核心思想
与其直接给 Fable 5 写提示、做引导,不如为它设计循环:用
/goal或 Outcomes 给环境注入反馈让模型自我修正,并交给独立上下文的验证器子智能体来评分(而非自我批评)。再叠加跨会话记忆,Fable 5 能走完「失败→调查→验证→提炼→查阅」的完整进阶,在 Parameter Golf 上的改进幅度约为 Opus 4.7 的 6 倍。核心取舍:把人的精力从「调提示」转向「设计反馈环境与记忆结构」。
像 Claude Fable 5 这样的 Mythos 级模型,已经改变了我们很多人在 Anthropic 的工作方式。我想分享两个技巧,帮你把这一类模型用到极致。
自我修正循环
最近大家对循环(loop)的兴趣很高。@bcherny 提到过,“(他的)工作就是写循环。“让模型在某个评估上做爬坡式优化,是提升任务表现的常见套路:Claude Code 里的 /goal 和 Claude Managed Agent 里的 Outcomes 就是两个原语,让你能把这套通用套路套用到自己的具体任务上。
正如我们在提示指南里提到的,Fable 5 很擅长在循环中自我修正。一个设计良好的目标或评分标准(rubric),会给 Claude 所运行的环境注入反馈。这样 Claude 就能跑起来、通过目标或评分标准收集反馈、自我修正,并持续推进,直到目标或评分标准被满足。

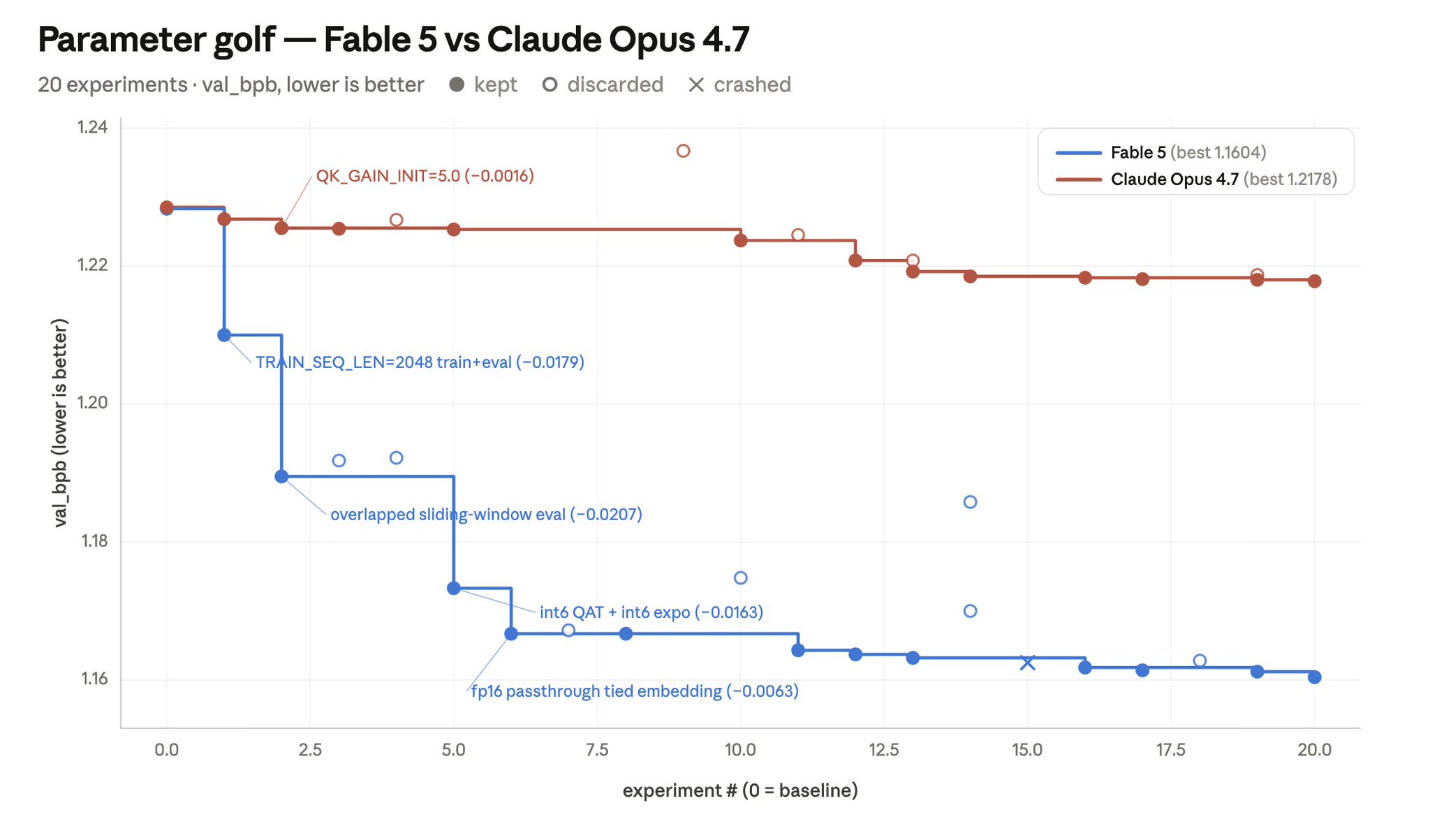
我来分享一个我用来测试 Fable 的玩具示例:Parameter Golf 是一个开源的机器学习工程挑战——在 8 张 H100 上、10 分钟以内,训练出能塞进 16MB 文件里的最优模型。
它有点像 @karpathy 的 autoresearch 项目:它考验的是智能体能不能编辑基础的训练代码(单个 train_gpt.py 文件)、启动训练、轮询日志、读取分数,再决定下一步该跑什么实验。
我用 Claude Managed Agents(CMA)在这个挑战上对比了 Fable 5 和 Opus 4.7。CMA 同时提供了智能体 harness 和托管沙箱,因此非常适合 Fable 5 这类长时间运行的任务。对于 Parameter Golf,我给 CMA 接入了 8 张 H100 GPU,作为自托管沙箱。
有一个微妙的点:由谁来评判很重要。我们发现,模型在对自己的输出做自我批评时会遇到问题。Prithvi Rajasekaran 在我们的工程博客这篇文章里写到过这一点。
我们发现,对 Fable 5 来说,验证器子智能体往往比自我批评表现更好,因为评分是在一个独立的上下文窗口里完成的。CMA 里的 Outcomes 会替你生成一个评分子智能体来处理这件事。
每次测试,我都提供一份评分标准(一个文件),里面有九条可核查的标准(例如:跑一个基线、跑 20 次实验等等)。然后,我让 Parameter Golf 最多运行 8 小时。Outcomes 评分器会先确认所有实验标准都已满足,才允许 Claude 停止工作。
Fable 5 对训练流水线的改进幅度,比 Opus 4.7 大了约 6 倍。如果我们把实验区分为结构性的(例如架构改动)和标量性的(例如调整某个常数),那么 Fable 5 押注于更大的结构性改动,并表现出了韧性(例如,硬是顶着一次量化带来的性能回退,最终拿下它最大的一次胜利)。
Opus 4.7 的第一次实验带来了一个小胜,而此后几乎所有实验都沿用同一个模板:调整一个标量、测量、若为正则保留。
记忆
记忆是 Fable 同样出色的另一个领域。我们可以把它看作一个跨会话的外层循环:Claude 在某次会话中写入记忆,而这些记忆可以在未来的会话中被取回。
@pgasawa 和团队最近发布了 Continual Learning Bench 1.0,所以我想在 Fable 5 上对比测试一下它和更早的模型。
今天,他们发布了 Continual Learning Bench 1.0:第一个用于衡量 AI 系统在在线环境中如何改进的现实基准。如今的基准假设模型是无状态的——每个示例都彼此独立,系统一旦完成一项任务,就会继续前进,仿佛什么都没发生过。但部署中的 AI 系统理应从经验中学习。
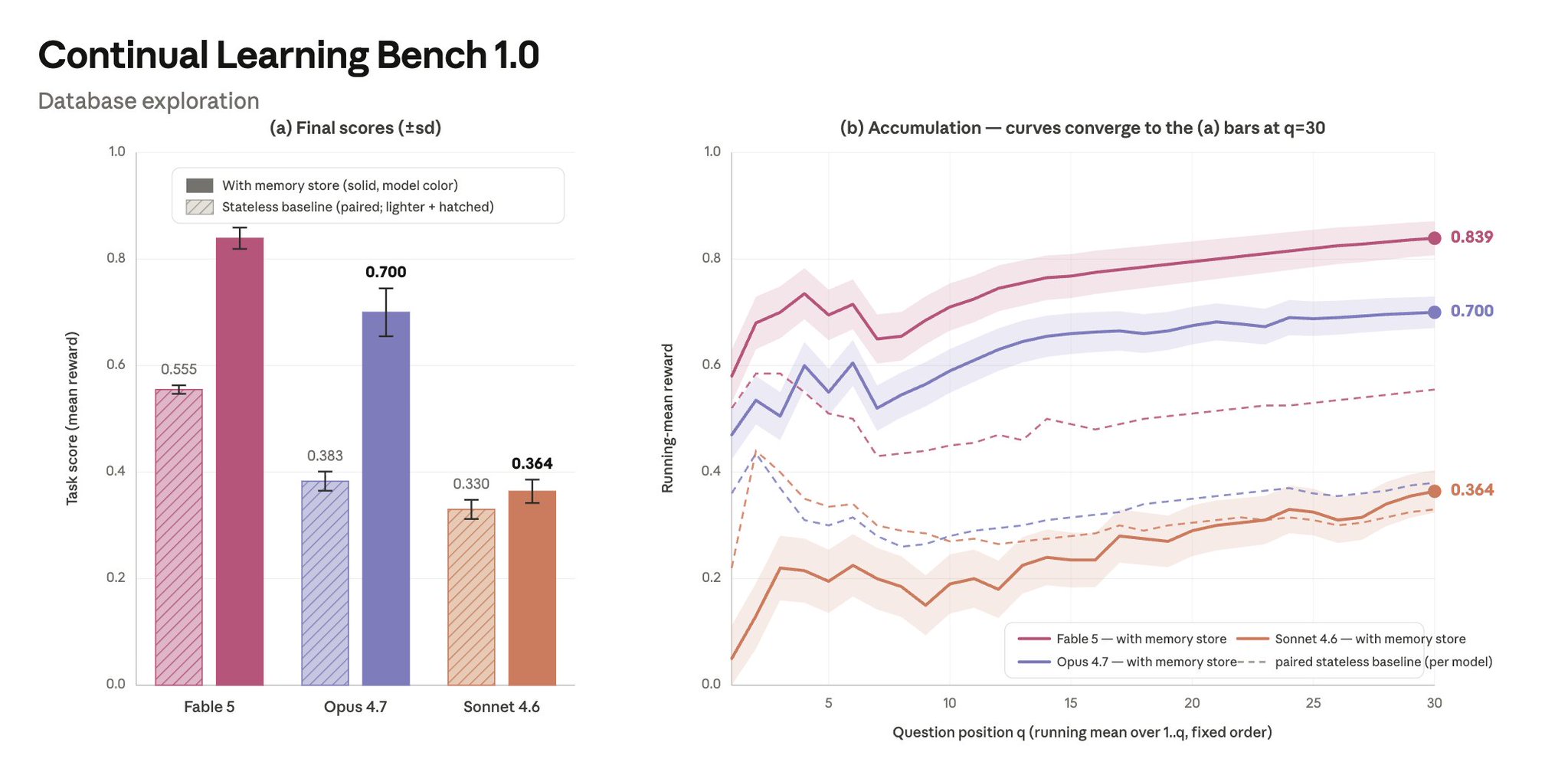
我在该基准的一项任务上对比了 Fable 5、Opus 4.7 和 Sonnet 4.6:这项任务要求智能体在可访问一个 SQL 数据库的前提下,回答一连串的问题。每个问题都是一次独立的智能体会话,并提供了记忆。
为此,我使用了带记忆的 CMA,它给每个智能体接入了一个挂载的文件系统,可以在多次会话之间共享。
对于这项任务,要有效利用记忆,需要经历这样一个进阶过程:失败(做错了某件事并记录下来)、调查(在继续之前,先弄清楚为什么)、验证(把诊断转化为一个经过核实的事实)、提炼(把验证升华为一条通用规则),以及查阅(去读那条规则,而不是重新推导一遍)。
Sonnet 4.6 在第 1 步左右就止步了:它的记忆库是一份失败笔记和未决猜测的清单(例如,“也许是 prc 而不是 prc_usd?”)。它很少去查阅先前的笔记。要提升表现,就需要针对具体任务的记忆指令。
Opus 4.7 在第 3 步左右止步:它会创建一份带不确定性标注的 schema 参考(例如,“prc 可能是以分为单位?待验证。”),但验证覆盖率偏低:只覆盖了 7%–33% 的问题(运行中位数约 17%)。
Fable 5 则往往能走完整个进阶过程:在它表现最强的几次运行中,验证覆盖率高达 73%(30 题中覆盖 22 题),并且它会把所学提炼成通用规则,从而对未来的任务有所帮助。
与其直接给 Fable 5 下提示、做引导,往往更好的做法是:设计一些循环,让模型能够响应环境反馈来自我修正(例如 /goal 或 Outcomes),并管理它自己的上下文(例如通过记忆)。
我在这里只分享了几个自己跑过的小规模实验,但很值得你亲自在有挑战性的任务上测试 Fable 5,并用循环来做自我修正或记忆管理。
想要上手,可以查看我们的文档,或者直接问最新版的 Claude Code——它可以用我们内置的 /claude-api skill 来给你介绍 Fable 5(例如提示的最佳实践)、/goal、Claude Managed Agents,或者其他 API 特性。