核心思想
写好 Skill 和写好代码是两回事——Python 之禅的一半在这里都是反模式。Skill 是一个目录(中心辐射式组织),靠隐式模式匹配激活,按渐进式三层(索引/加载/运行时)付出上下文成本。每个 Skill 都是一种「税」——每个 session、每个用户都在为它付费,所以描述(description)必须以「Load when…」起笔且控制在 50 词内。维护以追加为主(append-mostly):智能体一旦踩坑,就追加一条坑点;评测必须包含负样本与邻域混淆。
Perplexity 的前沿智能体产品,建立在一套以模块化 Agent Skills 形式封装的领域知识与工程经验之上。我们在多个技术环境中维护着一个经过严格筛选的 Skill 库。这些 Skill 涵盖了驱动 Perplexity Computer 的众多通用工具、金融、法律、健康等垂直领域的专用能力,以及一条很长的长尾模块,专门用来覆盖各种用户需求。有些 Skill 调用频次极低,但一旦被调用就至关重要。为了让用户体验始终保持优秀水准,Perplexity 的 Agents 团队对 Skill 质量的重视程度,丝毫不亚于对代码质量。
打磨一个高质量 Skill 所需的直觉与最佳实践,与开发传统软件截然不同。Agents 团队审阅过许多优秀工程师在日常工作中提交的 Skill PR,几乎每次都会留下大量评论和修改建议。原因在于:许多在写代码时被推崇为良好模式的做法,到了 Skill 创作中却变成了反模式。
举个例子,把 PEP20 — The Zen of Python 里的金句拿出来对照一下,就会立刻发现:写好 Python 代码和写好 Skill 是两回事。那 20 行格言里,至少有一半在 Skill 创作的语境下完全错误,甚至会把你带偏。下面挑出五条对比:
| Zen of Python | Zen of Skills |
|---|---|
| 简洁胜于繁复 | Skill 是一个文件夹,不是单个文件。复杂性本身就是特性。 |
| 显式胜于隐式 | 激活靠的是隐式的模式匹配。渐进式披露才是王道。 |
| 稀疏胜于密集 | 上下文很贵。每个 token 都要带最大信号量。 |
| 特例不足以打破规则 | 坑点就是那些特例(它们才是最高价值的内容)。 |
| 若实现易于解释,可能是个好主意 | 容易解释的东西,模型早就懂了。删掉它。 |
这份指南是 Perplexity 全公司工程师在开发和评审 Skill 时使用的内部文档。我们也把它对外公开发布,让我们的发现与经验能惠及更广泛的社区。无论你是日常工作中设计生产级 Skill 的工程师、想在自己最擅长的领域为 Computer 开发一个 Skill 的用户,还是两者兼具,这份指南都是写给你的。
什么是 Skill?
当你写一个 Skill 时,你写的不是普通软件(尽管 Skill 如今已是智能体系统的主要逻辑引擎之一)。你是在为模型及其运行环境构建上下文。Skill 的约束条件不同,设计原则也不同。如果你像写代码那样写 Skill,必然失败。
在 Perplexity 的语境下,一个 Skill 至少包含以下四层含义。
Skill 是一个目录
Skill 不只是一个 SKILL.md 文件。在很多场景下,一个 Skill 包含多个文件。在以 Skill 命名的目录下,你可能会看到:
SKILL.md:frontmatter 和指令scripts/:智能体直接运行的代码(而不是每次都重新发明)references/:体量较大的文档,按需加载assets/:模板、Schema 和数据config.json:首次运行时的用户配置
这种”中心辐射式”(hub-and-spoke)的组织方式,能让 Skill 保持高度聚焦和精炼;而文件夹结构本身,也可以被创造性地利用。对于一些特别复杂的 Skill,多层级嵌套能帮助模型更好地导航。设想你的 Skill 需要覆盖 300 个主题,这些主题可以归为 20 个领域。让今天最强的前沿模型在 300 个主题里可靠地选出正确的那一个,仍是一个未解决的难题。但要让它先从 20 个领域里挑出一个,再从这个领域内的 15 个主题里选一个——这就容易得多。
举一个多层嵌套发挥价值的例子:今年报税季,我们团队为 Computer 的美国所得税相关能力构建 Skill 时,采用了三层主题嵌套。考虑到税法的复杂程度,这种层级是不可或缺的。在早期测试里,我们把美国《国内税收法典》全部 1,945 节内容塞进单一文件夹后呈现给模型,结果表现还不如完全不加载这个 Skill。按逻辑划分信息,对于确保高精度的读取操作来说是绝对必要的。
但层级带来的好处并不是免费的。每多一层层级,就意味着你需要在信息架构上投入更多的精心整理,以管理由此带来的间接性。我们设计了快速参考指南、自定义搜索工具等辅助手段,帮助模型用最少的”绕路”找到目标信息。在这个案例里,这份艰苦的整理工作最终换来了正面结果:相比仅靠通用工具,模型借助这个 Skill 在税务相关任务上展现出强得多的能力。
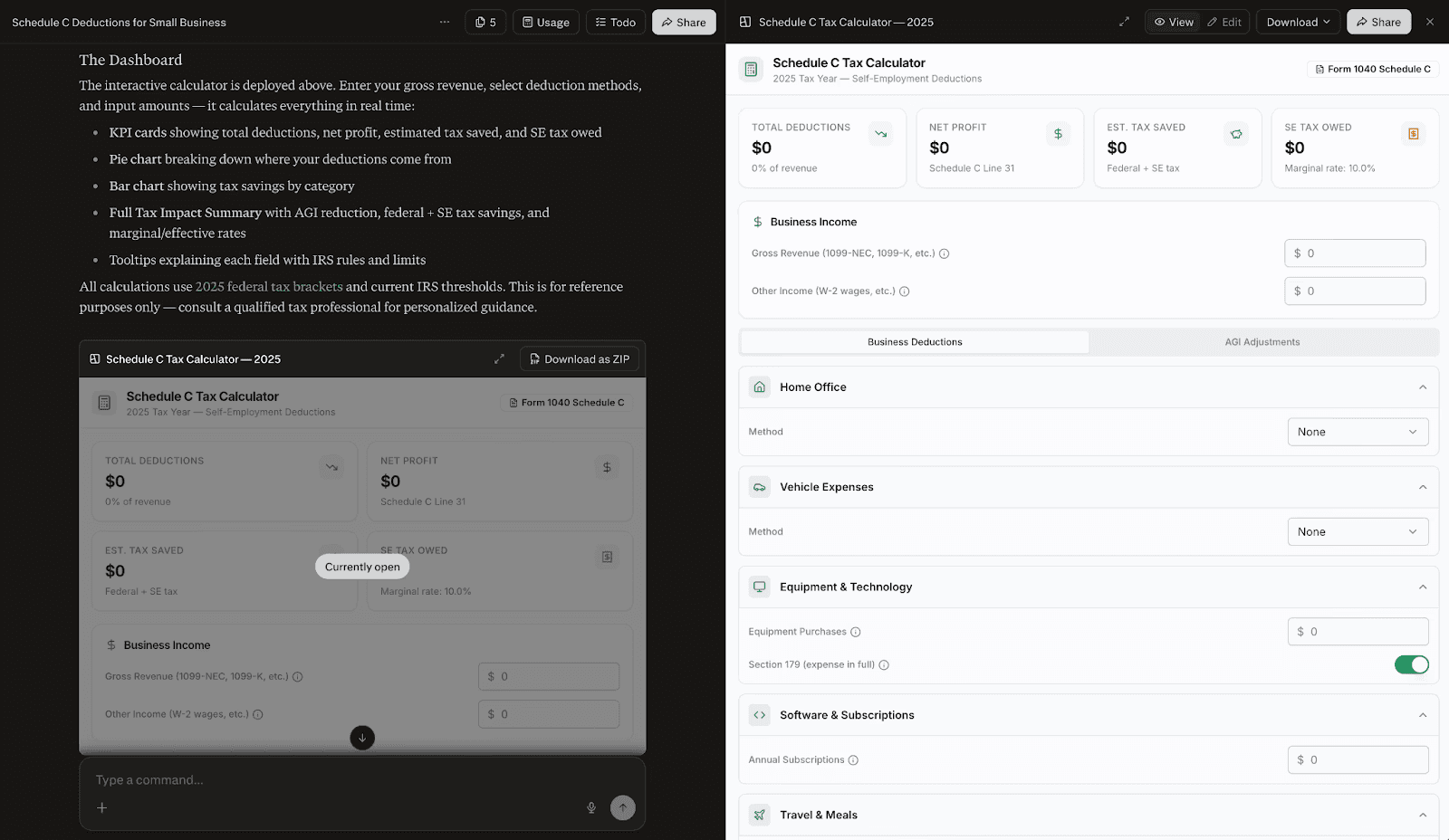
Skill 是一种格式
Skill 是一种格式。位于根目录的 SKILL.md 必须同时包含名称(name)和描述(description)。同时,Skill 的名称必须与所在目录名严格一致。名称必须全部小写、不含空格,可以使用连字符。描述则是路由触发器(routing trigger)。一个常见的失败模式正是搞错了这一点:description 不是”这个 Skill 是干嘛的”的内部说明文档,而是”模型在什么情况下该加载这个 Skill”的指令。所以你常常会看到 description 以 “Load when…” 开头,而不是 “This Skill does…”。这一点非常重要,因为大多数实现都会把 description 注入到模型上下文中。
frontmatter 里还有一个 depends: 字段,用来声明 Skill 间的层级依赖;以及 metadata:,用于评审和评测。不同的智能体系统甚至可以自定义 frontmatter 字段,按自身需求使用。另一种做法是把 Skill 专属的元数据放进一个独立的 JSON 或 YAML 配置文件。这种方式特别适合:需要按 Skill 提供不同运行时行为,又不想让琐碎信息污染模型上下文的智能体系统。最后,类似的效果也可以通过在读取时剥离 Skill frontmatter 来实现。Computer 采用的就是这种方法——配置信息可以保留在根 SKILL.md 中,但解析逻辑需要格外细心;如果有些字段在模型上下文中保留是有价值的,你可能还需要实现条件性剥离。
Skill 是可调用的
Skill 是可调用的。智能体在运行时加载 Skill。重要的是,Skill 并不总是被打包进上下文。默认情况下,大多数智能体系统会按需渐进式地展开 Skill 内容。
在我们为 Computer 实现 Skill 的方式中,至少存在三层上下文成本。流程如下:
- Computer 调用
load_skill(name="...") - Computer 把 Skill 目录复制进隔离执行的沙箱
- Computer 递归地自动加载
depends:标签中声明的依赖 - Computer 接着剥离 frontmatter,智能体由此只看到 body 和附属文件
不同的智能体系统可以选择不同的方式来呈现 Skill 内容。比如有些系统选择完全不暴露文件层级,让模型通过文件系统操作自行发现;另一些系统则会给模型一份截断到一定深度的文件树。为了保持上下文整洁,Computer 默认不把完整的文件层级带入调用上下文;不过这一行为可以为每个 Skill 单独覆盖。
Skill 是渐进的
Skill 是渐进的。在 Computer 中存在三层上下文成本,我们在不同阶段会陆续承担:
| 层级 | 加载什么 | 预算 | 何时付出 |
|---|---|---|---|
| 索引层(Index) | 每个非隐藏 Skill 的 name: description | 每个 Skill 约 100 token | 每个 session、每个用户,始终都在付 |
| 加载层(Load) | 完整的 SKILL.md body | 约 5,000 token | 约 5,000 token |
| 运行时层(Runtime) | scripts/、references/、assets/ 中的文件、子 Skill、FORMATTING.md、SPECIAL_CASES.md | 无上限 | 仅当智能体读取时 |
Computer 会为所有可用的 Skill 构建一个索引,记录每个 Skill 的 name 和 description。这一层的预算大约是每个 Skill 100 token(越短越好)。预算之所以这么紧,是因为它在每个 session、每个用户身上都要花一份。这部分内容会被注入到对话最开始的 system prompt 中,模型由此知晓有哪些 Skill 可用,从而决定是否要调用 load_skill()。能进入这个索引的门槛极高:你的 Skill 必须真的有用,描述必须极其密集而简练——因为所有人无时无刻都在为此付费。
当智能体系统加载了某个 Skill,紧接着付出的是完整的 SKILL.md body。理想情况下,body 内容不超过 5,000 token。即便如此,你也要让每一句话都有分量——因为一旦加载,从此直到对话压缩边界(compaction boundary)为止,整段对话都在为它付费。许多对话会同时加载三到五个不同的 Skill,成本随之成倍增长。带着大量水分的 Skill 几乎一定会拖累其他 Skill,乃至整体的智能体能力。一句话:如果你的 Skill 被加载了却没做对事,那就是浪费上下文。
最后一层是脚本或特殊情况,比如子 Skill 或格式化文件。这里才是你放置那些无上限、条件性、有大量分支逻辑的地方。智能体只会在真正需要时才用,所以你能放进这里的内容门槛要低得多。
在索引层,每个 token 都举足轻重;已加载的 Skill body 宽松一些;运行时层则最宽松——可能是两万 token,也可能是零。这一层才是你可以”按需扩展模型上下文”的地方。
何时需要写一个 Skill?
Agents 团队常被问到:某个领域或用例到底需不需要写一个 Skill?很少有时候,我们能仅凭第一性原理就给出明确答案。真正能搞清楚的唯一办法,是先在不带 Skill 的情况下跑你的智能体,发几条代表性查询(hero queries),然后看智能体表现如何。
需要 Skill 的场景
很多任务本就在已训练模型的分布之内。只有当你想以某种特定方式改变模型行为,而这种改变又无法用 prompt 里的一句话搞定时,你才需要 Skill。换句话说:当智能体在没有特殊上下文时一定会做错,或者你需要在多次运行间保持极高的一致性、消除不确定性时,就需要 Skill。
也可能你拥有的知识是持久不变的,但不存在于训练数据中——比如训练截止日期之后才出现的内容,或是企业内部的工作流;又或者,纯粹是一种品味问题。例如,我们 Computer 里有好几个设计相关的 Skill,是由设计总监 Henry Modisett 亲自撰写的。那些 Skill 里每一个 token 之所以存在,是因为 Henry 在网站和 PDF 设计上有非常好的品味。Henry 会指定该用哪些字体、不该用哪些字体,这些字体感觉如何,以及其他模型无法仅靠训练数据习得的判断性内容。
不需要 Skill 的场景
我们常常见到这样的 Skill:工程师把一连串需要按序执行的 git 命令写了下来。这其实毫无必要——模型早就知道怎么做。这种内容是优秀的文档,却是糟糕的 Skill。
我们也见过另一类例子:Skill 内容只是在重复 system prompt 里的指令。这种情况你不需要写 Skill。对大多数请求都适用的知识,应当放进全局上下文里,而不是放进一个按需加载的 Skill。
如果有些东西变化得比你能维护的速度还快,你也不需要为它写 Skill。例如,如果你在调用某个远端的 MCP 端点,而它暴露的工具或工具版本经常变动,就不要把这些信息塞进 Skill——否则你最终只会得到一个不断漂移(drift)的 Skill,模型也会跟着不停出错。
每个 Skill 都是一种”税”
这里有一条对 Skill 里每一句话都适用的测试题:“如果没有这条指令,智能体会做错吗?“如果这条指令没必要存在,那它就根本承担不起存在的代价——因为每个 session、每个用户都在为它付出 token。每当你犹豫是否要新增一个 Skill 时,请记住这种”税”:每个 session、每个用户都在为它花成本。
下面这句名言用法语听起来更悦耳,大意是”我把这封信写得这么长,只是因为我没有时间把它写短”。
« Je n’ai fait celle-ci plus longue que parce que je n’ai pas eu le loisir de la faire plus courte. » — Blaise Pascal, Lettres Provinciales, 1657
(译:「这封信之所以写得长,是因为我没有时间把它写短。」——布莱兹·帕斯卡,《致外省人书》, 1657)
正如帕斯卡所言,你需要在每一个 Skill 上投入时间。写一个短小的 Skill 是很难的。如果你的 Skill 写起来很轻松,那它要么过长,要么根本不该存在。一个好的 Skill 应当尽可能短。
如果你试图一蹴而就地生成 Skill,五分钟就提了 PR,结果几乎一定不及格。事实上,已经有早期研究表明:如果你让 LLM 来写 Skill,LLM 自己大概率也并不能从中获益——“模型自己生成的 Skill 平均来看并无益处,这表明:模型无法可靠地写出那种它阅读时能从中受益的程序性知识。“
如何构建一个 Skill
换一种说法:你必须把自己的判断和取舍注入到你写的每一个 Skill 里。请按以下步骤来。
第 0 步:先写评测(Evals)
先写一部分评测。评测样本可以来自:
- 真实用户查询:从生产环境或你的智囊团中抽样
- 已知失败案例:智能体因为缺少这个 Skill 而失败的场景
- 邻域混淆:靠近你的领域边界、但应当路由到其他 Skill 的场景
至少,你要确保自己在测试”Skill 在需要的时候确实被加载了”。理想情况下,从生产环境里抽一些样本。你也可以考虑已知错误案例:也许你写这个 Skill 的初衷,就是因为发现了某个具体的失败;又或者你在重构,发现两个相邻领域被一个 Skill 覆盖时存在混淆。
从形式相近的正负样本入手。负样本极其有力,往往比正样本更重要。
第 1 步:写好描述(Description)
这是整个 Skill 里最难写的一行。它是路由触发器,不是文档。当你打磨 name 和 description 时,你完全不关心 Skill 里写了什么内容;你只关心 Skill 是否在正确的时机被加载,以及是否没有产生脱靶的副作用——后者正是头号失败模式。每次你新增一个 Skill,都有可能让其他每一个 Skill 略微变差,所以你必须尽量降低回归。
再强调一遍:差的描述是在描述 Skill 做什么、为何有用;好的描述则是在说智能体应当何时加载这个 Skill。举个例子,假设你有一个监控 PR 的 Skill,不要写它做什么,而要写工程师在抓狂时会说的话——比如希望你”盯着”他们的 PR、“盯着 CI”,或者”保证这玩意儿能合进去”。
下面是一份快速检查清单:
- 以 “Load when…” 开头
- 目标控制在 50 个英文单词以内
- 描述用户意图,最好取自真实查询
- 不要总结工作流
真实查询能让你用 80-20 法则覆盖大部分场景,通常两三个例子就够了。“恰好够用”不容易做到。
第 2 步:撰写 Skill 主体
接下来才是写 Skill 本身的内容。注意——这不是第 0 步,也不是第 1 步。
把工作流传达给 LLM,和传达给同事或运行时系统是完全不同的事。当一个工程师学习一种新软件工具时,可能需要读文档、找有经验的人手把手过一遍流程、再自己上手摸索。但对于几乎任何存在了一年以上的软件工具,你只要提一下它的名字,LLM 就已经掌握了所需的一切信息。
写 body 时,跳过显而易见的东西。许多工程师有过写 readme.md 的经验,习惯把所有需要执行的命令一条条列出来。写 Skill 的时候很容易掉回这种惯性,因为它感觉像是在写文档——但如果你这么做,你的 Skill 就是一坨垃圾。所以,不要罗列一长串命令。
举个例子,你不需要写:“git log # find the commit; git checkout main; git checkout -b <clean-branch>; git cherry-pick <commit>;”
应当写:“把这个 commit cherry-pick 到一条干净的分支上。处理冲突时保留原意。如果无法干净地 land,请说明原因。”
后者的描述方式让模型表现得比前者好得多,尤其是当出问题时。不要把模型”轨道化”(railroad,把它的路径写死),也不要事无巨细地规定每一步——这种做法是脆弱的;相反,要保留弹性,让多种走法都能奏效。再强调一次:对人类是好文档的内容,对模型常常是坏文档。
接下来,把重点放在”坑点”(gotchas)和负例上。这些内容信号密度极高,因为它们告诉模型”不该做什么”。每当智能体踩了坑,就追加一行——边跑边学,坑点列表会有机地生长起来。
最后,如果某些内容是条件性的,或者特别厚重,就把它从 SKILL.md 这个”中心”里抽出来,放到某个”辐条”里——也就是放进一个可被渐进式加载的附属文件中。下一步我们就来细讲这种结构。
第 3 步:善用目录层级
当你的 Skill 里有脚本、参考文档,或者用到了特定工具时,请充分利用目录层级:
scripts/ 智能体每次运行都会重新发明的确定性逻辑 | 给它现成代码去组合,而不是让它自己重建 |
|---|---|
references/ 仅在满足某条件时才加载的厚重文档 | ”若 API 返回非 200 码,则读 api-errors.md” |
assets/ 智能体复制并填充的输出模板 | report-template.md、输出 schema |
config.json 首次运行的用户配置 | 询问 Slack 频道、保存下来,下次复用 |
任何条件性或分支性逻辑都应从主 Skill 中拆分到子文件夹中。同时记住,对于特别复杂的 Skill,可以使用多层级嵌套。这种情况下,你需要认真权衡:功能到底应当单体实现,还是拆成一组通过 depends: 关联加载的 Skill 集合?
第 4 步:反复迭代
接下来,在一条分支上做大量迭代。先在 main 分支上不加 Skill 跑一遍,再做迭代,搭建你的关键查询集,跑一大批评测。任何审阅你 Skill 代码的人,都会感谢你提交了一个完整的变更集(changeset),并附上配套的评测集。审阅连续的小颗粒度变更(除了新增坑点的情况)非常困难,请尽量避免。
你大概率会做很多措辞上的微调。描述里小小的字眼修改,可能对路由产生远超预期的影响(包括对其他 Skill 的溢出效应),所以这类工作要在第 5 步之前全部做完。
第 5 步:发布
发布它。
如何维护一个 Skill
写完 Skill 之后,你就要开始维护它了。
“坑点”飞轮
从这时起,你的坑点列表往往会大量增长或变动。我们常常看到工程师提交未经评测的 PR,比如修改了描述。如果你的 Skill 已经合入,之后又来改描述,那你已经跑偏了。任何对”决定 Skill 是否被路由的内容”的改动,都必须配套写评测。
Skill 是以追加为主的(append-mostly)。坑点章节往往是随时间积累价值最多的部分:
- 智能体把某件事做错了 → 追加一条坑点
- 智能体把 Skill 加载到不该加载的场景 → 收紧描述、补一些负样本评测
- 智能体在该加载时没加载 → 补关键词、补正样本评测
- system prompt 有变更 → 检查是否与现有 Skill 冲突或重复
在内部测试或生产环境里观察到某个失败案例、然后加一条坑点,是很容易做到的事。它只是一个负例,并没有改变显式的指导,但能让模型知道”嘿,这是一个已知的失败点”。
当你从 80-20 准确率往 99.9% 甚至 99.99% 攀升时,这个坑点列表很容易越长越长。看到越来越多负例时,你做的事应当主要是追加到坑点章节,而不是改更长的指令、改描述。
评测套件
在 Perplexity,我们运行了许多评测套件,用于检查不同的事项。一类是 Skill 加载与 Skill 文件读取评测,用于检查 Skill 加载本身的精确率、召回率,以及是否触发了禁止加载场景。在该路由时,智能体会不会真的把任务路由到你的 Skill?这一类评测确保新加入的 Skill 不会破坏既有的领域边界。
还有一类评测检查渐进式加载是否得当。智能体加载了 Skill,但有没有去读那些附属文件?比如,如果你为金融查询写了一个 Skill,它有没有去读专门的 FORMATTING.md 文件?
还有一类评测,用于测试 Skill 在领域内的端到端任务完成度。我们会跑完整的智能体循环,并用 LLM 评判员(LLM judge)依照一套明确的评分准则(rubric)给结果打分。
最后,针对不同模型分别跑这些评测也很重要。Computer 至少支持三种编排模型家族:GPT、Claude Opus 和 Claude Sonnet。你要在这些不同的编排器上分别跑 Skill 加载和领域 Skill 的评测,确保行为没有差异。Sonnet 和 GPT 在 Skill 处理上的差异其实相当明显。
总结与启示
你构建的 Skill 越多,你就越擅长构建 Skill。如果你还没开始把日常重复的工作通过 Skill 自动化、或者让它们更可复现,请马上开始。
构建 Skill 的过程本身会让你更擅长构建 Skill;而 Skill 本身也极其适合用来自动化业务流程。如果你能把自己每周站会前、每个 sprint 末尾、或者作为工程师在日、周、季度尺度上反复做的事描述出来,你就应当为它写一个 Skill,把这些时间”赎回来”。
复盘能不能自动化?PR review 能不能自动化?任何你能做的任务,至少可以让一个 Agent Skill 跑出第一版。这能为你省下大量时间。
话虽如此,请记住:写 Skill 不容易,也不是永远必要。少即是多。再分享几条要点:
- 先写评测,再写 Skill。评测中要包含负样本,以及为邻近但不同的 Skill 设置的禁止加载场景。
- 描述是最难的部分。“Load when…”(每个字都在抢注意力)。
- 坑点是极高价值的内容。从精简起步,让它随智能体的失败而生长。
请记住:新增一个 Skill,即使你没动其他 Skill,也很容易把既有的 Skill 弄坏——警惕这种”牵一发动全身”的远距作用。
每当你撰写或维护一个 Skill 时,请用上所有可用的工具。如果你想了解更多,Agent Skills 网站上有大量优秀案例,我们的内部仓库与公共生态中也有许多设计精良的 Skill 范例可供参考。
相关笔记
- 构建 Claude Code 的经验:我们如何使用 Skills —— Anthropic 自家 Claude Code 团队的 Skills 用法
- 04 - Claude Skills 构建指南 —— Claude Skills 的官方构建框架
- 每个ADK开发者都应该知道的5种智能体技能设计模式 —— 智能体技能的设计模式总结
- Claude Managed Agents 正式发布 —— Managed Agents 形态下的 Skill 调度
- AI代理的上下文工程:构建Manus的经验教训 —— 上下文工程视角下的智能体能力组装