-as-a-judge)对照预期输出来评估。
- 把数据集放进仓库里:黄金数据集以 CSV 形式与代码并排存放、纳入版本控制,并带有清晰的分层(商品目录操作、数据分析问题、客服问题、对抗性输入等)。我们在 Langsmith 里也存了一份数据集。
- 每次有意义的提示词改动都跑一遍:提示词的编辑就是代码改动,它们要走 PR,评估则在 CI 里运行。

我们部分 PR CI 流程的示例
我们早期掉进去的陷阱,是试图把整张图当成一个黑盒来做端到端评估。这很诱人,因为它正好对应了用户所看到的东西,但它会让回归(regression)几乎无法被定位。分层评估让我们在出现回归时,能知道究竟是哪一层坏了。
另外,最近我们大量使用了 Langsmith Insights 和 Engine,在发现生产环境问题上效果相当不错——不过那是留给后续博客文章的话题了。
收个尾
LangGraph 以及 LangChain 技术栈的其余部分,给了我们很大的空间,让我们能把那些决策做成有意为之、而非误打误撞。最终的成果,是一套已经扩展起来的系统——它由一支小得出奇的团队支撑,每周为 18 万+ 商家驱动着各种对话。
万分感谢 Tiendanube 的 AI 团队,以及 Alessandro Paolini、Ignacio Luciani、Juan Scavuzzo、Agustin Parraquini、Juan Fernandez Sosa、Claudio Martinez、Karem Carvalho、Joaquin Tornello 和 Ignacio Martin。这里的大部分工作都是和他们一起搭建并交付的。能与这样一支了不起的团队共事,实在是一种荣幸。本文内容深受我和 Alessandro 在 2026 年 4 月 LangChain 布宜诺斯艾利斯社区聚会上所做分享的启发。

2026 年 LangChain 布宜诺斯艾利斯社区聚会上的 Alessandro 和我