核心思想
把编程智能体的上下文窗口想象成向下增长的栈——只能在栈底入栈或出栈,无法随机访问中间。上下文分叉就是从栈底弹出一条或多条消息,让你在用户消息边界上回退状态。三大用法:纠偏跑偏的智能体、并行探索多个设计方案、撤销污染性的上下文操作。
上下文分叉(context forking)是编程智能体的一项强大基础能力(primitive)——它让你先把高质量的上下文搭起来,然后反复复用。
很多编程智能体(OpenCode、Pi、Claude Code 等等)都支持上下文分叉,只不过叫法不同:回退(rewind)、时间旅行(time traveling)、分支(branching)——本质上都是同一概念的不同变体。
这篇帖子是一份实战指南,教你怎么用上下文分叉省时间、省 token、省钱,外加省下一大堆头疼事。
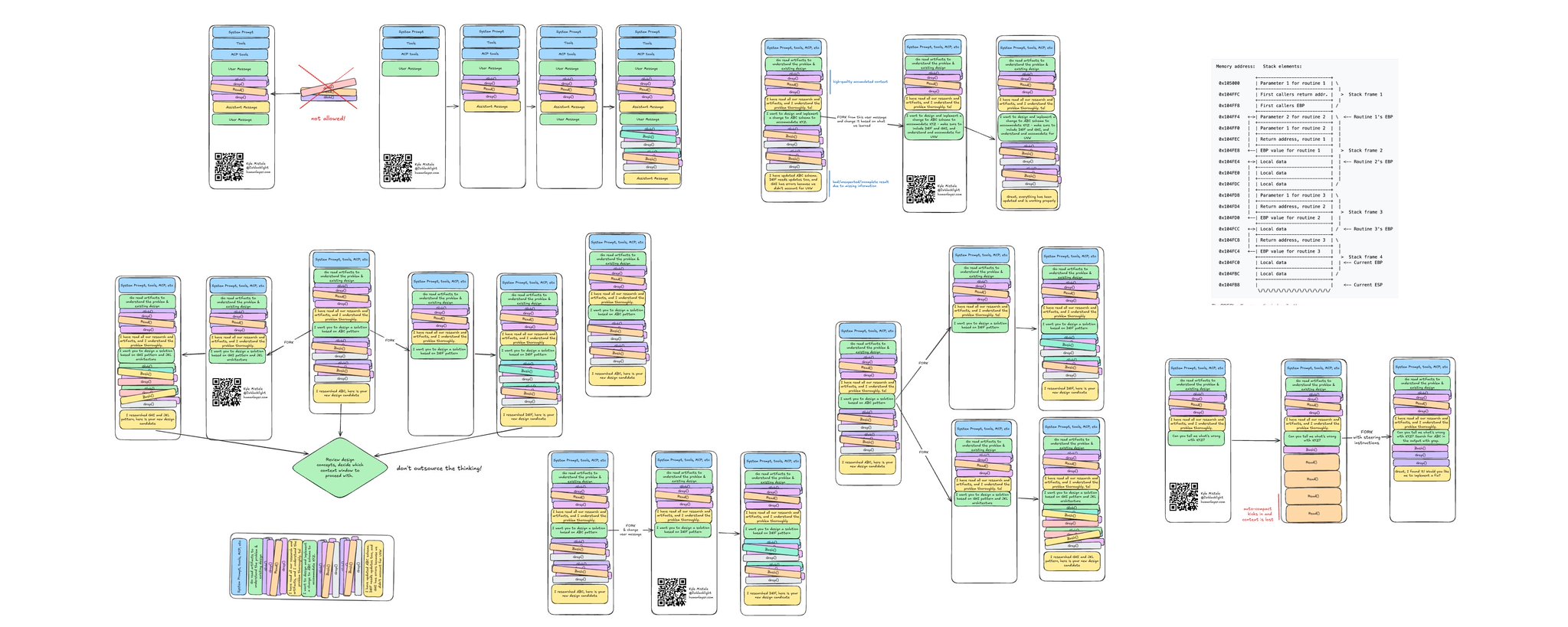
把上下文窗口看作操作系统的栈
我习惯把智能体的上下文窗口理解成 向下增长的栈,灵感来自操作系统里的栈:
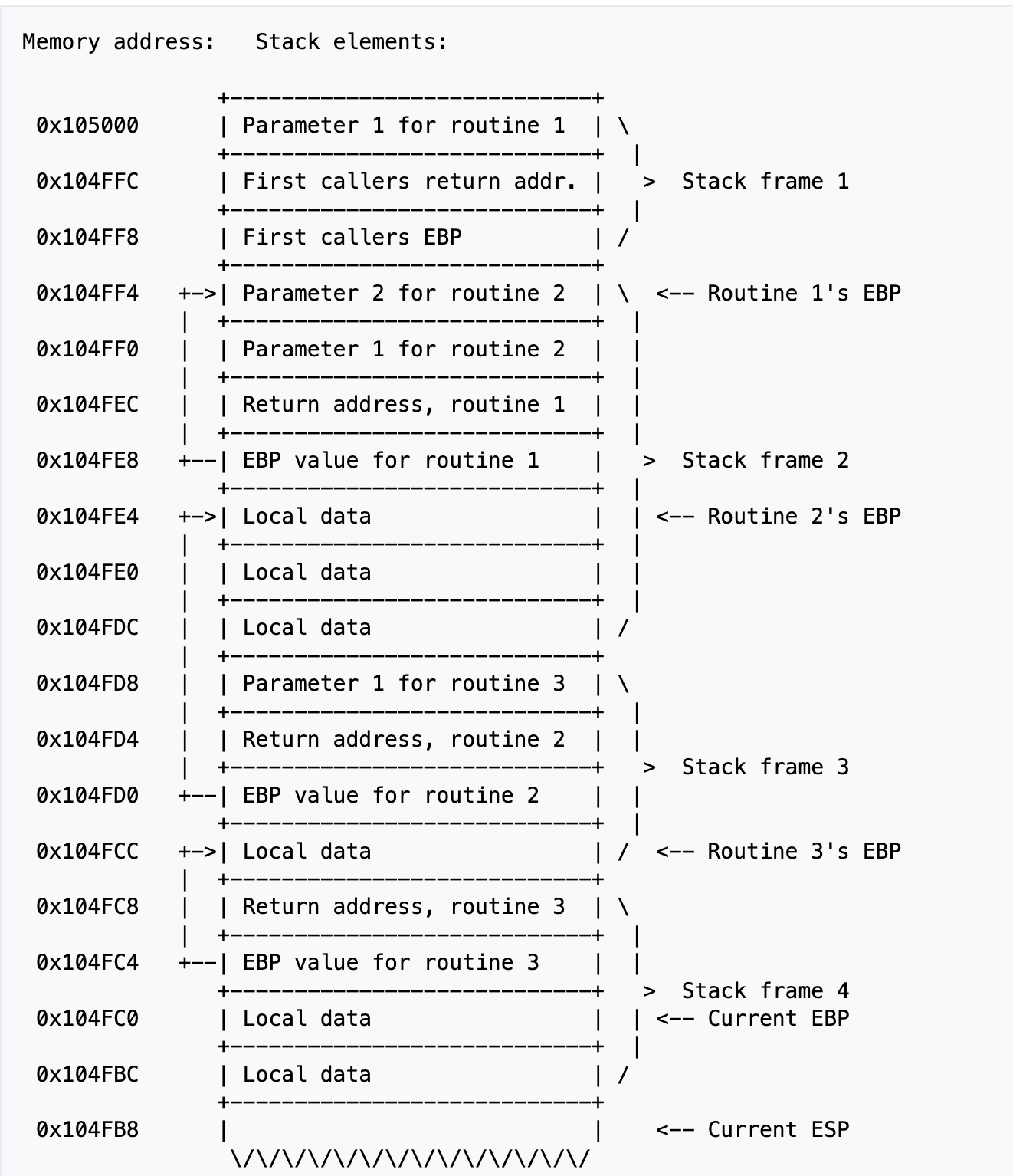
图片来自 https://wiki.osdev.org/Stack
在操作系统的栈里,每调用一个新例程,对应的栈帧就会被追加到栈的底部。上下文窗口也可以这么理解——把每一轮「用户消息—助手消息」看作一个新例程,对应一个新的栈帧:
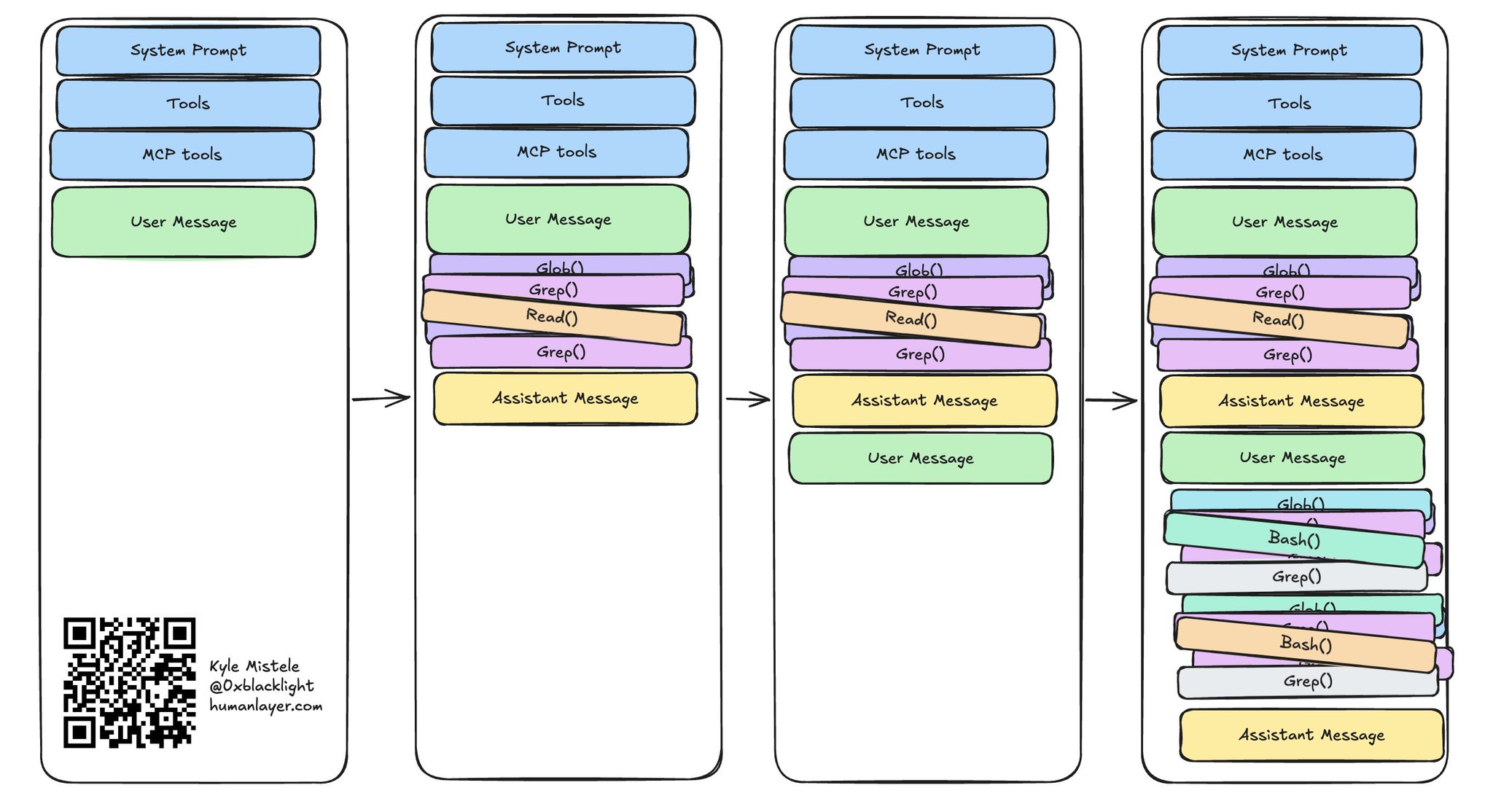
上下文窗口就像一个向下增长的栈
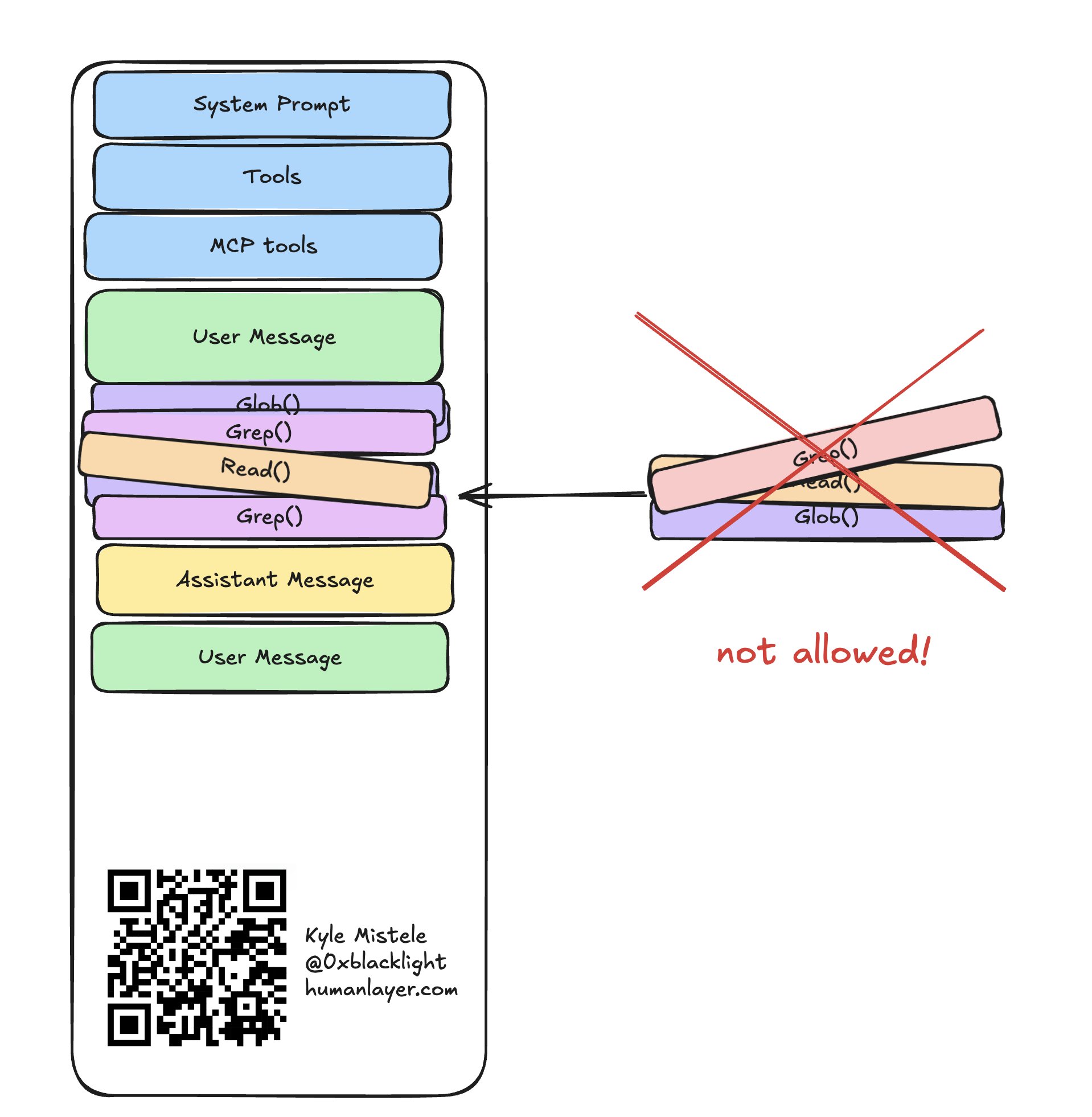
和栈一样,编程智能体的上下文窗口通常 **不允许随机访问**。你可以通过发用户消息把内容 入栈 到末端,也可以从末端 出栈(也就是移除内容)。
但就像操作系统的栈会随着新例程被调用、新栈帧被压入而向下生长,上下文窗口也一样——你只能在历史记录的最新一端入栈或出栈。你被困在末端,只能跟它打交道。
不允许随机访问,有几个原因:
- 会让推理 API 频繁缓存未命中,代价昂贵
- 会破坏已经积累起来的重要上下文
- 会干扰编程智能体的内部状态
大多数编程智能体都有内部状态,用来追踪自己读过、写过哪些文件(以及其他东西)。当智能体试图改某个文件时,这套机制会让 harness 先提示智能体读一遍那个文件,然后才允许它动手改。
如果要往上下文窗口的中间插入或删除工具调用,就得对智能体的上下文以及它的内部状态做外科手术式的改动,而智能体一般都不支持这种操作。
上下文分叉是怎么工作的?
上下文分叉让你能从上下文窗口栈的底部弹出一条或多条消息,把状态恢复到更早的版本。
就像操作系统的栈每次都是按整个栈帧入栈、出栈一样,你通常只能在用户消息回合的边界上回退上下文窗口,没法停在一串工具调用的中间:
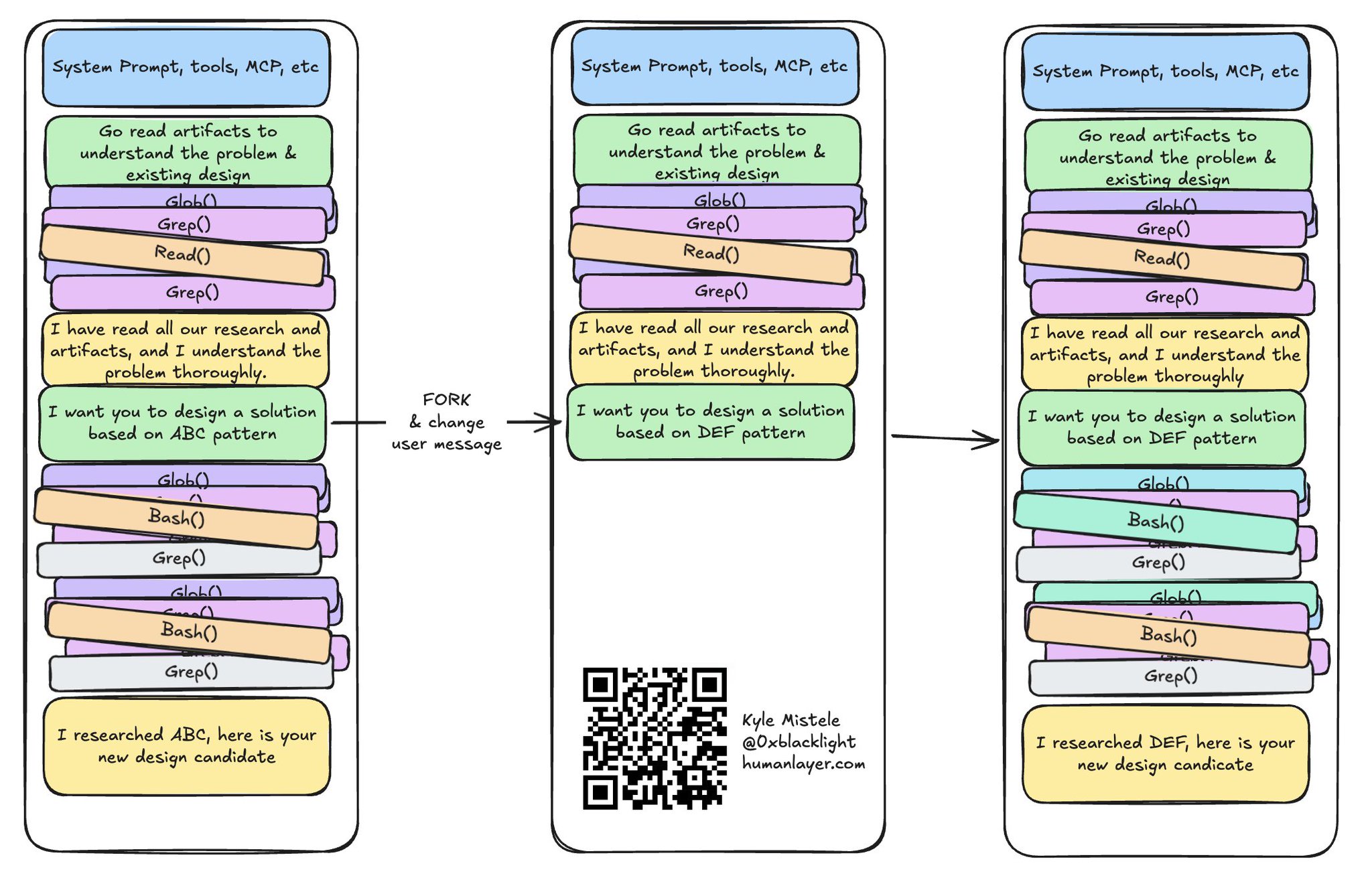
用分叉回退上下文窗口
通常你可以这么干很多次——从同一个上下文窗口出发,以多种不同的方式分叉。
不同智能体在界面和实现细节上各有差异。有些智能体在你回退会话状态时,会同时回退代码和磁盘的状态。另一些则会在你这么做时新开一个分支或 worktree。
什么时候该分叉你的上下文窗口?
回退以纠偏智能体
最常见的用法之一,是在智能体实现某个功能的过程中回退一段会话,把之前漏掉的东西补上:
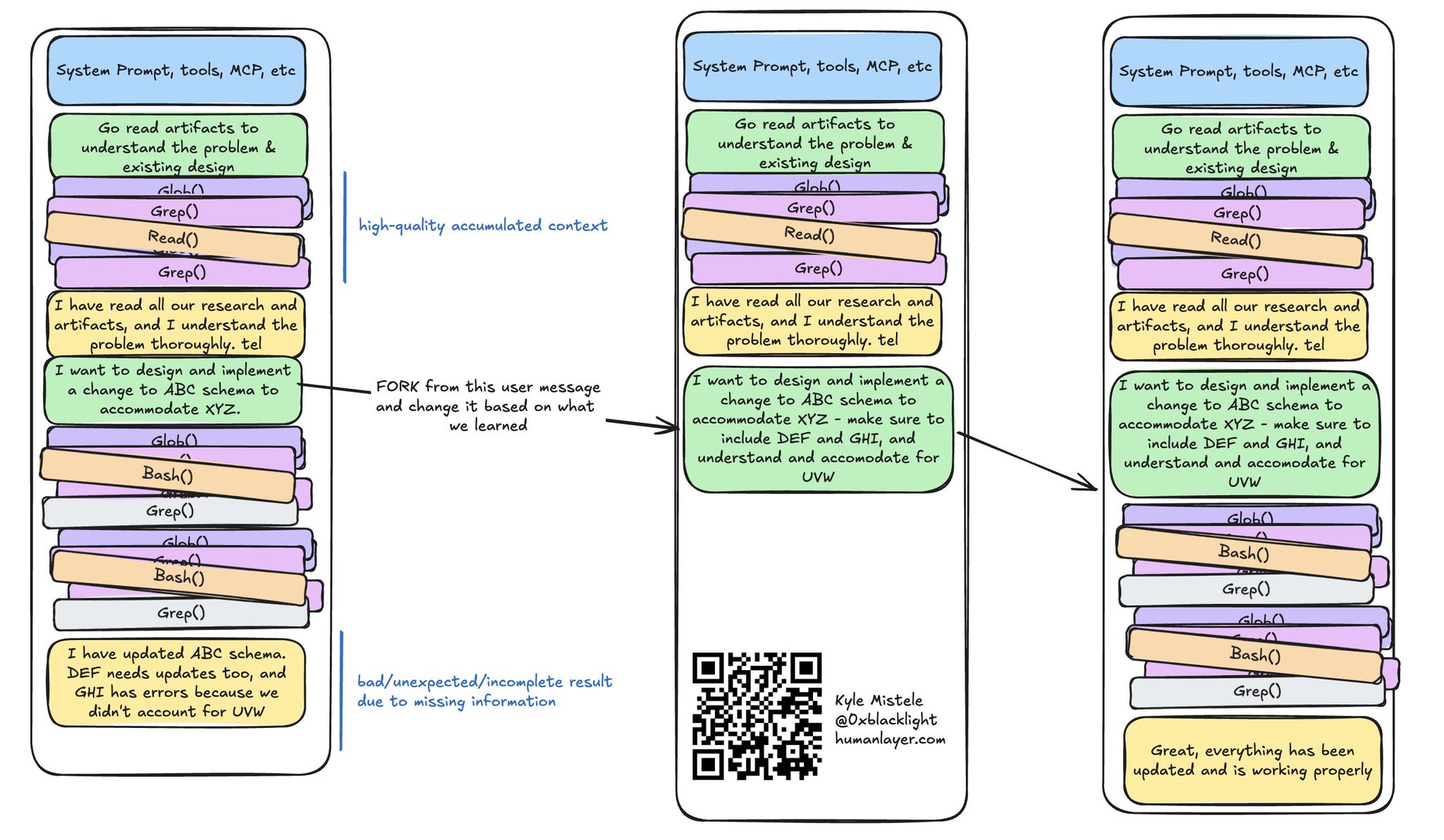
用分叉给智能体纠偏
分叉以探索不同的设计方案
我经常在任务的设计阶段分叉会话。
当我对代码库和要解决的问题已经积累了一批高质量上下文之后,我会分叉这段会话,去探索不同的设计和架构路径。
然后我会看看各自的结果,再决定从哪个会话继续走下去——或者干脆决定还需要更多调研!
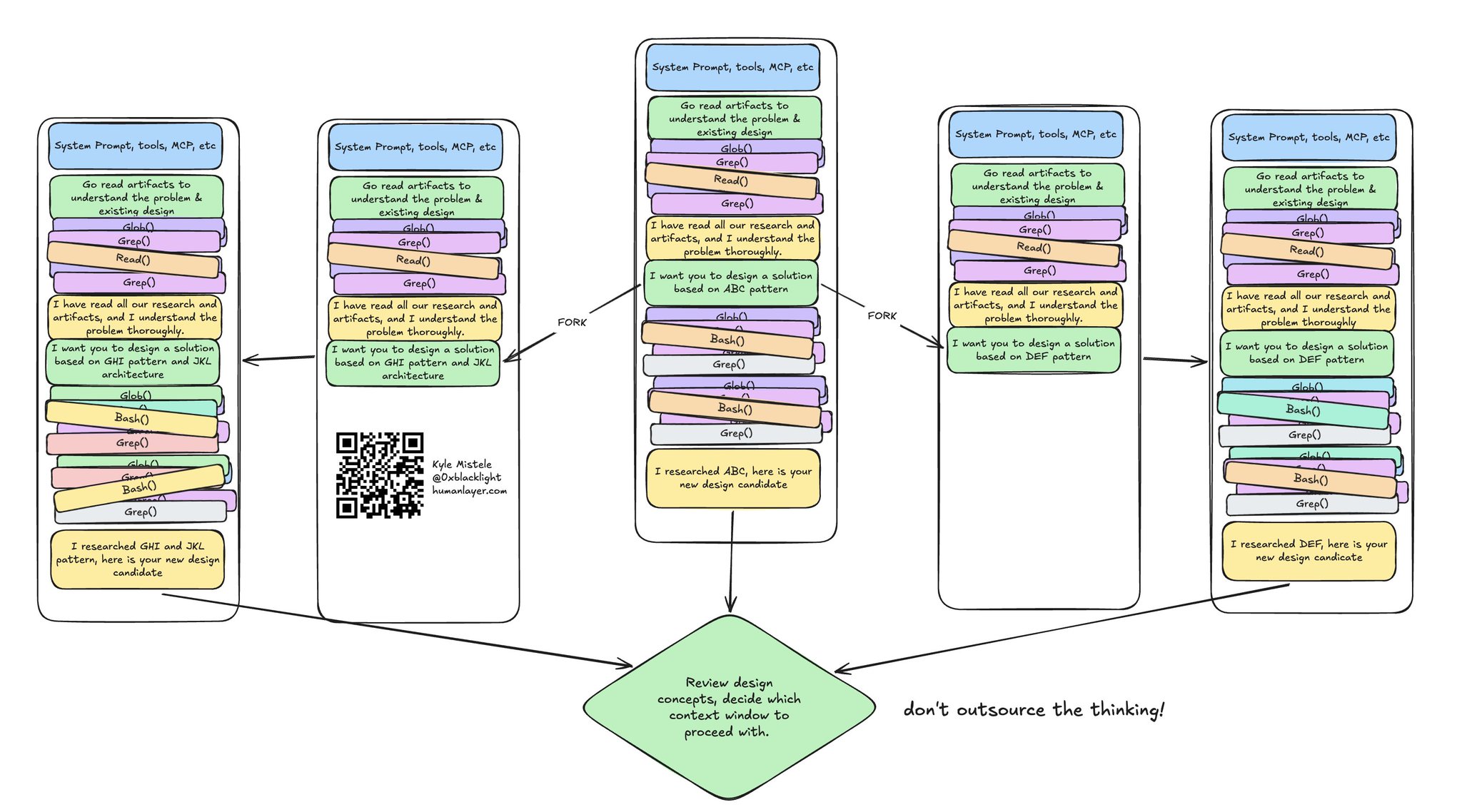
用分叉探索设计方案
分叉以保住上下文窗口,免被低效操作毁掉
分叉还有一个绝妙用途:在智能体做了某些消耗上下文的操作之后,把会话回退回来,保住之前辛苦积累的高质量上下文。
举个例子:智能体读了一个超大的文件,或者跑了一条会吐出一大坨输出(动辄几万 token)的命令。大多数 编程智能体的 harness 都有 hook 或其他保护机制 来防止这种事——把输出写到文件里,只把文件路径给智能体看,让它自己去搜索。但有时候,智能体就是会把 40,000 token 一块一块全读进来,把上下文窗口塞满:
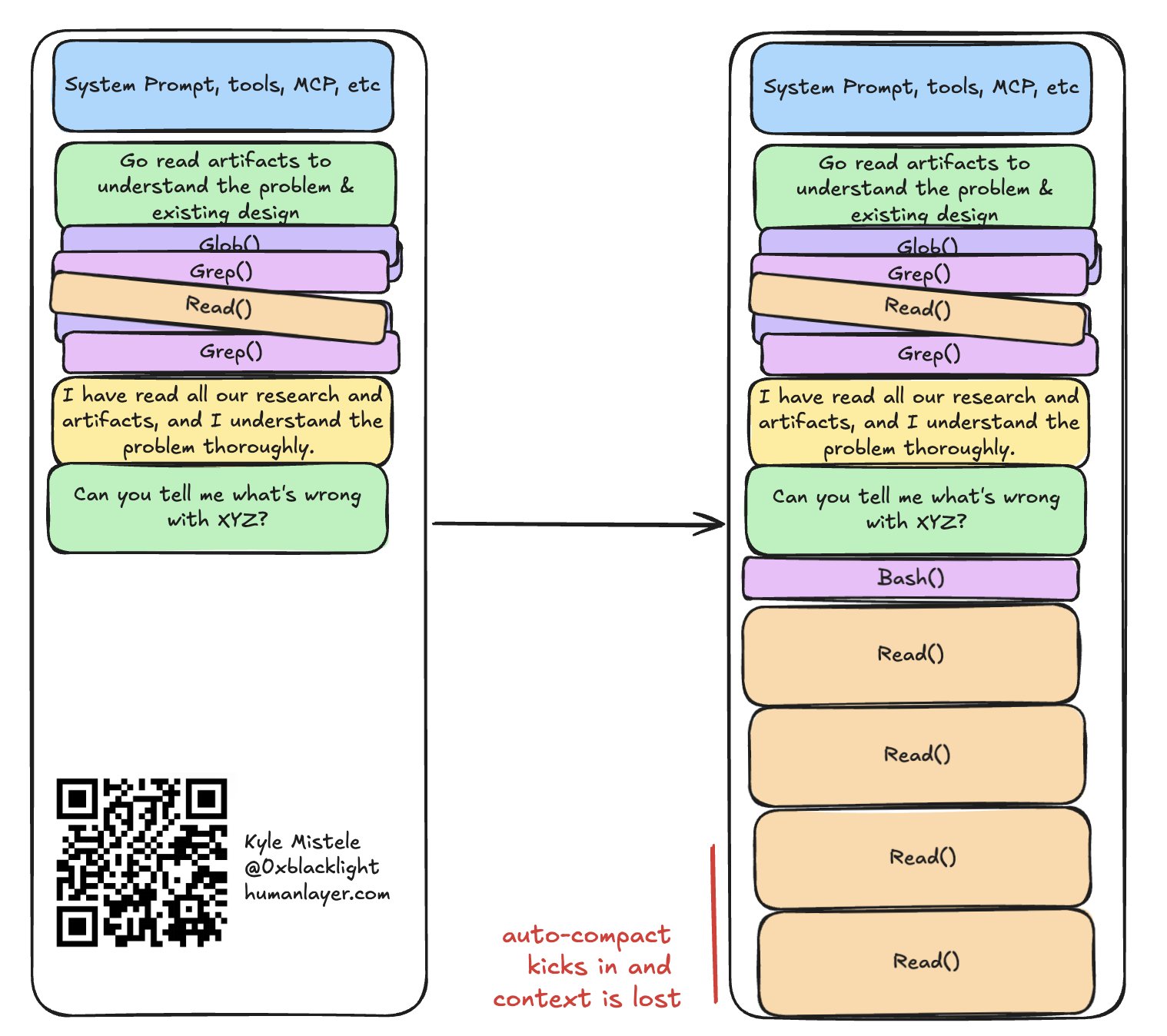
一次昂贵的操作,就能毁掉你的整个上下文窗口
幸好,我们可以用分叉把这段会话救回来!
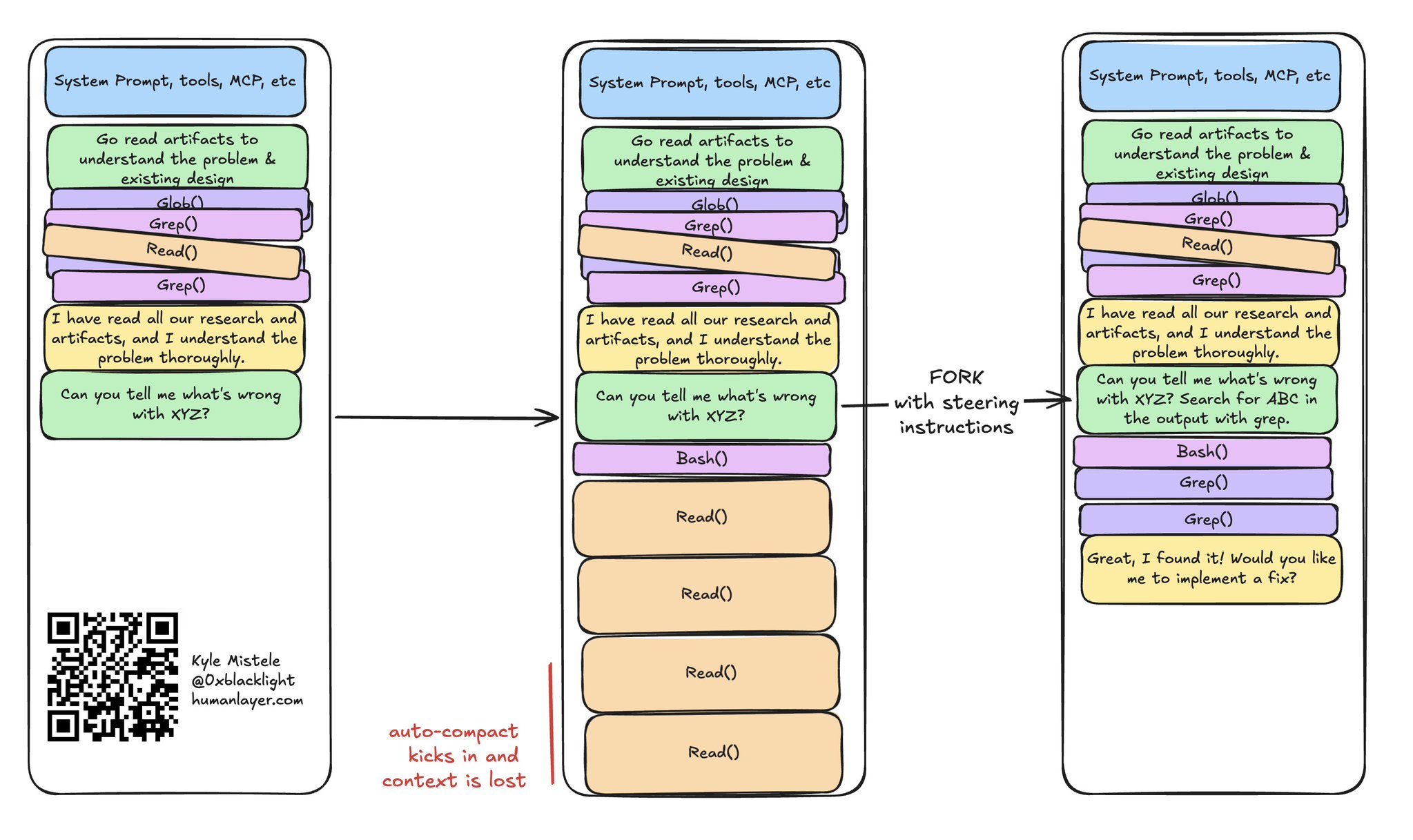
用分叉撤销那些消耗上下文的操作
我们来回顾一下:
- 编程智能体的上下文窗口可以理解为向下增长的栈。你可以从栈底入栈或出栈,但一般动不了栈的中间或顶部
- 上下文分叉可以用来回退上下文窗口,在智能体漏掉某些东西时重新校准方向
- 上下文分叉可以用来分支并探索多种不同的设计或实现路径
- 上下文分叉可以用来恢复上下文窗口,把它拉回到那一坨低质量上下文被塞进来之前的状态
相关笔记
- Claude Code 会话管理与百万上下文 —— 会话边界与上下文压缩的工程实践
- 解剖智能体Harness —— harness 如何调度上下文与状态
- Harness 工程:在智能体优先的世界里驾驭 Codex —— harness 视角下的智能体调度
- AI代理的上下文工程:构建Manus的经验教训 —— 上下文工程的设计原则
- 构建 Claude Code 的经验教训:提示缓存就是一切 —— 缓存与上下文复用的取舍