
相关分类
越来越多团队开始用 AI 智能体重构大型代码库,但许多团队其实并不清楚它们到底在哪里管用、又会在哪里失灵。在 1Password,我们把智能体工具用在了一个数百万行代码的 Go 单体应用上。这篇文章想分享的是:什么奏效了,什么出问题了,以及这对那些希望在生产系统中落地 AI 的团队意味着什么。
先把背景讲清楚:1Password 在运行一个大型 Go 单体应用,代号 B5。多年来,它一直是我们产品的基石——在可靠性和规模上都表现良好,目前仍稳定运行在生产环境中。
而 Unified Access(1Password 的一条产品线)的定位,是在高请求量和低延迟的前提下,同时支撑人类工作流和智能体驱动的工作流。随着我们不断为它添加和增强能力,系统需要更清晰的服务边界、更独立的伸缩特性。从长远看,这意味着要逐步演进系统的某些部分,同时完整保留我们已经建立起来的隐私、性能、可靠性和安全属性。
要为这个问题拿出一份可落地的方案——这听起来正是智能体的用武之地。
对我们来说,这意味着做”智能体重构”(agentic refactoring):让 AI 智能体在整个代码库范围内分析、规划、执行变更——从依赖关系梳理到系统拆分,全都由它们参与。
这个故事的理想版本大致是这样的:智能体工具分析一份庞大的代码库,输出一份清晰利落的拆分计划,服务拆分从此按部就班地推进下去。
事实上,故事的一部分确实如此展开了。我们构建了一条智能体工具链,分析了数百万行代码,并得到了一个清晰、站得住脚的拆分顺序。这项工作切实改进了我们对系统拆分的思考方式。
不过,真正更有价值的部分,是我们把这些工具应用到线上生产环境的真实变更中之后学到的东西。这部分恰恰是最容易被一笔带过的,也正是决定这种做法是否真的奏效的关键。
搭建分析层
我们要回答的第一个问题是:顺序。在一个需要大规模处理敏感数据的系统里,拆分顺序本身就是一项正确性约束。一旦顺序搞错,就可能引入那些很难被发现、日后又极难挽回的隐性故障。
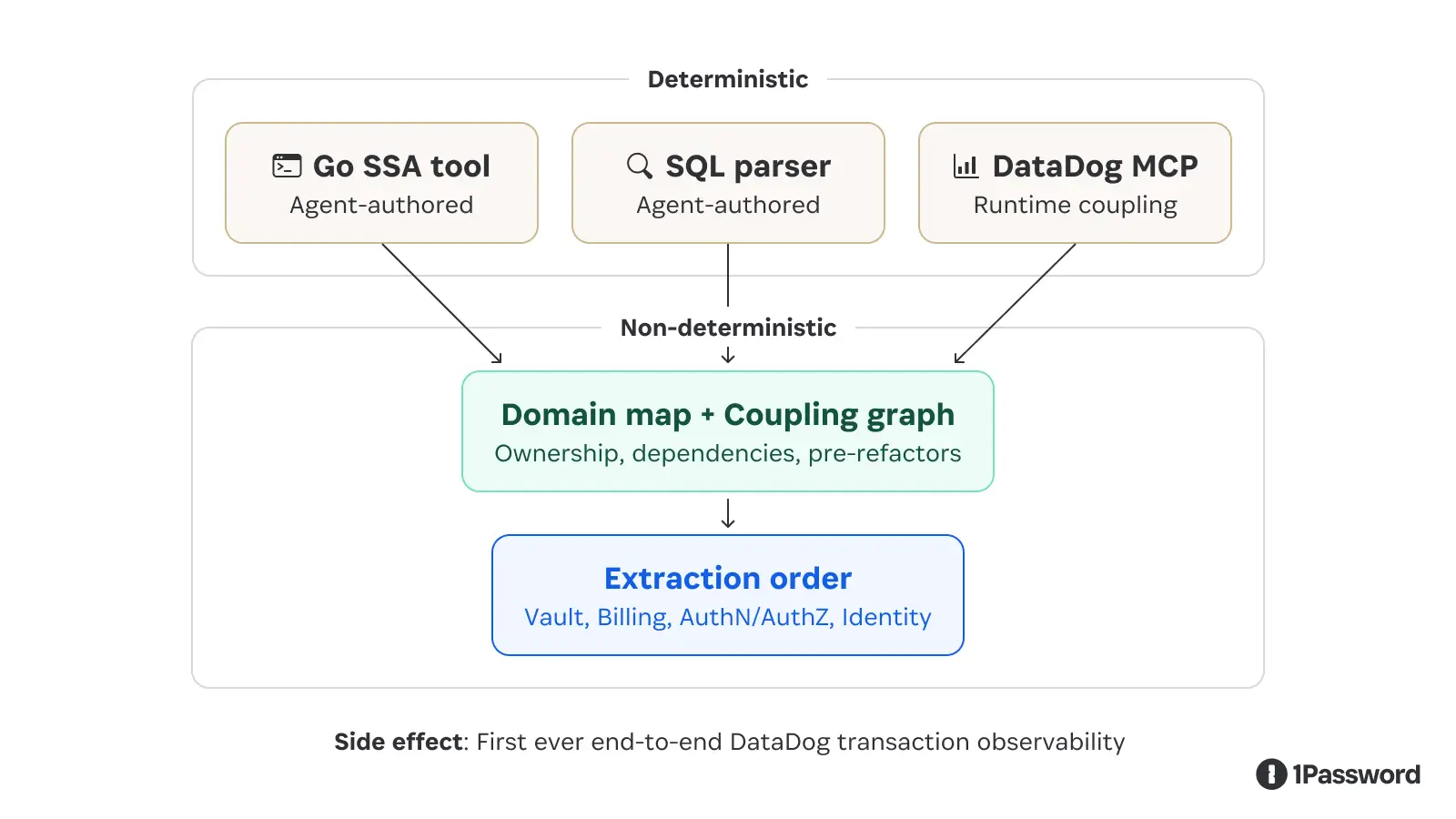
为了让这个问题变得可处理,我们构建了一条智能体工具链,把几种不同的”事实来源”整合到了一起。
我们用 Go SSA(静态单赋值分析,一种编译器常用的代码结构分析技术)来理解代码结构,用 SQL 解析来识别数据依赖,再通过 DataDog MCP 集成引入运行时的耦合数据。三者结合,为我们输出了一张领域归属图、一张耦合关系图,以及一份按优先级排序的拆分顺序。
最终输出的结果,基本上和资深工程师盯着这套系统给出的判断一致:先从 Vault 开始(它有独立的 API、数据集和安全边界),然后是 Billing,再是 AuthN 和 AuthZ,最后让 Identity 作为核心保留下来。
其中有一个模式特别奏效:用智能体去构建确定性工具,而不是反复依赖它们来解读系统。具体到这件事上,智能体帮我们写出了 SSA 分析器的部分代码,而分析器再输出一份可复现的领域图。这个区别很关键——一旦工具做出来了,后续的推理就是建立在一份稳定的产物之上,而不是每次都在争论”模型觉得系统长什么样”。
关键模式
让智能体生产确定性产物,再强制让所有后续执行都受制于这些产物的约束。即使智能体本身不是完全可预测,整个流程也就有了一块稳定的地基。
这项工作还带来了一个意外收获:我们为支持分析而添加的埋点,也顺带提升了 DataDog 中端到端的事务可见性,用处已经超出了这个项目本身。
寻找人与智能体的分工比例
在做拆分分析的同时,我们把同样的方法用在了代码库里一个拖了很久的清理任务上。
我们的 Go 服务器用 MustBegin 启动数据库事务——这个函数在失败时会直接 panic(崩溃)。这种行为在早期是合理的:它能在开发阶段迅速暴露数据库问题。但到了生产规模上,当连接超时或请求上下文被取消时,你其实并不希望它直接崩;此时正确的结果,是返回一个干净的错误。
这次迁移需要改动生产代码和测试代码中 3000 多处调用点——这正是它长期躺在待办清单里的原因。
我们采用的做法高度结构化。先用 SSA 生成一份确定性的调用点清单,把这些调用点归类成少数几种模式,并为每一种模式定义明确的改写模板。在此基础上,我们写了一份详细的操作手册,精确描述智能体应该如何执行这次迁移——其中包括常见的失败模式清单,以及明确的指示:在什么情况下应该停下来上报、而不是自己猜着往下做。为了扩大执行规模,我们用 git worktree(工作树)让多个智能体并行跑起来,确保各自的改动彼此隔离。
执行本身只花了几个小时。大部分时间都花在了构建工具和撰写规范上。
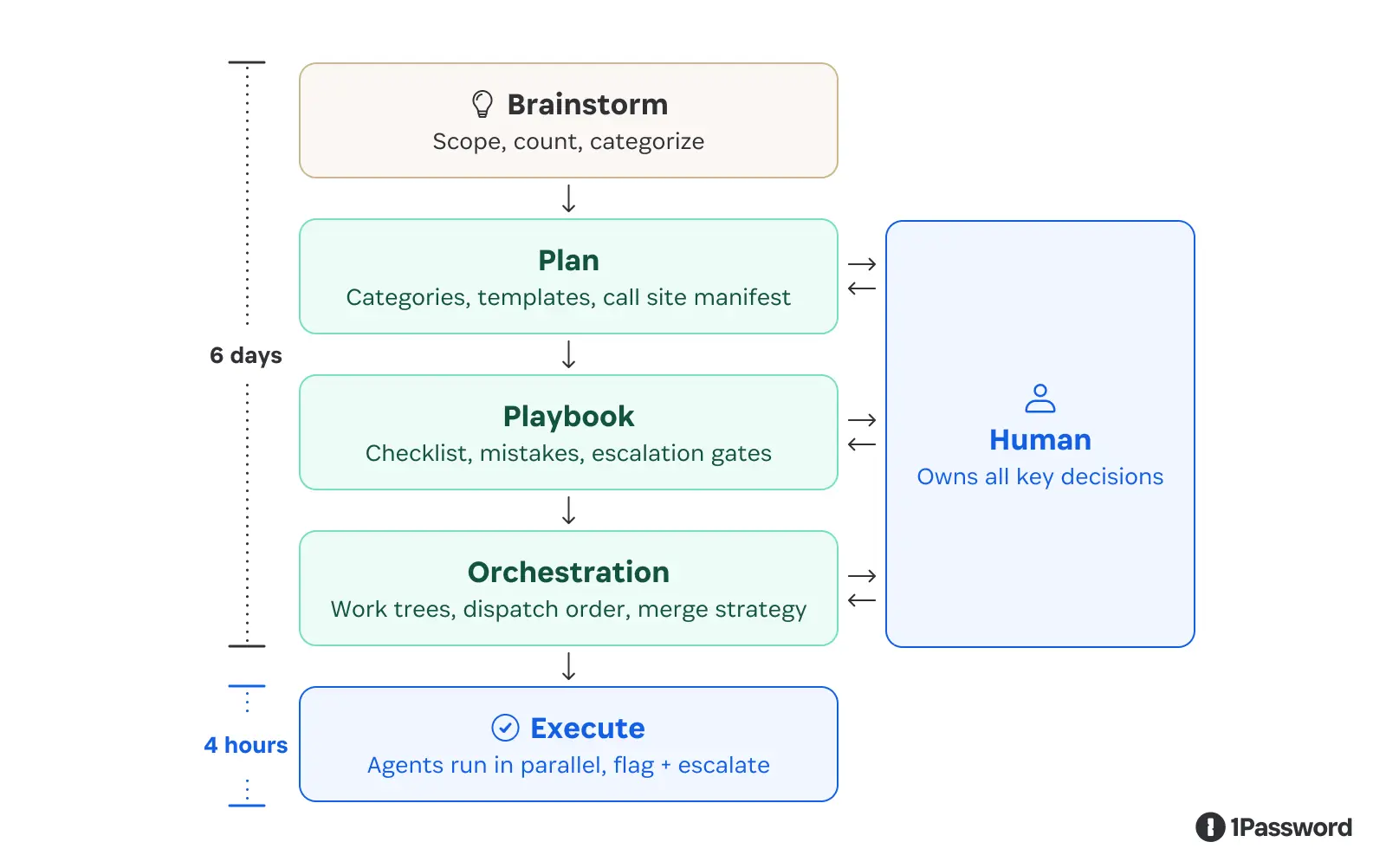
这个”比例”才是关键所在。当任务被完整规范、边界清晰时,智能体既快又准;当它们遇到规范之外的情况时,我们在系统设计上就刻意让它把问题暴露出来,而不是悄悄自己处理掉。
智能体需要更强约束的场景
接下来我们挑战了一个更复杂的任务:把一个服务从单体应用里拆出来。
哪怕是一个相对较小的服务,这类工作也需要在数据库模式演进、读写路径、部署时序、共享数据契约这几个维度上做协调一致的变更。这些决策相互依赖,必须按正确的顺序推进。我们在这个任务上遇到的主要问题,正是和顺序、不变量(invariants)相关。
举个例子:智能体会在更新”负责插入新行的那段代码”之前,就先去回填 UUID 列。这个顺序会带来静默的数据丢失,哪怕底层系统本身设计得再好也救不回来。还有一些情况下,它会把共享表当成新服务独占的数据,这原本会在部署阶段直接引发冲突。就算我们明确给出了关于顺序和约束的指令,这些模式仍然反复出现。
我们还观察到一个反复出现的行为,内部把它称作”臆测”(speculation)。当智能体上下文不足时,它会用看似合理、但其实未经验证的假设去填补空白。有一次,它推断某个标识符格式是 ULID(一种时间有序的唯一标识符),并把这个假设一路带到一连串改动里,最后不得不把整个会话全部回滚。
“真正奏效的模式,是用智能体生产确定性产物,再强制让所有后续执行都受制于这些产物的约束。比如在 Cursor(一款 AI 代码编辑器)里,我们看到很多用户在 Plan Mode(计划模式)下使用更大、更慢的模型(例如 GPT5.4 或 Opus)生成一份具体的 plan.md 文件,按需编辑后,再用更小、更快、且特别擅长写代码的模型(例如 Composer)去真正落地实现。” —— Tido Carriero,Cursor 工程副总裁
对于这一类工作,生产力的提升是实打实的,但没那么夸张。从实践来看,我们看到的增益大约在 20–30% 之间。智能体确实有帮助,但它并没有取代对细致协调和人工审查的需求。
这折射出我们在 1Password 看到的一个更深层的变化。AI 智能体正在成为系统中一类全新的参与者——它们带来了非确定性、持久性和规模,而这些正是传统模型在设计之初从未打算应对的。这不只会影响工程工作流,也会影响跨系统的访问与信任该如何管理。
给使用 AI 智能体写代码的团队的几条教训
从 1Password 的这次实践里,其他团队可以总结出不少教训,它们的适用范围也远不止这个具体案例。
教训一:智能体重构的瓶颈不在代码生成
智能体在阅读代码、分析结构、起草改动方面非常高效。真正变难的,是管理那些带有顺序约束、或者一旦做了就难以撤回的决策序列。典型的例子包括数据库模式变更、部署时序、共享状态的边界划分。这些环节一旦处理不好,不管智能体生成的代码多么干净漂亮,系统照样会崩。
教训二:非确定性必须被小心地圈起来
语言模型是非确定性的——这正是它们有用的部分原因。但在生产迁移的语境下,这种波动性就变成了风险的源头。对我们有效的模式是:让智能体去构建确定性的工具(比如分析器和清单文件),然后约束后续工作必须基于这些工具的输出进行。这样即使智能体本身不是完全可预测,整个流程也就有了一块稳定的地基。
教训三:不完整的规范,会催生出隐式的规范
当智能体缺乏足够上下文时,它会去填补空白,而且经常是以”局部合理、全局错误”的方式。解决这个问题唯一可靠的办法,是把规范写得足够显式——包含不变量、顺序约束,以及针对所有”落在已定义模式之外”的情况的清晰上报路径。
另一个重要的心态转变,是关于”覆盖率”的思考方式。目标不是让智能体处理所有可能的情况。真正的目标是:让它在被充分理解的模式上自信地执行,在遇到歧义时迅速上报。这就要求我们必须有意识地去划定:自动化的边界在哪里、人工判断从哪里接手。
教训四:并行执行只有在”隔离问题已经解决”时才真的有效
同时跑多个智能体确实可能非常高效——但前提是改动之间彼此独立,并且结构上已经消除了冲突。否则,你不是在缩短执行时间,而是扩大了出现不一致的风险面。
这如何影响 1Password 的智能体策略
我们正在整个工程组织内推广智能体工具,同时对”它能在哪里真正放大我们的杠杆”有清晰的认识。
我们知道,智能体在问题得到充分规范时最有效,而确定性工具恰恰提供了让”充分规范”得以成立的那层约束。工程师依然需要负责定义系统边界、建模依赖关系,并确保顺序正确。
这些洞察会帮助我们重新思考交给工程师的工作性质——真正最高杠杆的活动,不是写代码,也不是给模型写提示词,而是以一种可以安全、可预测地执行的方式去定义系统。
我们眼下在处理的问题——包括在线上流量下拆分生产系统、组织多智能体协同执行——都还没有成熟的操作手册。我们正在边做边写这些手册,而这也正是当前最有意思的工程工作发生的地方。
如果你也喜欢琢磨这类问题,我们正在招人。