核心思想
在大型代码库里用好 Claude Code,决定性因素不是模型,而是围绕模型搭建的 Harness——它由 CLAUDE.md、Hook、Skill、插件、MCP 服务器五个扩展点,加上 LSP 集成与子智能体构成,且各层有严格的构建顺序。文章给出三种反复出现的成功配置模式:让代码库对 Claude 可导航(精简分层的 CLAUDE.md、在子目录而非根目录初始化、按目录限定测试命令、用 LSP 按符号搜索)、随模型演进主动维护配置(每 3–6 个月审查一次)、为 Claude Code 的管理与采纳分配明确所有权(一名 DRI 或新兴的「智能体管理者」角色)。
Claude Code 已经在各种生产环境中运行:数百万行的 monorepo、有着数十年历史的遗留系统、横跨数十个仓库的分布式架构,以及拥有数千名开发者的组织。这些环境带来的挑战,是更小、更简单的代码库所没有的——可能是每个子目录的构建命令都不一样,也可能是遗留代码散落在一堆没有共同根目录的文件夹里。
本文梳理我们观察到的一系列模式,正是这些模式让 Claude Code 在大规模场景下被成功采纳。我们说”大型代码库”,指的是涵盖范围很广的一类部署:数百万行的 monorepo、历经数十年构建的遗留系统、分散在多个独立仓库中的数十个微服务,或者上述情况的任意组合。它还包括用一些语言构建的代码库——这些语言团队通常不会和 AI 编码工具联系在一起,比如 C、C++、C#、Java、PHP。(在这些场景下,Claude Code 的表现往往超出大多数团队的预期,尤其是在近期的模型发布之后。)每个大型代码库的部署,都被它特定的版本控制、团队结构和长期积累的约定所塑造,但本文这些模式可以跨场景通用,对于正在考虑采纳 Claude Code 的团队来说是一个不错的起点。
Claude Code 如何在大型代码库中导航
Claude Code 导航代码库的方式,和一名软件工程师一样:遍历文件系统、读取文件、用 grep 精确找到自己需要的东西,并沿着引用关系在代码库中跳转。它在开发者本地机器上运行,不需要构建、维护代码库索引,也不需要把索引上传到服务器。
由 RAG 驱动的 AI 编码工具,其工作方式是把整个代码库做嵌入,在查询时检索出相关片段。到了大规模场景,这类系统会失效,因为嵌入流水线跟不上活跃的工程团队。等到开发者去查询索引时,它反映的已经是几周前、几天前、甚至几小时前的代码库状态。于是检索会返回一个团队两周前就已经重命名的函数,或者引用一个上个迭代就被删掉的模块,而且毫无迹象表明它们已经过时。
智能体式搜索避开了这些失效模式。当成千上万名工程师不断提交新代码时,没有嵌入流水线、也没有中心化索引需要维护。每个开发者的实例都基于实时的代码库工作。
但这种方式有一个取舍:它在 Claude 拥有足够起始上下文、知道该去哪儿找时效果最好。这意味着 Claude 导航的质量,取决于代码库被设置得有多好——用 CLAUDE.md 文件和 Skill 一层层叠加上下文。如果你让它在一个十亿行的代码库里找出某个模糊模式的所有出现位置,那么工作还没开始,你就会撞上上下文窗口的上限。在代码库设置上投入的团队,会得到更好的结果。
Harness 和模型同等重要
关于 Claude Code,最常见的误解之一是:它的能力完全由所用的模型决定。团队往往把注意力放在模型的基准测试分数上,以及它在测试任务上的表现。但实际上,围绕模型构建的那套生态——也就是 Harness——比模型本身更能决定 Claude Code 的表现。
Harness 由五个扩展点构成——CLAUDE.md 文件、Hook、Skill、插件和 MCP 服务器——每一个各自承担不同的职能。团队构建它们的顺序很重要,因为每一层都建立在前一层之上。另外两项能力——LSP 集成和子智能体——让整套配置更加完整。下面我们逐一说明这些组件和能力的作用:
CLAUDE.md 文件排在第一位。它们是上下文文件,Claude 在每个会话开始时会自动读取:根目录文件提供全局视图,子目录文件描述局部约定。它们为 Claude 提供做好任何工作所需的代码库知识。由于它们无论任务是什么都会加载,因此让它们聚焦于广泛适用的内容,可以避免它们拖慢性能。
Hook 让整套配置能够自我改进。大多数团队把 Hook 看作阻止 Claude 做错事的脚本,但它们更有价值的用途是持续改进。一个 stop Hook 可以在会话结束时回顾这次会话发生了什么,并趁上下文还新鲜时提出对 CLAUDE.md 的更新建议。一个 start Hook 可以动态加载团队专属的上下文,这样每位开发者都能为自己的模块得到正确的配置,无需手动设置。对于代码检查、格式化这类自动化检查,Hook 能以确定的方式强制执行规则,比依赖 Claude 记住某条指令产生的结果更一致。
Skill 让正确的专业知识按需可用,而不会让每个会话臃肿起来。 在一个有着数十种任务类型的大型代码库里,并非所有专业知识都需要出现在每个会话中。Skill 通过渐进式披露解决了这个问题:它把那些原本会争抢上下文空间的专门工作流和领域知识卸载出去,只在任务需要时才加载它们。举例来说,当 Claude 在评估代码是否存在漏洞时,会加载一个安全审查 Skill;而当代码发生变更、文档需要更新时,会加载一个文档处理 Skill。
Skill 还可以被限定到特定路径,这样它们只在代码库的相关部分激活。一个负责支付服务的团队,可以把他们的部署 Skill 绑定到那个目录,这样当有人在 monorepo 的其他地方工作时,它绝不会自动加载。
插件 负责把行之有效的做法分发出去。 大型代码库的一个难题是,“好”的配置可能停留在小圈子里。一个插件把 Skill、Hook 和 MCP 配置打包成一个可安装的整体,这样当一名新工程师在入职第一天安装这个插件时,他立刻就能拥有和那些早已在用 Claude 的人相同的上下文和能力。插件的更新可以通过受管理的市场分发到整个组织。
举个例子,我们合作的一家大型零售企业构建了一个 Skill,把 Claude 连接到他们内部的分析平台,让业务分析师无需离开工作流就能拉取业绩数据。在面向业务部门大范围推广之前,他们以插件的形式分发了它。
语言服务器协议(LSP)集成,让 Claude 拥有和开发者在 IDE 中相同的导航能力。 大多数大型代码库的 IDE 都已经在运行 LSP,为”跳转到定义”和”查找所有引用”提供支持。把这一能力暴露给 Claude,就赋予了它符号级的精度:它可以顺着一个函数调用找到它的定义,跨文件追踪引用,并区分不同语言中同名的函数。没有这一能力,Claude 只能在文本上做模式匹配,可能落到错误的符号上。我们合作过的一家企业软件公司,在推广 Claude Code 之前就在全组织范围部署了 LSP 集成,目的正是让 C 和 C++ 的导航在大规模下保持可靠。对于多语言代码库来说,这是价值最高的投入之一。
MCP 服务器扩展一切。 MCP 服务器是 Claude 连接内部工具、数据源和 API 的途径——这些都是它原本无法触及的。最成熟的团队会构建 MCP 服务器,把结构化搜索暴露成一个 Claude 可以直接调用的工具。还有团队把 Claude 连接到内部文档、工单系统或分析平台。
子智能体 把探索和编辑分开。 子智能体是一个隔离的 Claude 实例,有自己的上下文窗口,它接下一个任务、完成工作,只把最终结果返回给父智能体。一旦 Harness 就位,有些团队会启动一个只读的子智能体去梳理某个子系统、把发现写入一个文件,然后让主智能体在掌握全貌的情况下做编辑。
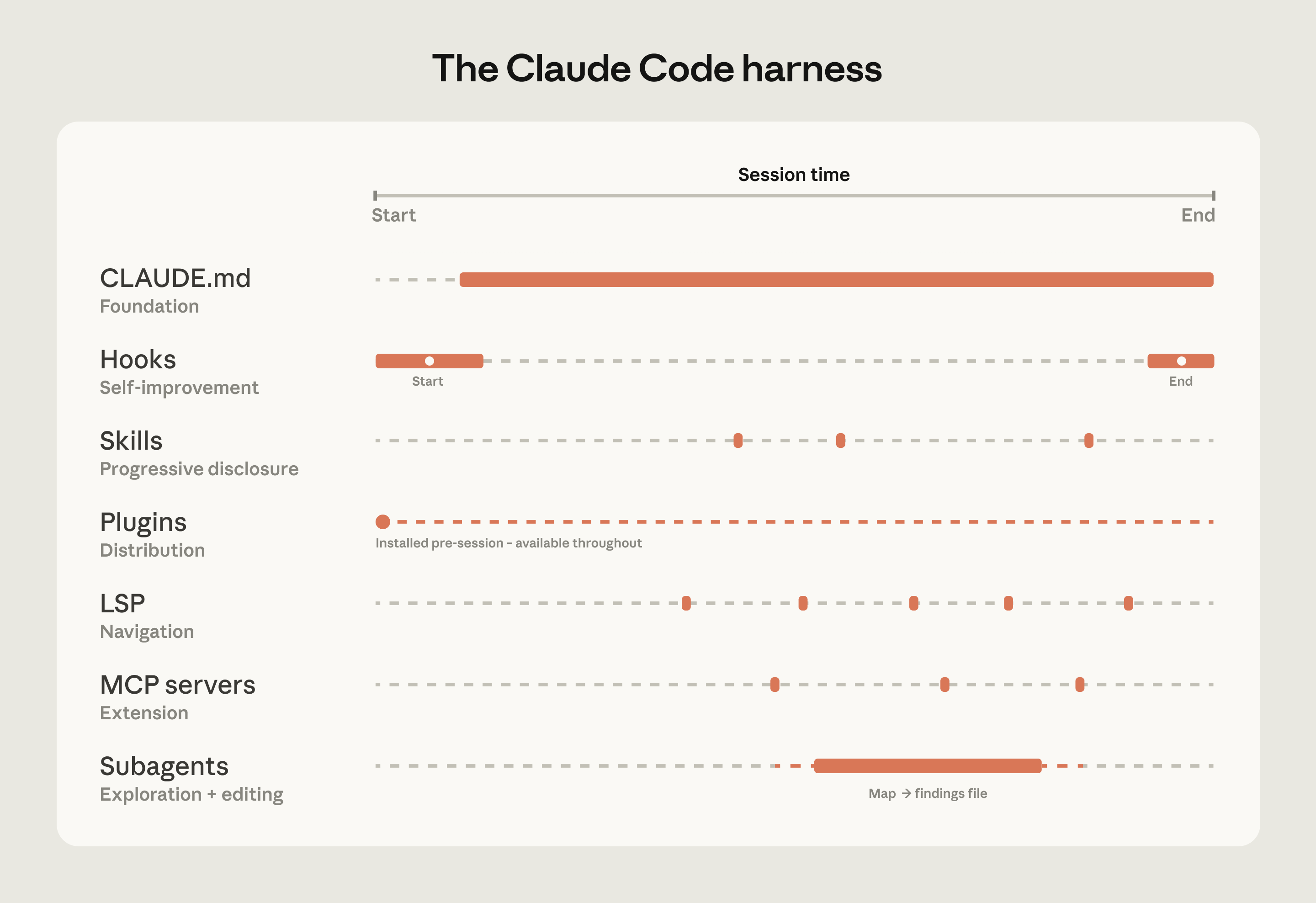
Claude Code 扩展层一览。
下面这张表总结了每个组件的作用、何时加载,以及我们看到的每个组件最常见的误区:
| 组件 | 是什么 | 何时加载 | 最适合 | 常见误区 |
|---|---|---|---|---|
| CLAUDE.md | Claude 自动读取的上下文文件 | 每个会话 | 项目专属约定、代码库知识 | 把本该放进 Skill 的可复用专业知识放在这里 |
| Hook | 在关键时刻运行的脚本 | 由事件触发 | 自动化一致的行为、捕捉会话中的经验 | 对本该自动运行的事情使用提示词 |
| Skill | 针对特定任务类型打包的指令 | 按需加载,在相关时 | 跨会话、跨项目的可复用专业知识 | 反而把所有东西都塞进 CLAUDE.md |
| 插件 | 打包的 Skill、Hook、MCP 配置 | 配置后始终可用 | 把一套行之有效的配置分发到整个组织 | 让好的配置停留在小圈子里 |
| 语言服务器协议(LSP)* | 通过特定语言的服务器提供的实时代码智能 | 配置后始终可用 | 类型化语言中的符号级导航和自动错误检测 | 以为它是自动启用的 |
| MCP 服务器 | 连接外部工具和数据 | 配置后始终可用 | 让 Claude 访问它原本无法触及的内部工具 | 在基础尚未跑通之前就构建 MCP 连接 |
| 子智能体* | 用于特定任务的独立 Claude 实例 | 被调用时 | 把探索和编辑分开、并行工作 | 在同一个会话里同时进行探索和编辑 |
| *LSP 通过插件层来访问。子智能体是一种委派能力,而非一个需要配置的扩展点。 | ||||
来自成功部署的三种配置模式
你如何为一个大型代码库配置 Claude Code,在很大程度上取决于这个代码库的结构。尽管如此,在我们观察到的部署中,有三种模式始终反复出现。
让代码库在规模下可导航
Claude 在大型代码库中能提供多大帮助,受限于它找到正确上下文的能力。每个会话加载的上下文太多会降低性能,太少则让 Claude 只能盲目导航。最有效的部署会在前期投入,让代码库对 Claude 来说变得清晰可读。有几种模式始终反复出现:
- 让 CLAUDE.md 文件保持精简且分层。 Claude 在代码库中移动时会增量加载它们:根目录文件提供全局视图,子目录文件描述局部约定。根目录文件应该只放指引和关键的坑;其余内容都会逐渐变成噪声。
- 在子目录中初始化,而不是在仓库根目录。 当 Claude 被限定在代码库中真正与任务相关的那一部分时,它的表现最好。在 monorepo 里,这可能有些反直觉,因为工具链常常假设需要根目录访问权限,但 Claude 会自动沿目录树逐级向上,并加载沿途找到的每一个 CLAUDE.md 文件,所以根级别的上下文绝不会丢失。
- 为每个子目录限定测试和检查命令的范围。 当 Claude 只改动了一个服务,却要运行整个测试套件时,会导致超时,并把上下文浪费在无关的输出上。子目录级别的 CLAUDE.md 文件应该指明适用于代码库这一部分的命令。这对于面向服务的代码库效果很好——每个目录都有自己的测试和构建命令。但在有着深层跨目录依赖的编译型语言 monorepo 中,按子目录限定范围更难做到,可能需要项目专属的构建配置。
- 用
.ignore文件排除生成的文件、构建产物和第三方代码。 把permissions.deny规则提交到.claude/settings.json,意味着这些排除规则被纳入版本控制,于是团队里每位开发者都能得到同样的降噪效果,无需自己配置。在某些代码库里,生成的文件本身就是开发工作的对象。从事代码生成器开发的开发者,可以在自己的本地设置中覆盖项目级别的排除规则,而不影响团队其他人。 - 当目录结构本身做不到这件事时,构建代码库地图。 对于代码没有按常规目录结构归整的组织,在仓库根目录放一个轻量的 markdown 文件,列出每个顶层文件夹并用一行话描述里面是什么,就能给 Claude 一份目录,让它在打开文件之前先扫一遍。对于有着数百个顶层文件夹的代码库,最好采用分层的方式:根目录文件只描述最高层的结构,子目录的 CLAUDE.md 文件提供下一层的细节,在 Claude 沿目录树移动时按需加载。对于更简单的情况,用 @ 提及 Claude 应该参考的具体文件或目录,可以起到同样的作用。
- 运行 LSP 服务器,让 Claude 按符号搜索,而不是按字符串。 在大型代码库里 grep 一个常见的函数名,会返回成千上万个匹配,Claude 只能不断打开文件、消耗上下文,去弄清楚哪个才重要。LSP 只返回指向同一个符号的引用,所以筛选发生在 Claude 读取任何东西之前。要把它设置好,需要为你的语言安装一个代码智能插件以及对应的语言服务器二进制文件;Claude Code 文档涵盖了可用的插件和故障排查。
一点说明:存在一些边缘情况,即便是分层的 CLAUDE.md 方式也会失效,比如有着数十万个文件夹、数百万个文件的代码库,或者运行在非 git 版本控制上的遗留系统。我们会在本系列后续的篇章中讨论它们的挑战。
随着模型智能演进,主动维护 CLAUDE.md 文件
随着模型不断演进,为你当前模型写下的指令,可能会对未来的模型起反作用。那些曾经引导 Claude 越过它一度难以应对的模式的 CLAUDE.md 文件,在下一代模型发布后,可能要么变得多余,要么反而成为束缚。举例来说,一条要求 Claude 把每次重构都拆成单文件改动的 CLAUDE.md 规则,可能曾帮助早期模型保持在正轨上,但会阻止一个更新的模型做出它本可以驾驭的、协调一致的跨文件编辑。
为弥补特定模型局限而构建的 Skill 和 Hook——无论是模型推理上的局限,还是 Claude Code 自身工具上的局限——一旦那些局限不复存在,就成了额外负担。举例来说,一个在 Perforce 代码库里拦截文件写入、强制执行 p4 edit 的 Hook,在 Claude Code 加入原生 Perforce 模式之后,就变得多余了。
团队应当预期每三到六个月做一次有意义的配置审查,但每当重大模型发布之后感觉性能进入平台期时,也值得做一次。
为 Claude Code 的管理与采纳分配所有权
光有技术配置并不能驱动采纳。那些做对了的组织,在组织这一层也做了投入。
传播得最快的推广,都在大范围开放之前有一项专门的基础设施投入。一个小团队——有时甚至只是一个人——把工具链接通,这样当开发者第一次接触 Claude 时,它已经契合开发者的工作流。在一家公司,几名工程师构建了一套插件和 MCP,在第一天就准备就绪。在另一家公司,有一整个团队专门负责管理 AI 编码工具,在推广开始之前就把基础设施搭好了。这两种情况下,开发者的初次体验都是高效的,而非令人沮丧的,采纳也由此扩散开来。
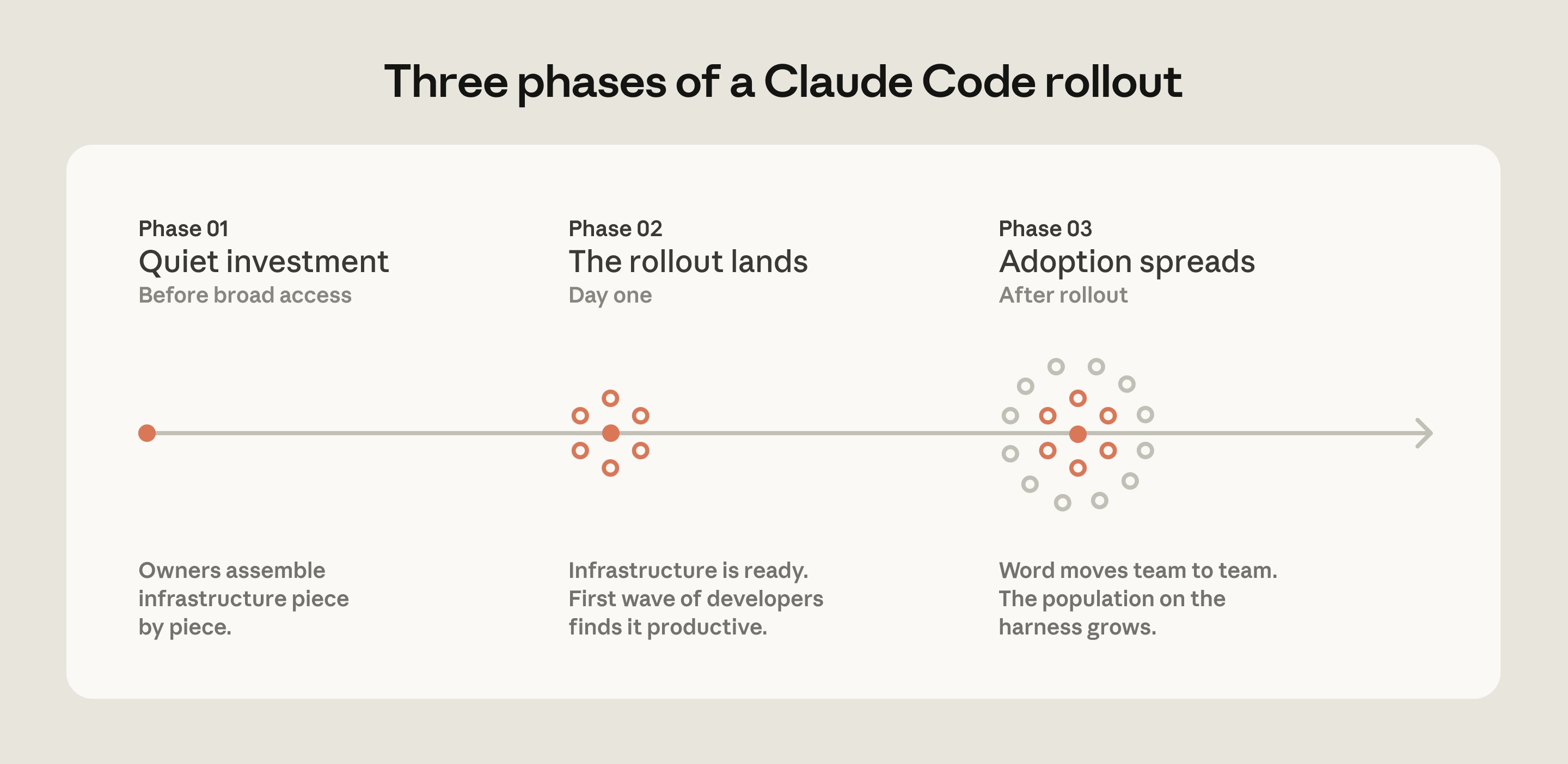
如今从事这项工作的团队,往往隶属于开发者体验或开发者效能部门——这一职能通常负责新工程师的入职以及开发者工具的构建。在好几个组织里,一个新兴角色正在出现:智能体管理者(agent manager),一个 PM/工程师混合的职能,专门负责管理 Claude Code 生态。对于没有专门团队的组织,最简可行版本是一名 DRI:一个人,拥有对 Claude Code 配置的所有权,有权对设置、权限策略、插件市场和 CLAUDE.md 约定做出决定,并负责让它们保持最新。
自下而上的采纳能激发热情,但如果没有人来把行之有效的做法集中起来,它可能会碎片化。你需要有一个人或一个团队,来汇总并推广正确的 Claude Code 约定(比如一套标准化的 CLAUDE.md 层级结构,或者一组精心挑选的 Skill 和插件)。没有这项工作,知识会停留在小圈子里,采纳也会进入平台期。
在大型组织中,尤其是受监管行业的组织,治理问题会很早出现,比如:谁来控制哪些 Skill 和插件可用、如何防止数千名工程师各自独立地重复造同一个轮子、如何确保 AI 生成的代码走和人工编写的代码相同的审查流程。为了及早解决这些问题,我们建议从一组明确批准的 Skill、必需的代码审查流程和有限的初始访问权限起步,随着信心增长再逐步扩展。
我们观察到,最顺畅的部署出现在那些及早建立跨职能工作组的组织——它们把工程、信息安全和治理的代表聚到一起,共同定义需求并制定一份推广路线图。
把这些模式应用到你的组织
Claude Code 是围绕常规软件工程环境设计的:工程师是代码库的主要贡献者、仓库使用 Git、代码遵循标准的目录结构。大多数大型代码库都符合这一模型,但非传统的设置——比如带有大量二进制资产的游戏引擎、使用非常规版本控制的环境,或者由非工程师向代码库贡献内容——需要额外的配置工作。我们的指导假设的是一种常规设置,我们描述的这些模式已经在许多客户那里行之有效。任何剩余的复杂性,都需要针对你的代码库、工具链和组织做出具体判断。这正是 Anthropic Applied AI 团队的用武之地——他们直接与工程团队合作,把这些模式转化为你所在组织的具体需求。

开始使用 面向企业的 Claude Code。
致谢: 特别感谢 Anthropic Applied AI 团队的 Alon Krifcher、Charmaine Lee、Chris Concannon、Harsh Patel、Henrique Savelli、Jason Schwartz、Jonah Dueck 和 Kirby Kohlmorgen 分享他们大规模部署 Claude Code 的经验,也感谢 Zoox 的 Amit Navindgi 为本文提供反馈。
相关笔记
- 解剖智能体Harness —— Harness 概念的系统拆解,可与本文的「五个扩展点」对照
- Agent Hooks:智能体工作流的确定性控制 —— Hook 扩展点的深入实战
- Skill 编写最佳实践 —— Skill 扩展点的编写指南
- 你不知道的 Claude Code:架构、治理与工程实践 —— Claude Code 的架构与治理视角
- 用了 3 个月 Claude Code,这 9 条最佳实践让我少走了无数弯路 —— 个人视角的 Claude Code 实战经验