核心思想
大多数团队不是”造”harness,而是 import 一整块框架(LangChain、CrewAI……),不合用就只能 fork、硬刚或绕开。作者主张把 harness 拆成一组跑在同一引擎总线上、靠单一
iii.trigger()原语连接、各自独立版本化、可随手替换的 worker:模型路由、凭据、策略、审批、预算、压缩……每一层都能用”注册相同 function id 的新 worker”来替换。于是”自己造 harness”从”fork 框架”退化成”换几个 worker”,“轻 vs 重”也从非此即彼的岔路口,变成一根靠增删 worker 滑动的滑块。

绝大多数 agent 团队并不”打造”harness,而是直接”采纳”一个现成的。LangChain、LangGraph、OpenAI Agents SDK、Anthropic SDK、CrewAI、AutoGen——循环、工具、记忆、编排,统统作为同一个决策被一次性选定。harness 就是你 import 进来的一个框架。一旦里头有哪个部件不合用,**你要么 fork 它,要么硬刚它,要么绕开它。**

我认为这种形态是错的,而且这正是每一个长期运营的 agent 团队最终都不得不从头重写自己 harness 的根源。harness 根本不是一个东西。它是十个、十二个不同的东西被捆在一起——之所以被捆,是因为周遭的生态根本没给你一条把它们组合起来的路子。Pi agent 的包(packages)方向是对的,但它们仍然没跳出”再加一个服务,然后把它跟其他所有服务集成起来”的范式。iii 引擎对所有 worker 一视同仁,把集成逻辑彻底抹掉了。模型提供方路由、凭据保管库、策略引擎、审批门、模型目录、会话存储、预算追踪器、调用后的钩子扇出,以及那个持久化的 turn 循环——它们是彼此独立的关注点。这些东西全都能跟你的队列、http/api 服务器、流式传输、乃至浏览器 worker 互操作。一个把它们当作一整块出货的框架,是在向你兜售一个你本不必接受的取舍。
iii 底层下的那个赌注是:它们就不该是一整块。应该有一组跑在同一个共享引擎上的 worker,每一个都可替换、每一个都独立版本化、每一个都靠同一个 primitive 连接起来:一个 trigger(iii.trigger(),即触发器)——其他每一个 worker 也都在用它。于是 harness 变成了一摞可安装的 worker,而”自己造(build your own)“也就不再意味着”fork 一个框架”,它意味着”换掉几个 worker”。
这篇文章会带你看清这件事到底长什么样:今天驱动一次 iii agent 轮(turn)的那套完整 stack、为什么每一层都自成一个 worker,以及你要怎么替换其中任意一个。
agent harness 必须干的 15 件事
如果你把一个生产级的 agent harness 剥到只剩职责,你会得到一份大致如下的清单:
- 从客户端接收一个 turn 请求并把它持久化
- 为即将被调用的那个模型提供方解析出凭据
- 查清楚被选中的模型实际能干什么(视觉、工具、流式、上下文窗口)
- 驱动每轮的状态机:开机置备、流式输出 assistant、跑工具、引导(steer)、拆机收尾
- 加载并供给技能正文(skill bodies),它描述了每个函数的请求形态、错误码和用法说明
- 拼装系统提示词:模式段落、身份开场白、工作目录、默认技能附录
- 在模型逐字产出 token 的同时把它们流式推回客户端
- 在每次工具调用(无非就是一个函数)真正执行前,拿它去过一遍策略检查
- 把需要人类裁决的工具调用挂起,并把答复路由回正确的那一轮
- 对照每个工作区或每个 agent 的预算,追踪 LLM 花销
- 在工具调用前后跑钩子(日志、脱敏、自定义副作用)
- 把会话持久化成一棵分叉树,好让分支和恢复都能跑通
- 当上下文窗口被填满时,压缩会话历史
- 发出一条事件流,供 UI 订阅
- 这是我见过的每一家做 agent 的公司都缺的一块:把同一条 OpenTelemetry trace 贯穿每一个步骤,好让你能调试它
每一个像样的 harness 都会把上面大半件事 harness 起来。烧钱的那些会全做。抠门的那些会偷工减料,等撞上生产环境再回头把偷掉的料补上。框架则把它们打包成一个单体,并且每一件事只出一个版本。最后这一点正是会让你付出代价的地方——因为入坑一年后你会发现,你想要的策略引擎并不是框架出货的那个策略引擎,而要换掉它,就意味着要换掉整个 harness。
iii 的 harness 把这十三件事中的每一件都作为一个独立的 worker,发布在 workers.iii.dev 注册表上。每一个都说同一套 WebSocket 协议。每一个都在同一个引擎总线上注册自己的函数和 trigger。每一个都能 iii worker add 进来、随手换掉,并且能用任何带 SDK 的语言写出来。
逐 worker 拆解这套 stack
下面就是 iii-hq/workers monorepo 里那套真实的生产 stack,每个 worker 的职责用一行说清。整个包发布在 github.com/iii-hq/workers/harness:
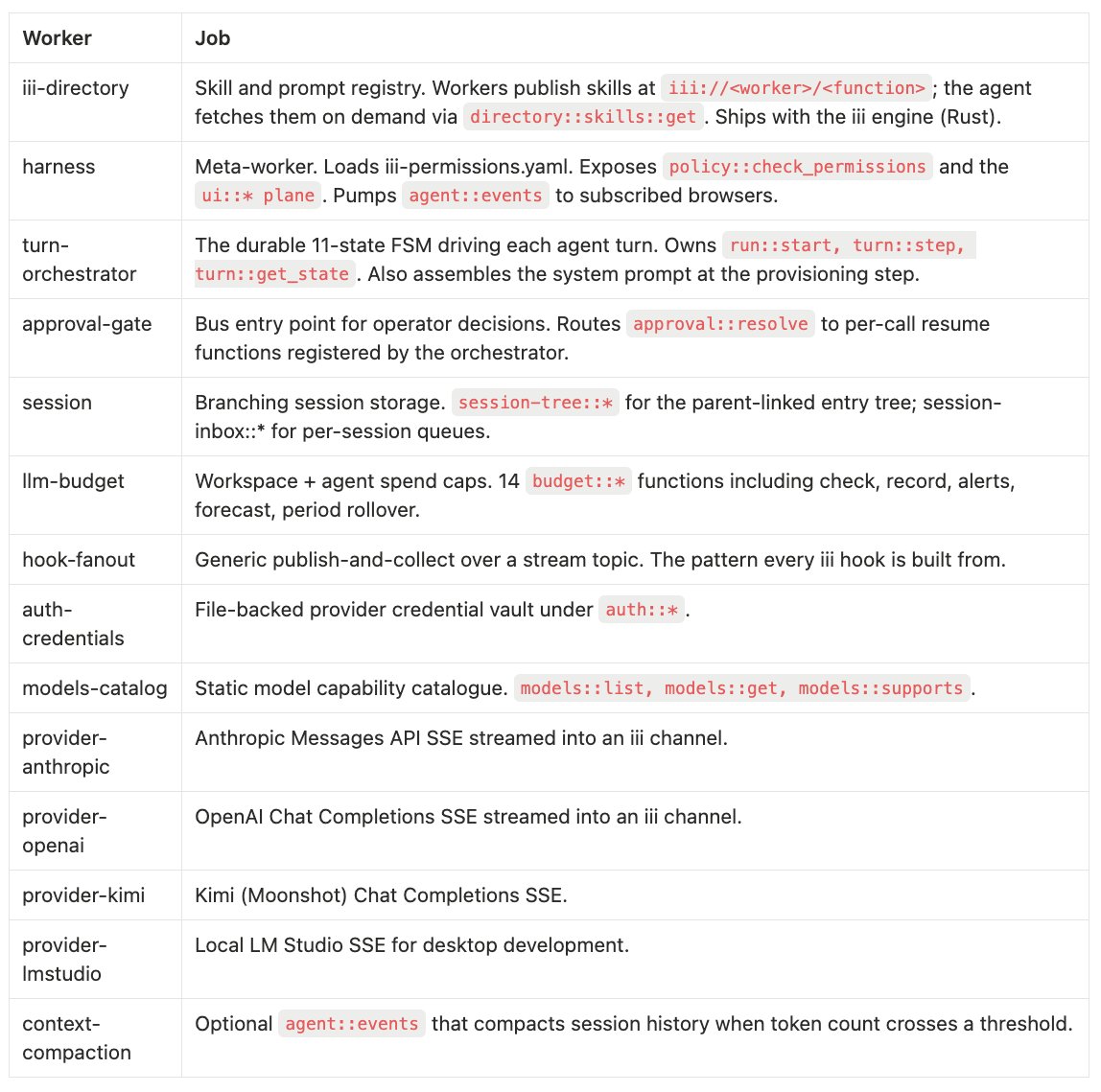
十一个 worker。一个引擎。每一个都挂在某个已发布的版本上。每一个都能作为独立进程单独跑起来(开发时 pnpm dev:<worker>,发布时则是 iii worker add <specific-worker> 这个发行版二进制),也能作为那个把它们一起拉起来的复合入口点的一部分跑。
这件事之所以要紧,是因为那张表里的每一个格子,都是别人能塞给你一个不同 worker、而你照样留着其余部分的地方。不喜欢静态的模型目录?插进来一个注册了 models::list、改从一个实时 API 读取的 worker。不喜欢文件托底的凭据?插进来一个注册了 auth::get_token、改从某个密钥管理器读取的 worker。想给一个分叉方式不一样的工作流换一套不同的 turn 状态机?把 turn-orchestrator 替换掉就行——每一个依赖方都是通过同一条总线去调 run::start、去读 turn_state,所以 stack 的其余部分纹丝不动。
这个循环到底是怎么跑起来的
一次 turn 的形态大致如下,我们按各个 worker 触发的先后顺序走一遍。
一个 browser/cli/chat 通过 harness::trigger 用 {session_id, message_id, payload} POST 进一个 turn。harness 这个元 worker(meta-worker)把 payload 转发给 run::start。这一跳之所以存在,是为了让 OpenTelemetry 的 span 包装器能把 session 和 message ID 作为 baggage 种进去——它会传播到整个 stack 里每一个 worker、每一次嵌套的 iii.trigger 调用。于是另一头的 trace 树就是一张连通的图。
run::start 落在 turn-orchestrator 上。它把这个 run 请求持久化,在 iii state 的 session/<sid>/turn_state 处种下初始的 TurnStateRecord,然后立刻返回。真正的活儿发生在那个持久化的、按状态推进的状态机里,由向 turn-step 这条 FIFO 的发布动作唤醒。
两个终止状态分别是 stopped(经由 finishSession() 干净退出)和 failed(一个意料之外的 handler 抛错会路由到这里,它会 ack 掉队列让它别再重试,并浮出 message_complete{stop_reason:‘error’} 外加 agent_end,好让 UI 把原因显示出来)。拆机收尾是一个内联的 finishSession() 端口,从任何”轮结束”的路径上调用,而不是一个单独入队的步骤。
provisioning 干三件事。如果这次 run 需要隔离执行,它会启动一个 iii-sandbox microVM。它会为 system_default_skills(默认是 [“iii://iii-directory/index”])里的每一个命名空间调用 directory::skills::download,好让 iii-directory 把这次 run 一开始就要用到的技能正文预先缓存好。它还会分三层把系统提示词拼起来:一段从 run_request.mode(plan、ask 或 agent)里挑出的模式段落、一段 iii 身份开场白(它教会模型 agent_trigger 这一约定以及 directory::skills::get 这种按需发现的模式),再附上一份这个 agent 启动时自带的默认技能索引。调用方可以通过在 run::start 上传入 system_prompt 来覆盖整段提示词;否则就由编排器来构建。函数的 schema 则来自实时的引擎目录。
assistant_streaming 会在与本次 run 的 provider 字段相匹配的那个提供方 worker 上调用 provider::<name>::stream。提供方 worker 通过 auth::get_token(auth-credentials)把凭据拉过来,把模型的 SSE 响应流式灌进一个 iii channel,编排器则把那个 channel 抽干,在 agent::events 上发出 message_update 事件供 UI 扇出。channel 的创建和那个读取循环都藏在 provider-stream.ts 里一个基于拉取(pull-based)的 MessagePump 背后,这样流式状态本身就能专注于状态转换。
当 assistant 返回工具调用时,状态机进入 function_execute。每一次工具调用都要穿过 dispatchWithHook——编排器里唯一的那个咽喉点。consultBefore 会以 5 秒超时直接调用 policy::check_permissions。策略 worker(在默认 stack 里就是 harness 这个元 worker)读取 iii-permissions.yaml,拿这次调用的 function_id 去跟规则集匹配,返回三种结果之一:
- allow(放行): 派发继续;编排器触发目标函数并写入结果
- deny(拒绝): 派发短路,返回一个 DenialEnvelope,结果变成一条拒绝记录
- needs_approval(需审批): 这一个调用被泊入本轮的 awaiting_approval 列表。批次里其余的调用照常派发。只有当一条或多条进入待决状态时,这一轮才会转入 function_awaiting_approval。
审批的唤醒是响应式的、也是共享的。编排器只在 approvals 这个 scope 上注册了恰好一个 turn::on_approval state trigger。当控制台调用 approval::resolve 时,审批门 worker 会把 approvals/<sid>/<cid> = {decision, reason} 写进 iii state。那次写入触发 turn::on_approval,于是受影响的会话被推进。function_awaiting_approval 只读取刚刚落地的那些裁决,每来一个就派发一个(allow 变成一次预批准的派发,deny 或 aborted 变成一条合成的拒绝记录),等到 awaiting_approval[] 为空就推进。无需为每个调用注册恢复函数。无需在启动时重新扫描来恢复待决的审批。一个 trigger 覆盖每一个会话。
它在构造上就是”失败即关闭(fail-closed)“的:如果策略 worker 不可达,或者那个 5 秒超时被触发,consultBefore 就会用一个 gate_unavailable 信封拒掉这次调用。如果 iii::durable::publish 本身报错了,钩子扇出会返回 publish_failed: true,编排器就把它当作一次 deny 来处理。
从这个形态里还顺带掉出来几个延迟上的胜仗。当某个主题压根没有持久订阅者注册时,调用函数后的钩子会经由一个”订阅者在场”缓存把 publish_collect 短路掉,每一次被执行的函数调用因此省下大约 500ms。tearing_down 被内联进了 finishSession(),每一轮因此省掉一次持久队列的跳转。context-compaction 订阅的是编排器在轮边界处发出的一条专用 agent::turn_end 流,于是压缩器的唤醒是按轮(per-turn)而非按事件(per-event)。会话创建的扇出 state trigger 仅按 scope 来设门、并在进程内匹配,于是先前那个按每次写入触发的 harness::session::is_create_event RPC 也没了。
批次跑完后,steering_check 决定是继续、停止,还是撞上 max_turns。若继续,就绕回 assistant_streaming。若停止或到顶,finishSession() 就内联跑起来:发出 agent_end、释放沙箱、转入 stopped。
整个 run 自始至终,每一个参与的 worker 都会发出带有 iii.session.id、iii.message.id 和 iii.function.id 标签的 OTel span。正是这些标签,被引擎的 engine::traces::group_by 读取,用来在 traces UI 里填充”按会话分组(Group by Session)”/“按消息分组(Group by Message)”/“按函数分组(Group by Function)“。这套埋点是自动的:src/runtime/worker.ts 用一个 Proxy 把每一个 registerFunction 包了起来,所以没有哪个 worker 的代码需要记着去加 span。
自己造
有意思的地方在于,上面那些 worker 没有一个是”特殊”的。每一个都是这样一个进程:它向引擎开一个 WebSocket,注册若干函数和 trigger,然后跑起来。这份契约,和每一个应用 worker 用的那份契约一模一样。harness 就建在你的业务逻辑所依赖的那同一个 primitive 之上。
这意味着”自己造一个 harness”被分解成了和”写任意一个 worker”完全相同的操作。你挑出想替换的那一层,写一个在总线上注册了相同函数的 worker,把它 iii worker add 进来,stack 的其余部分就开始用你的 worker 了。
有两层并没出现在上面那张 worker 表里,但它们对 harness 的行为很关键。**技能(Skills)**是每个 worker 用来宣告自己那些函数都能干什么的方式。每个 worker 都能在 iii://<worker>/<function> 处发布一份技能,agent 会在头一次调用那个函数之前通过 directory::skills::get 把它取过来。系统提示词则是每一轮现拼出来的,由一段模式段落、那段 iii 身份开场白,以及这次 run 被配置上的那些默认技能正文组成。两者都是总线驱动的:技能由 iii-directory worker 来供给,系统提示词由 turn-orchestrator 来拼装。两者都可替换。
五个具体的例子。
用一个实时 API 替换掉模型目录。 写一个注册了 models::list、models::get、models::supports 的 worker。让它每隔 N 分钟从你提供方的目录端点抓一次并缓存。发布它。iii worker add your-org/dynamic-models-catalog。把静态的 models-catalog worker 停掉。turn-orchestrator 压根察觉不到任何区别。它调的是 iii.trigger(‘models::list’),而引擎会路由到最近注册了那个 function id 的那个 worker。
加一个新的提供方。 它的形态,provider-kimi 和 provider-lmstudio 早已验证过了。每一个都是这样一个 worker:注册 provider::<name>::stream 和 provider::<name>::complete,把上游 API 的一条 SSE 流抽进一个 iii channel,并通过 budget::record 把它的模型用量写进 llm-budget。加第五个提供方,就是写一个文件夹,里头一个 iii.worker.yaml、一个 register.ts。发布到注册表,或者就留在本地。turn-orchestrator 按本次 run 的 provider 字段挑提供方;新提供方在那个 worker 一连上的瞬间就可用了。
从一个私有制品库供给技能。 写一个注册了 directory::skills::get 和 directory::skills::list 的 worker,背后接你内部的文档系统或一个私有 S3 桶。把默认的 iii-directory worker 断开或改名。编排器的引导阶段会按命名空间调 directory::skills::download;由你的 worker 来应答。agent 那套”调用一个新函数前先去取它对应的按函数技能”的模式照样原封不动地跑,因为线上形态(wire shape,即数据在总线上传输时的形态)是一样的。
彻底覆盖系统提示词。 run::start 接受一个可选的 system_prompt 字段。把它传进去,编排器就会一字不差地用你那段字符串,跳过”模式段落 + 身份开场白 + 技能附录”那一整套拼装。当你有一份现成的提示词资产、想让 harness 不加改动地尊重它时,这就很有用。技能下载在引导阶段照样会跑,所以哪怕用的是自定义提示词,agent 也仍然保有 directory::skills::get 那套按需发现的能力。
替换审批门的 UI 触面。 默认的 approval-gate worker 注册了 approval::resolve。它的线上 schema 就是一次函数调用:
iii.trigger('approval::resolve', {
session_id: '...',
function_call_id: '...',
decision: 'allow' | 'deny' | 'aborted',
reason: 'optional human text',
})这个 handler 把 approvals/<sid>/<cid> = {decision, reason} 持久化进 iii state。编排器那个唯一的 turn::on_approval state trigger 会拾起那次写入并唤醒正确的会话。如果你想改从 Slack 而不是控制台来驱动审批,就写一个 Slack worker,让它监听 /approve <id> 和 /deny <id> 这两个斜杠命令,然后用对应的 payload 去调 approval::resolve。编排器压根察觉不到任何区别。整个 approval-gate worker 一点没动。你是加了一个新 worker,而不是替换掉那个现成的。
如果你想要一个不一样的策略引擎(OPA、Cedar,或你自己的 DSL),就写一个注册了 policy::check_permissions、返回 { decision, rule_id?, matched_constraint? } 的 worker。把默认的策略 worker 断开(它是裹在 harness 元 worker 里头的,所以你得禁用那个 handler,或者跑一个精简版的元 worker)。编排器的 consultBefore 察觉不到任何区别。同样的 5 秒超时、同样的”失败即关闭”语义、同样的线上形态。
这些例子的要点不在于具体替换了什么,而在于这个操作的形态。iii stack 里的每一层 harness,都能通过总线上的一两个 function id 触及。替换一层,就是写一个注册了那些 id 的 worker。系统的其余部分原地不动。
harness 是一个滑块,而不是岔路口
那场经典的 harness 之争,把自己框成了”轻 vs 重”。Anthropic 那个轻量循环,对垒 LangGraph 那张显式的 DAG。这种框法假定你得选边站、然后认命。
而当 harness 是由跑在同一条总线上的 worker 组成时,轻 vs 重就只是”你装了多少个 worker”的一个计数而已。一个轻 harness 就是 turn-orchestrator 加 provider-anthropic 加 auth-credentials 再加一个最小的 harness 元 worker。就这些。没有审批、没有预算、没有策略引擎、没有钩子扇出。什么都能跑。信任模型。适合自主研究型 agent、实验性循环,以及任何内部用途。
一个重 harness 则是全部十三个 worker,再加上 context-compaction、加一个自定义策略 worker、加一个自定义 approval-gate、加一个 Slack 集成的审批触面,再加上那个强制执行各工作区上限的预算 worker。适合那种跑客户工作流的 agent——每一次工具调用都得可审计、每一笔模型花销都得汇总到一块财务看板上。
轻与重之间的架构距离,不是一次重写,而是一次配置变更。同样的线上协议、同样的 trace 形态、同样的可观测性叙事。这个滑块,靠在你的 config.yaml 里增删 worker 来移动。其余的一切都稳稳不动。
它在单个 worker 内部同样成立。turn-orchestrator 刚刚发布了一次重构,把它的状态机从十一个状态压成了七个,删掉了那个按调用走的 turn::approval_resume::<sid>/<cid> 机制、改成在 approvals 这个 scope 上挂一个响应式的 turn::on_approval state trigger,并把 tearing_down 内联进了一个 finishSession() 端口。stack 里其他每一个 worker(approval-gate、session、llm-budget、各提供方、models-catalog、auth-credentials、hook-fanout、context-compaction)全都纹丝没动。approval::resolve 的线上形态没挪窝。各项契约都扛住了。这就是”组合”赋予你的那个性质:对某一个 worker 做一次大的内部重写,是一次自成一体的变更——因为它的每一个邻居都是通过总线级的 function id 跟它对话的。
这正是框架模型给不了你的部分。框架替你在滑块上选了个位置,然后把你锁死在那儿。而 worker 模型,把滑块留在你自己手里。
这在实践中意味着什么
如果你一直在某个框架之上跑 agent,并且正感受着大多数团队在规模化时都会撞上的那些边界问题,那么答案多半不是”用我们自己的框架把 harness 重写一遍”。策略引擎没法按你需要的方式去扩展。审批 UI 被焊死在框架的聊天触面里。凭据存储没法跟你的密钥管理器对话。预算追踪器待在一个 trace 看不见的边车(sidecar)数据库里。答案是:换到一个 harness 从一开始就被拆解开来的底座(substrate)上去。
要最快地体会到这个论点,就去 clone github.com/iii-hq/workers,pnpm install、pnpm build,然后跑那个复合入口点。你会得到一整套十四个 worker 的 harness,指向一个 iii 引擎。把某个 worker 从启动清单里删掉,就能禁用它。写一个注册了相同 function id 的替代品,就能换掉任意一个 worker。给某个 worker 的钩子主题加一个订阅者,就能扩展它。hook-fanout::publish_collect 就是每一个 iii 钩子赖以构建的那个通用件。
文档在 iii.dev/docs。引擎在 github.com/iii-hq/iii。worker 注册表在 workers.iii.dev。harness 包在 github.com/iii-hq/workers/harness。
这个赌注
harness 不是一个你装上去的东西。harness 是一组你的系统必须替 agent 完成的活儿——好让 agent 能持久、安全、可观测地跑起来。框架那个时代之所以把这些活儿捆在一起,是因为底下没有任何东西给过你一条把它们组合起来的路子。
iii 的赌注是:有这么一个 primitive——一个 worker,它通过 WebSocket 连上引擎,注册函数和 trigger——它小到足以把上面那一件件活儿分别吸收进去,而且最终得到的这套 stack 比任何框架都更有用,因为每一层都可独立替换。
你不是去”采纳”iii 的 harness。你是去装上你想要的那些 worker、写出你需要的那些,最终得到一个形状恰好贴合你系统的 harness。每一层都是同一套协议。每一次调用都贯穿着同一条 trace。无论是你从注册表里拿来的部件,还是你自己发布的部件,用的都是同一句 iii worker add。
当底座的形状是对的,“自己造一个 agent harness”就是这副模样。挑出那些 worker。把缺的那些写出来。组合起来。**harness 即组合。**
来和我们一起,打造这个现代世界所需要的那个完美 agent harness:discord.gg/iiidev
iii 是开源的。从 iii.dev/docs 开始上手。harness 的各个 worker 在 github.com/iii-hq/workers,引擎在 github.com/iii-hq/iii。
—— Mike Piccolo,创始人兼 CEO @iiidevs
相关笔记
- 解剖智能体Harness —— harness 由哪些组件构成,与本文”15 件事”清单互为表里
- Harness 工程:智能体时代真正的护城河 —— harness 为何是智能体时代真正的护城河
- 面向长时间应用开发的编排框架设计 —— 另一种 agent 编排框架的设计取舍
- 扩展托管智能体:将大脑与双手分离 —— 把”大脑”与”双手”分离的 agent 架构思路