核心思想
主张:与编码智能体协作的杠杆点正从「敲提示词」上移一层到「设计那个替你敲提示的循环系统」。但循环只在四条件全满足时才值得搭——任务重复、验证自动化、预算扛得住、智能体有资深工程师工具,缺一即亏本。真要搭,就从最小可行循环起步:一个自动化、一个技能、一个状态文件、一道客观闸门(决定循环是帮你还是烧钱的关键)。核心取舍:循环让你产出更多代码,却也带来理解债与认知缴械——搭起循环,仍做工程师。

大多数开发者至今仍在手动给自己的编码智能体写提示词。他们敲下提示、等待、读 diff、再敲下一条提示。10 个开发者里有 9 个从没写过哪怕一个能替自己向智能体发提示的循环。
没有自动化,没有状态文件,没有验证器,没有调度。杠杆点已经转移了——从「敲提示词」转向「设计那个去敲提示词的系统」。这就是从提示者到循环设计者的 14 步路线图。
关注我的 LinkedIn,获取最新的 AI 一手洞见:linkedin.com/in/lev-deviatkin
这份完成转变的 14 步路线图,素材取自 Anthropic 的工程文档、Addy Osmani 关于循环工程的长文,以及近期的若干测量研究。
三个层级:先弄清你到底需不需要循环,再学会五大构件,最后搭一个不会反噬你的、能跑起来的最小循环。
14 步。3 个层级。停止提示。开始设计。
第一部分 · 为什么,以及那道测试
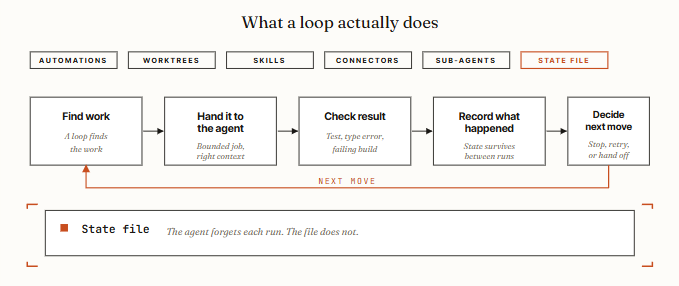
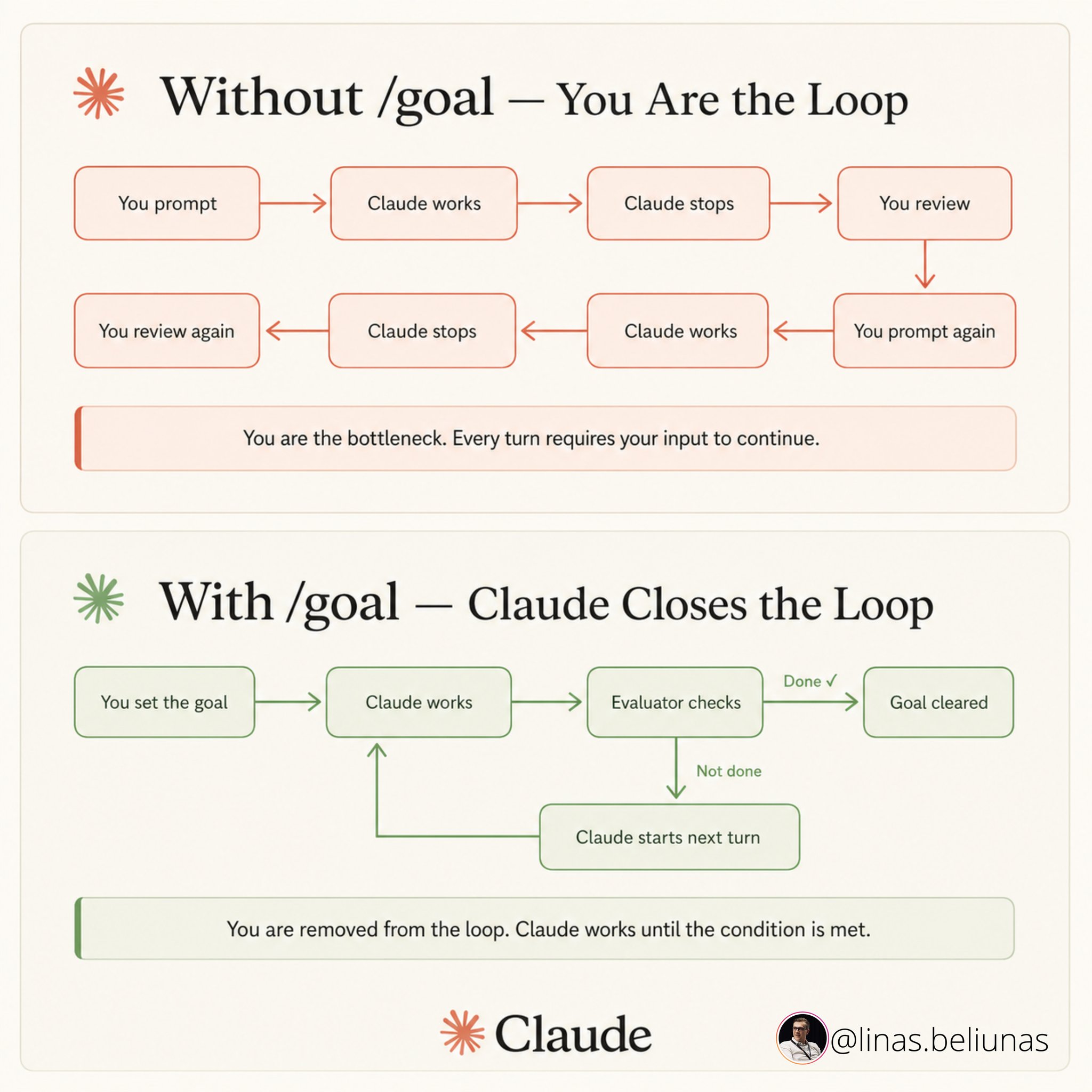
01. 循环工程,就是把「身为提示者的你」替换掉。
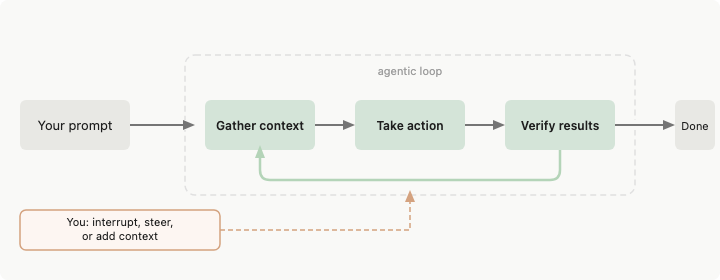
过去两年,你从编码智能体里得到产出的方式是:写一条提示词,提供上下文,读它返回的东西,再写下一条提示词。智能体是一件工具,而你自始至终都握着它。这种模式正在终结。
循环工程,是搭建一个小型系统:它找到要做的活,把活交给智能体,检查结果,记录发生了什么,然后决定下一步怎么走——全程自主完成。你只设计这个系统一次。从此以后,由系统去向智能体发提示。
Addy Osmani 把它拆成六个部分:
如今 Anthropic 的工程师每天合入的代码量,是他们 2024 年的八倍——而对这个数字,Anthropic 自己都说它「几乎可以肯定夸大了真实的生产力增益」。
这个数字有争议。但其中的机制没有争议:杠杆点已经从「敲提示词」转移到「设计那个去敲提示词的循环」。
02. 动手搭建之前,先跑一遍「四条件测试」。
循环要值回它的成本,需要同时满足四个条件。缺一个,循环的代价就会超过它的回报。这是 AlphaSignal 分析里最诚实、也最常被各路 X 长帖略过的部分:
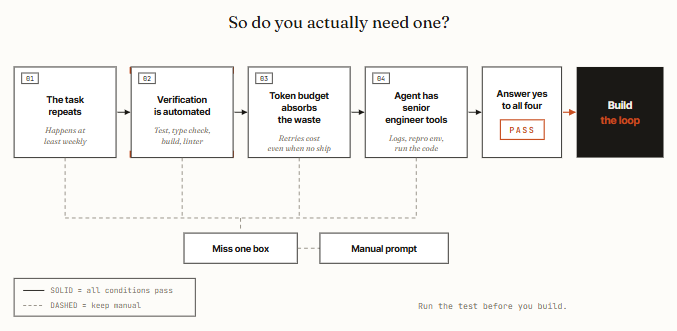
四个条件,用大白话说:
- 任务会重复。 循环靠多次运行把搭建成本摊薄。对于一次性的活,一条好提示词又快又省。如果这活儿不会每周重现,那你拥有的就不是循环——只是一个你跑过一次的脚本。
- 验证是自动化的。 循环需要某种东西,能在你不在场的情况下判定工作不合格。一套测试、一个类型检查器、一个 linter、一次构建。没有自动化检查,你就又得坐回椅子上、逐个 diff 地读——而这恰恰是循环本应替你卸掉的活。
- 你的 token 预算扛得住浪费。 循环会反复重读上下文、重试、四处探索。不管这一轮最终有没有交付东西,token 都照烧不误。这门技术随预算扩展,所以在 token 几乎免费的人看来它显而易见,而在按量计费的人看来它鲁莽得很。
- 智能体拥有资深工程师的工具。 日志、一个可复现的环境、运行它自己写的代码并看哪里崩掉的能力。没有这些,循环就是在盲目迭代。
03. 谁赢,谁输。循环偏爱那些花得起钱的人。
这套经济账并不普适。说循环工程「显而易见」的人,往往手握不计量的 token。
而觉得它「鲁莽」的人,通常是在 20 美元的消费级套餐上,想跑重度验证循环,又得提防触顶或收到一张意外账单。
实际上真正受益的是谁:
- 既有重复、可机器检查的工作、又有预算去跑它的团队——持续的测试甄别、依赖升级、lint 修复扫描、在测试覆盖扎实的代码库上把 issue 草拟成 PR。
- 已有扎实测试套件的代码库。 如果一项任务,一名初级工程师照着清单就能做、而一套测试套件能抓住他的错误,那循环就适合。
- 已在使用多智能体模式的异步优先团队。 对这些团队来说,例程(routine)正是缺失的那一层编排。
今天就该跳过它的是谁:
- 消费级套餐上的独立开发者——token 账单会赶在生产力增益之前先到。
- 任何在没有自动化验证的代码上工作的人。 没有真正检查的循环,就是智能体在反复对自己点头称是。
- 真正的瓶颈是评审产能、而非打字速度的团队。 循环会产出更多代码;如果评审本就是瓶颈,它只会把队列拉得更长。
对于一次性任务、探索性工作,或任何「完成」是主观判断的事情,一条瞄得准的提示词依然胜出。这篇文章诚实的版本是:循环工程是真实存在的,但大多数开发者目前还用不上它。
04. 30 秒循环自检。
第 2 步的四条件测试是战略决策。这一条是战术决策——在你把某个具体任务变成循环之前,对它跑一遍的清单。
缺任何一项,就把它留作手动提示。
- 1. 任务至少每周发生一次。 低于每周 → 搭建成本永远摊不回来。
- 2. 测试、类型检查、构建或 linter 能拒绝坏输出。 没有自动化闸门 → 智能体在给自己的作业打分。
- 3. 智能体能运行它所改动的代码。 没有复现环境 → 迭代是盲目的。
- 4. 循环有硬性停止条件。 token 预算、迭代次数或时间上限。没有它,循环会一直跑到有人注意到账单为止。
- 5. 合并、部署或改依赖之前有人类评审。 任何不可逆的动作,在执行前都需要一道人类审批闸门。
好的首个循环:
- CI 失败甄别——每晚扫描失败、归类成因、为简单的那些草拟修复 PR。
- 依赖升级 PR——每周扫描更新、测试兼容性、开 PR。
- lint 修复扫描——在每次 PR 打开事件上,自动套用风格修复。
- 不稳定测试复现——循环到某个假设能在测试中存活为止。
- issue 到 PR 草稿,在测试扎实的代码上做,让坏输出被套件挡回去。
差的首个循环——这些需要人坐在椅子上:
- 架构重写
- 鉴权或支付代码
- 生产环境部署
- 含糊的产品工作
- 任何「完成」靠主观判断的事
第二部分 · 五大构件
05. 自动化:心跳。
自动化是让一个循环成为真正的循环、而非「你跑过一次的单次运行」的东西。它们按计划、按事件,或按某个触发条件触发。它们是心跳——循环里其余的一切都挂在它们身上。
在两款关键工具里,它长这样:
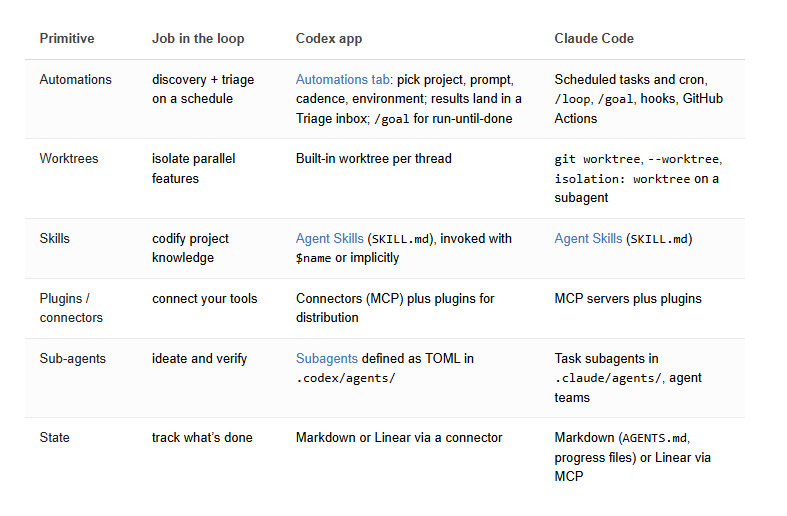
- Codex。 Automations 选项卡——选一个项目、设一条提示词、设一个节奏,再选本地检出还是后台 worktree。有所发现的运行落进 Triage 收件箱;一无所获的运行则自行归档。
- Claude Code。 三个可组合成同一形态的原语:/loop 用于会话范围内的节奏,桌面端定时任务用于「重启后存活」,例程(Routine)用于「合上笔记本也能跑」的云端运行。再配合 hook 处理生命周期事件。
自动化内部有两个原语,把「能用的循环」和「烧钱的循环」区分开来:
- /loop 按节奏重跑。当你想无视状态、定期检查时用它。
- /goal 会一直跑,直到你写下的某个条件真正为真。由一个独立的小模型来检查是否完成,于是写代码的智能体就不会是给它打分的那一个。
这就是把生成者-检查者(maker-vs-checker)的分工,应用到了「停止条件」本身上。
> /loop 30m /goal All tests in test/auth pass and lint is clean.
Scan src/auth for new failures, propose fixes in claude/auth-fixes,
open draft PR when goal condition holds.
▲ Claude
CronCreate(*/30 * * * * : auth quality loop)
Stop condition: tests pass + lint clean (verified by checker)
✓ Scheduled. Will continue past intermediate completions
until /goal condition is met by independent checker.06. Worktree:并行而不混乱。
只要你跑超过一个智能体,文件就开始相撞。两个智能体写同一个文件,跟两名工程师不打招呼就往同几行代码上提交是一样的头痛。
git worktree 解决了它——一个独立的工作目录,跑在自己的分支上,共享同一份仓库历史,于是一个智能体的改动,从物理上就碰不到另一个智能体的检出。
两款工具里它如何呈现:
- Codex 内建了 worktree 支持——多个线程同时命中同一个仓库,彼此不会撞车。
- Claude Code 直接暴露了 git worktree、一个让会话在自己检出里打开的
--worktree标志,以及子智能体上的isolation: worktree设置——让每个助手拿到一份全新检出,用完后自行清理。
worktree 拿掉了机械层面的碰撞,但你仍然是那个天花板。 你能真正同时跑多少个并行智能体,由你的评审带宽决定——而非工具。
07. 技能:项目知识写一次,每轮都读。
技能(Skill)是你不再像金鱼一样、每个会话都把同一套项目上下文重新解释一遍的方式。两款工具用同一种格式:一个文件夹,里面放一个 SKILL.md,装着指令和元数据,外加可选的脚本、参考资料和素材。
为什么这对循环尤其重要:一个没有技能的循环,每一轮都从零重新推导出你的整个项目上下文。有了技能,意图会复利累积。
那些约定、构建步骤、「我们不这么干,是因为出过那一次事故」——在外部写一次,被每一轮运行读取。
name: ci-triage
description: Classify CI failures by root cause (env, flake, real bug,
dependency, infra), draft fixes for the easy ones, escalate the rest.
Trigger whenever a workflow run fails or on the morning triage loop.
---
# CI 甄别技能
## 分类规则
- env: 缺密钥、环境变量错误、基础设施未就绪。 # 交人类
- flake: 不改代码、重试即过。 # 重试一次,然后归档
- bug: 与近期提交相关的确定性失败。 # 草拟修复
- dependency: 与某次版本升级相关的失败。 # 草拟回滚
- infra: 超时、OOM、runner 故障。 # 升级上报
## 修复模式
- 鉴权测试 → 先查 src/auth/middleware
- 数据库测试 → 确认 CI 环境里已应用 migration
- E2E 测试 → 对照最新 UI 快照检查选择器
## 绝不做
- 禁用失败的测试 —— 一律改为作为升级事项归档
- 未经人类批准就修改 CI 配置
- 触碰 src/payments/ 或 src/billing/(详见 claude/permissions.md)
## 状态
每轮运行后更新 STATE.md:检查过的文件路径、分类结果、
开过的 PR、升级的事项。08. 连接器:让循环触达你真实的工具。通过 MCP。
一个只能看见文件系统的循环,是个很小的循环。连接器建立在模型上下文协议(MCP)之上,让智能体能读你的 issue 跟踪器、查询数据库、命中预发布 API、往 Slack 里丢一条消息。
Codex 和 Claude Code 都讲 MCP,所以你为其中一个写的连接器,通常在另一个里直接就能用。
这就是「一个说『修复方案在这儿』的智能体」与「一个会打开 PR、关联 Linear 工单、并在 CI 变绿后往频道里发提醒的循环」之间的区别。
连接器,正是循环能在你真实环境内部动手、而不只是告诉你「假如它能做、它会怎么做」的原因。
对循环工作回本最快的连接器,按顺序排列:
- GitHub——读仓库、建分支、开 PR、在 issue 上评论、响应 webhook 事件。对任何代码循环而言,这是上线第一天最大的那个赢面。
- Linear 或 Jira——随循环推进更新工单、把 PR 反向关联到 issue、在验证通过后自动关闭事项。
- Slack——发布甄别结果、在升级时提醒人类、早上把通宵跑的运行做个总结。
- Sentry / 你的错误跟踪器——让循环去调查实时告警,并为高频的那些草拟修复。
09. 子智能体:让生成者远离检查者。
循环里到目前为止最有用的结构性手法,就是把「写代码的智能体」和「检查代码的智能体」拆开。Osmani 的说法很精准:写代码的那个模型,「给自己的作业打分时太手软了」。第二个智能体——带着不同的指令、有时还是不同的模型——能抓住第一个智能体自我说服后放过的东西。
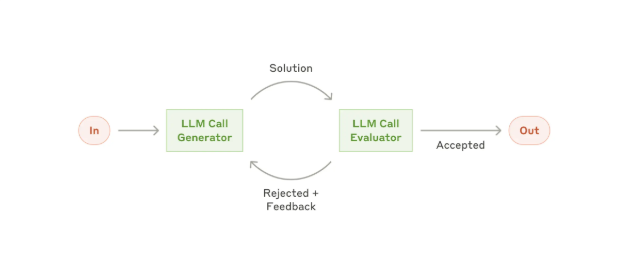
这就是 Anthropic 2024 年 12 月那篇工程博文里的评估器-优化器模式,换了个新名字。一个模型生成,另一个批判,循环往复。2026 年爆火的词汇,十八个月前就已被记录在案。
子智能体在两款工具里如何落地:
- Codex 只在你要求时才孵化子智能体,同时运行它们,再把结果折回成一个答案。你把自己的智能体定义为
.codex/agents/里的 TOML 文件——名称、描述、指令,以及可选的模型和推理强度。你的安全审查员可以是一个高强度的强模型,而你的探索者则是某个只读的快速小家伙。 - Claude Code 用
.claude/agents/里的子智能体、以及彼此传递工作的智能体团队,做同样的事。常见的分工:一个智能体探索,一个实现,一个对照规格做验证。
它为什么在循环内部尤其重要: 循环是在你不盯着的时候运行的,所以一个你真正信得过的验证器,是你敢于走开的唯一理由。子智能体会烧掉更多 token,因为每一个都要做自己的模型与工具调用——把它们花在「第二意见值得付费」的地方。
第三部分 · 要么搭对,要么别搭
10. 状态文件。智能体会忘,文件不会。
这一块听起来蠢得不值一提,实际上却是每一个能跑的循环的脊梁。一个 markdown 文件、一块 Linear 看板、一份 JSON 状态——任何活在单次对话之外、记着「已完成什么、接下来做什么」的东西。
为什么这很重要:智能体默认记性很短。它这个会话学到的东西,除非你写下来,否则明天就没了。
Osmani 的法则:智能体会忘,仓库不会。 没有持久状态的循环,每一轮都从头开始;有状态的循环,则会接着上次继续。
# Loop state · ci-triage
## Last run
2026-06-09 03:30 UTC · 7 failures classified, 3 fixes drafted, 4 escalated
## In progress
- claude/fix-auth-token-refresh — tests passing locally, awaiting CI
- claude/fix-flaky-payment-webhook — retry pattern applied, monitoring
## Completed today
- claude/bump-axios-1.7.4 → merged (CI green, deps loop verified)
- claude/lint-fix-pass-june-9 → merged
## Escalated to humans
- src/billing/refund.ts — tests failing in 3 ways, root cause unclear
- ci/staging-runner — infra timeouts, not a code issue
## Lessons learned (write here, not in chat)
- 2026-06-08: PowerShell hits TLS 1.2 issue on this Windows runner. Use bash.
- 2026-06-07: tests/e2e/checkout requires Stripe webhook secret in env. Skip if missing.
## Stop conditions met since last review
- /goal "all tests pass + lint clean" achieved on commit 3a7b8c1 at 02:14 UTC状态文件放在哪里,有两种模式:
- 放在仓库里的 markdown——根目录或
.claude/里的 STATE.md。纳入版本控制。简单。diff 可读。最适合个人或小团队工作。 - 外部系统(Linear、GitHub Issues、数据库)——能跨仓库存活、可查询、支持全团队可见。最适合那些需要多名人类看清循环在做什么的生产级循环。
对于有偏离目标风险的长跑循环,给状态文件配上一份长期存在的高层规格——VISION.md 或 AGENTS.md——让智能体每轮都重读。状态告诉智能体它在哪里。规格告诉它要去哪里。
11. 最小可行循环。
如果你在第 2 步通过了四条件测试,那就在搞任何花活之前,先搭一个能跑的最小循环。四个部件,不搞集群。

四个部件,用大白话说:
- 一个自动化。 一次按节奏触发、在明确条件下停止的定时运行。在 Claude Code 里用 /loop,在 Codex 里用一个 automation。当你想让它一直跑到某个声明的条件成立时,配上 /goal。
- 一个技能。 一个 SKILL.md,存下智能体本来每轮都要从零重新推导的项目上下文。
- 一个状态文件。 一个 markdown 文件或一块 Linear 看板,记着「已完成什么、接下来做什么」。明天的运行会接着上次继续,而不是从头再来。
- 一道闸门。 那个能自动把坏工作判败的测试、类型检查或构建。正是这一部分,决定了循环是在帮你,还是只在烧钱。
顺序很重要: 先让一次手动运行变得可靠。把它做成技能。用循环把它包起来。然后再调度它。跳着来,正是循环在生产环境里翻车的方式。
真正重要的指标,是每次被接受的改动的成本——不是花掉的 token,不是尝试过的任务数,也不是调度过的循环数。如果你「被接受改动」的比率低于 50%,你就是在做循环本应替你省下的评审活,而这个循环正在赔本。
12. Ralph Wiggum 循环。悄无声息地失败的那种循环。
工程师 Geoffrey Huntley 记录并命名了这种失败模式。一个本应「只在真正完成时才发出完成标记」的智能体,提前把标记发了出来,于是循环在活儿只做了一半时就退出了。没有硬性闸门,循环会悄无声息地失败,并继续烧钱。
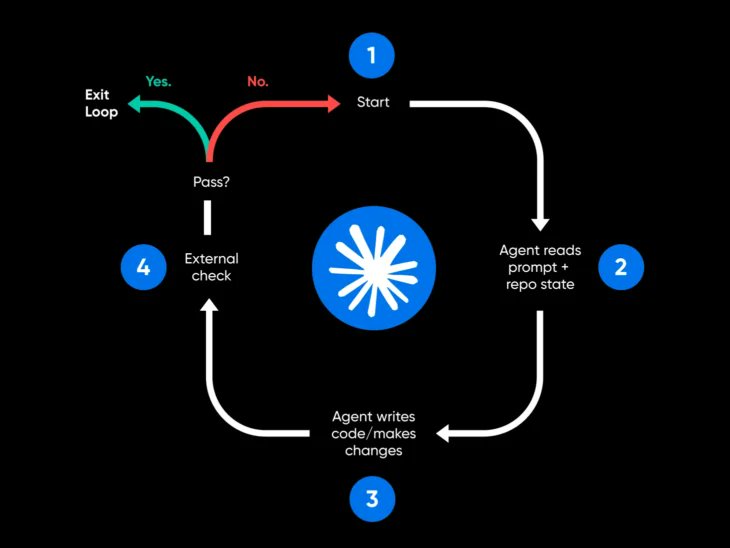
Ralph Wiggum 循环,是以下情况发生时的产物:
- 没有真正的验证器。 只有一个被要求「评审」的第二智能体,没有客观信号。两个乐观主义者互相点头。
- 软性的完成条件。「完成」由智能体的主观判断定义,而非由测试、构建或类型检查定义。
- 没有硬性停止。 循环一直跑,直到某个外部东西把它杀掉(限流、你注意到了),而不是跑到成功被验证为止。
修复办法就是第 11 步里那道闸门——某个能把工作判败的客观东西。一个或过或败的测试。一次或能或不能编译的构建。一个返回零或非零的 linter。而不是一个「有自己看法」的验证器。
其他值得了解的、已被测量到的失败模式:
- 长会话里的目标漂移。 每一步摘要都有损;「别做 X」这类约束会在第 47 轮悄然消失。缓解办法:一份长期存在、每轮重读的 VISION.md 或 AGENTS.md。
- 自我偏好偏差。 写代码的智能体,给自己的作业打分时太手软。缓解办法:一个独立的验证器子智能体,完全不接触生成者的推理过程。
- 智能体偷懒。 循环在部分完成时就宣布「够好了」。缓解办法:用 /goal,配一个由全新模型检查的客观停止条件。
13. 理解债与认知缴械。
这是一种循环越好、它就越尖锐(而非越缓和)的失败模式。两个有名字的风险,都出自 Osmani 的文章:
- 理解债(comprehension debt)。 循环交付「你没亲手写的代码」越快,「仓库里装着什么」与「你理解了什么」之间的距离就越大。真正让你疼的账单不是 token 账单。而是某一天,你不得不去调试一个团队里没人读过的系统。
- 认知缴械(cognitive surrender)。 那种「干脆不再形成自己的看法、循环返回什么就照单全收」的拉力。设计循环,当你带着判断力去做时是解药,当你为了逃避思考去做时是加速剂。同一个动作,相反的结果。
缓解办法不是技术性的:
- 读 diff。 如果你不读循环交付的东西,你就是在以复利借入理解债。
- 抽查闸门。 挑几个循环开过的 PR,验证那个批准它们的测试,是否真的能抓住你在意的那种失败模式。闸门会腐坏。
- 禁止循环碰架构工作。 把它限定在小的、可机器检查的改动上。一旦你让它去碰主观判断,理解债就会加速。
- 和队友结对设计循环。 设计循环时多一双眼睛,能抓住盲点——否则那些盲点会被循环永远利用下去。
14. 安全税。一个无人值守的循环,就是一个无人值守的攻击面。
一个无人值守运行的循环,同时也是一个无人值守运行的攻击面。
你的循环必须防御的威胁模型:
- 生成代码未经评审就上线。 循环开 PR 的速度,比人类读它们的速度快。如果闸门里不包含安全检查(SAST、依赖审计、密钥扫描),不安全的代码就会自动合并。
- 技能作为注入载体。 一个自动安装技能的循环,会继承它们描述里藏着的每一处提示词注入。安装前先审计技能来源。
- 凭据进了日志。 长跑循环期间的调试日志,会把密钥撒进你并不监控的日志里。在生产循环里关闭冗长日志;对确实要记的内容做脱敏。
- 权限范围蔓延。 一个用只读权限测过的循环,为图方便被加上「就这一个」写权限,然后就再没复审过。每 30 天复审一次权限。
§ 把循环变成烧钱无底洞的那些错误
- 没跑四条件测试就搭循环。 第 2 步的存在自有其道理。大多数开发者至少会卡在一个条件上。
- 没有客观闸门。 一个被要求「评审」、却没有测试、类型检查或构建的第二智能体,只是第二个乐观主义者。
- 一个智能体同时干写和验两件事。 自我偏好偏差。生成者给自己的作业打分,永远是「A+」。
- 没有状态文件。 明天的运行从零重启,而不是接着上次继续。
- 含糊的停止条件。「看着不错就算完成」永远站不住脚。用一个测试、一遍类型检查,或一次通过的构建。
- 没有 token 预算上限。 循环会反复重读上下文、重试。没有上限,野心勃勃的循环会烧掉你预期 5 到 10 倍的 token。
- 在消费级套餐上跑重度验证循环。 token 账单或限流,总有一个会逮住你。
- 自动安装社区技能。 在 17,022 个受审计的技能里,有 520 个会泄露凭据。安装前先读源码。
- 在主观判断类工作上跑循环。 架构、鉴权、支付、含糊的产品决策。让循环留在 lint 修复上,别去碰战略。
- 不读 diff。 以复利计的理解债。某一天你去调试一个没人读过的系统,那代价比所有 token 加起来都高。
结语:
杠杆移动了。你的工作也移动了。
过去两年,与编码智能体协作的杠杆在提示词那里。更好的提示词、更好的上下文、更好的一次成型产出。
那个阶段正在终结。 智能体变得足够好了,于是下一个杠杆点上了一层楼:那个决定「它们做什么、何时做、用什么闸门、以及哪些状态能在运行之间存活」的系统。
但这个故事诚实的版本,并不是说人人都该冲去搭循环。大多数开发者目前还不需要它——除非任务会重复、验证已自动化、预算扛得住浪费,且智能体拥有资深工程师的工具。
缺一个条件,循环的代价就会超过它的回报。
如果你通过了测试,那就搭小的。一个自动化。一个技能。一个状态文件。一道闸门。 先让一次手动运行变得可靠。把它做成技能。用循环把它包起来。然后再调度它。顺序很重要。跳着来,你就是在为一个没人理解的系统买单。
Cherny 的观点,不是说工作变简单了。而是说杠杆点移动了。搭起循环。仍做工程师。